
Вам когда-нибудь было интересно, как работает ChatGPT? И только почему все говорят о том, насколько могущественной он может стать?
Но давайте простыми словами попробуем объяснить запутанные термины ChatGPT и других больших языковых моделей. Вам не нужно быть компьютерным гением, чтобы полностью понять их, даже трюки Гудини кажутся простыми, если их правильно объяснить😂
ЧТО ТАКОЕ БОЛЬШИЕ ЯЗЫКОВЫЕ МОДЕЛИ?
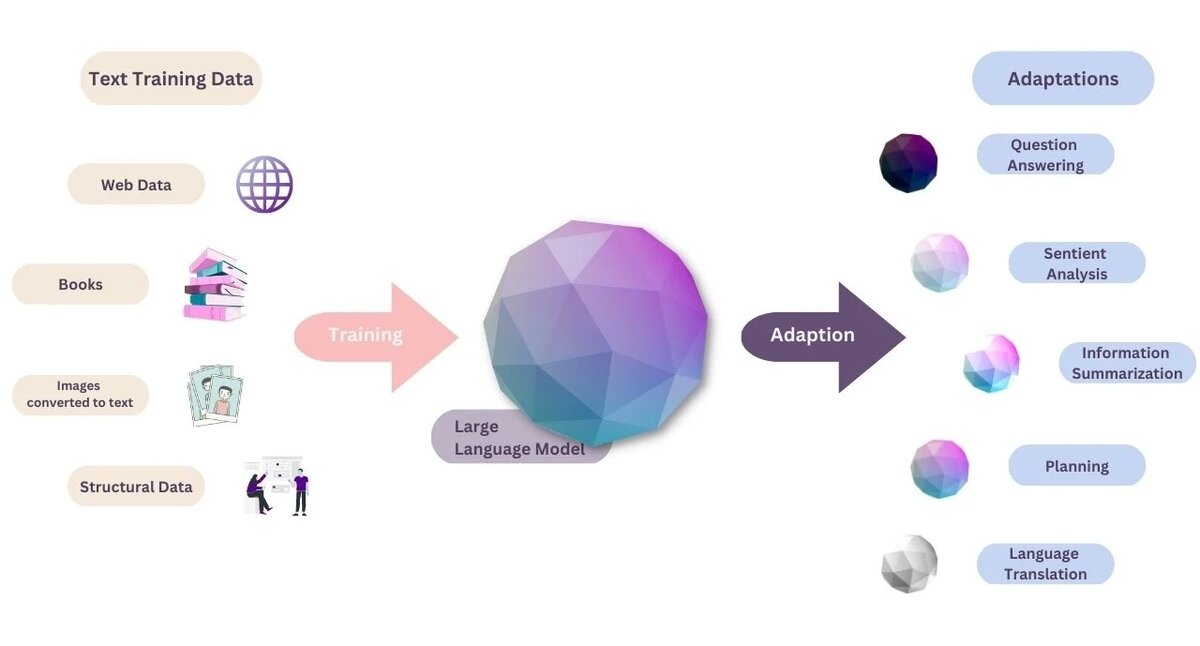
Большие языковые модели (LLM) — это усовершенствованные модели искусственного интеллекта, предназначенные для обработки языка в больших масштабах. Они созданы для того, чтобы принимать подсказку или вопрос (ввод) и использовать полученные знания для получения результата, например ответа или перевода. Их можно использовать различными способами, включая ответы на вопросы, анализ текста, информацию, обобщение, составления кода, планирование и языковой перевод.
Большие языковые модели представляют собой тип базовой модели. Базовые модели — это модели машинного обучения, которые можно настраивать и адаптировать для решения широкого круга других задач. Они обучаются на больших объемах данных (называемых обучающими данными), чтобы дать нам желаемый результат на основе нашего ввода. Базовые модели обучаются особым образом, при этом данные, передаваемые модели, не помечаются, что означает, что модель не знает, на что она смотрит.
Но вернемся к большим языковым моделям и к тому, как они вписываются в общую картину. Базовые модели НЕ являются большими языковыми моделями, но большие языковые модели ЯВЛЯЮТСЯ типом базовой модели, называемой большими языковыми моделями на основе трансформеров (для краткости называемыми трансформерами). У них есть особый способ построения, который называется архитектурой нейронной сети (потому что она напоминает то, как нейроны соединяются в человеческом мозгу).
НЕЙРОННЫЕ СЕТИ
Как упоминалось ранее, большие языковые модели строятся с использованием специальной архитектуры нейронной сети, называемой большими языковыми моделями на основе преобразователей, которая напоминает способ соединения нейронов в человеческом мозгу. Это позволяет LLM прогнозировать и обрабатывать язык с невероятной точностью и скоростью.
ТРАНСФОРМАТОРНАЯ АРХИТЕКТУРА
Большие языковые модели строятся с использованием специальной архитектуры нейронной сети, называемой LLM на основе преобразователя, которая напоминает способ соединения нейронов в человеческом мозгу. Это позволяет языковым моделям лучше понимать естественный язык и обрабатывать язык с невероятной точностью и скоростью
САМОСТОЯТЕЛЬНОЕ ОБУЧЕНИЕ
Эти типы языковых моделей обучаются на огромных объемах данных (называемых обучающими данными) посредством обучения без учителя, что означает, что модель не знает, на что она смотрит. Это обучение позволяет модели научиться точно обрабатывать язык с помощью техники, называемой обучением с самоконтролем.
ТРАНСФЕРНОЕ ОБУЧЕНИЕ
Большие языковые модели также используют трансферное обучение, что означает, что они могут использовать полученные знания из одной задачи, чтобы обучить их выполнению другой задачи. Например, большая языковая модель, обученная переводить с английского на французский, может использовать полученные знания для перевода с английского на испанский.
ХАРАКТЕРИСТИКИ БОЛЬШИХ ЯЗЫКОВЫХ МОДЕЛЕЙ
Являясь подгруппой базовых моделей, большие языковые модели имеют некоторые общие характеристики: они генеративны по своей природе, обучаются с самостоятельным обучением и адаптируются к другим задачам.
LLM могут принимать различные входные данные, но в основном они обучаются на текстовых данных. Некоторые примеры ввода включают необработанный текст (например, сообщения в блогах, новостные статьи и сообщения в социальных сетях), структурированные данные (таблицы, электронные таблицы или базы данных, если данные сначала преобразуются в текст) и изображения (некоторые модели были разработаны для работы с изображениями путем преобразования изображения в текстовое описание).
Большие языковые модели учатся на обучающих данных и впоследствии могут использоваться для создания различных типов текста на основе нашего ввода. Их можно использовать для получения ответов на наши вопросы, краткого изложения нашего текста или даже почасового плана отдыха на выходные.
Другие базовые модели часто меньше и менее сложны, чем большие языковые модели. Обычно их обучают на меньшем наборе данных и у них меньше параметров модели, что ограничивает их возможности. С другой стороны, большие языковые модели намного сложнее и мощнее, хотя бы из-за сотен миллиардов параметров.
Большие языковые модели могут демонстрировать галлюцинации (очень уверенные и странные ответы ИИ, которые просто не соответствуют действительности или оправдываются его ограниченными данными обучения), которые представляют собой возникающее поведение, не ожидаемое и не запланированное во время обучения.
ПРИМЕРЫ БОЛЬШИХ ЯЗЫКОВЫХ МОДЕЛЕЙ
В последние годы мощные LLM стали горячей темой исследований и разработок. Они могут предсказывать следующее слово в предложении, понимать взаимосвязь между словами и идеями, искать определенный контент в зависимости от контекста и многое другое.
Хотя эти модели имеют некоторые ограничения и создают технические проблемы, они предлагают захватывающие возможности для конкретных случаев использования и приложений. Вот почему мы видим, что все больше и больше компаний запускают свои собственные большие языковые модели.
CHATGPT, GPT-3, GPT 3.5 И GPT-4
OpenAI находится на лидирующих позициях в области компьютерных исследований, разрабатывая как самые современные модели ИИ, так и более компактные, эффективные с точки зрения вычислений модели. Словосочетание «большая языковая модель» вошло в обиход и стало популярным благодаря ChatGPT, однако подобные модели существовали уже много лет назад.
Последние исследования и прогресс открывают новые возможности для достижения результатов с помощью больших языковых моделей. Фокус на предварительном обучении больших моделей привел исследователей к открытиям в области обработки естественного языка, позволяя предсказывать следующее слово и ответы, зависящие от контекста.
GPT-3
GPT-3 — это большая языковая модель с архитектурой преобразователя, состоящей из нескольких скрытых слоев, что позволяет очень эффективно обрабатывать текстовые вводы и создавать высококачественные выходные данные. Он предназначен для того, чтобы он мог реагировать на текстовые входные данные, такие как подсказки или вопросы, выводами, подобными человеческим.
Количество параметров модели впечатляет, что делает ее одной из самых больших на сегодняшний день (от 175 до 300 миллиардов параметров, в зависимости от модели). Это делает такие модели очень ресурсоемкими для обучения и тонкой настройки, а также требует высокой вычислительной эффективности.
GPT-3 можно точно настроить (адаптировав модель к новым задачам или областям) с новыми данными для конкретных случаев использования или задач, а также предварительно обучить большие объемы данных, чтобы улучшить его способность понимать и писать текст. Модель показала большие перспективы в различных языковых задачах, включая обобщение текста, понимание контекста и создание ответов.
CHATGPT
ChatGPT — это интерактивный чат-бот , который использует предварительно обученные языковые модели, в том числе GPT-3, для генерации ответов, похожих на человеческие, на вводимые пользователем данные. Модель состоит из нескольких скрытых слоев, которые отвечают за обработку и создание выходных данных модели. Благодаря способности понимать и реагировать на новые данные в контексте, ChatGPT можно точно настроить для конкретных случаев использования или обучить новым данным для обобщения текста, языковых задач и других исследовательских целей.
GPT 3.5
GPT-3.5 — это большая языковая модель ИИ, разработанная OpenAI в качестве тестового запуска и новой улучшенной версии их предыдущей модели. Он построен с использованием той же архитектуры, что и GPT-3, и используется для выявления и исправления любых ошибок, а также для улучшения их теоретических основ. Он продемонстрировал впечатляющую производительность, поскольку способен генерировать человеческие ответы на различные подсказки.
GPT-4
Самая продвинутая система OpenAI, GPT-4 , создает более безопасные и полезные ответы. Последнее творение OpenAI — это большая мультимодальная модель, которая может принимать как изображения, так и текстовые входные данные и выдавать текстовые выходные данные. Хотя в реальных сценариях он менее способный, чем люди, он демонстрирует производительность на уровне человека в различных профессиональных и академических тестах, таких как сдача смоделированного экзамена на адвоката с результатом около 10% лучших участников теста.
BERT
Представления двунаправленного кодировщика от Transformers (BERT) — это семейство языковых моделей, запущенное Google в 2018 году. BERT предварительно обучен двум задачам: языковому моделированию и предсказанию следующего предложения, что позволяет ему изучать скрытые представления слов и предложений в контексте. Он был обучен на большом количестве текстов из книг и Википедии, чтобы узнать, как слова соотносятся друг с другом в предложениях. BERT действительно хорошо понимает естественный язык и используется для поисковых запросов Google на многих языках. Google продолжает улучшать свои LLM и планирует выпустить ИИ-компаньон для поиска Google для всех.
BLOOM
BLOOM — это большая языковая модель, разработанная более чем 1000 исследователями из более чем 70 стран и более чем 250 учреждений. Имея 176 миллиардов параметров, BLOOM может генерировать текст на 46 естественных языках и 13 языках программирования. Это делает ее первой языковой моделью, имеющей более 100 миллиардов параметров для многих языков.
BLOOM был создан, чтобы изменить способ использования больших языковых моделей, облегчив исследователям, отдельным лицам и учреждениям доступ к ним и их изучение. Любой, кто согласен с условиями лицензии Responsible AI License, может использовать BLOOM и развивать его. Возможности BLOOM будут улучшаться по мере проведения дополнительных экспериментов и добавления новых языков.
СПОСОБЫ ИСПОЛЬЗОВАНИЯ БОЛЬШИХ ЯЗЫКОВЫХ МОДЕЛЕЙ
LLM — это мощные инструменты, которые можно использовать в самых разных функциях и приложениях, в том числе упомянутых ниже. Эти приложения стали возможными благодаря способности LLM обрабатывать язык с большой точностью и скоростью, а также их способности решать широкий спектр задач.
ВОПРОС-ОТВЕТ
Одним из самых популярных приложений LLM является ответ на вопрос, в основном из-за популярности ChatGPT. Модели можно научить читать и понимать большой объем текста, а затем давать ответы (выходные данные) на вопросы на основе этого текста. Это делается путем ввода вопроса и предоставления LLM контекстов, таких как отрывок текста или веб-страница. Затем LLM использует полученные знания, чтобы дать ответ на вопрос.
АНАЛИЗ НАСТРОЕНИЙ
Анализ настроений включает в себя анализ эмоционального тона фрагмента текста. Это полезно для предприятий и организаций, которые хотят понять, как их клиенты относятся к их продуктам или услугам, или убедиться, что текст, который они собираются написать клиентам, имеет правильный тон.
LLM могут анализировать большие объемы текста и давать представление о тональности этого текста, позволяя организациям принимать решения на основе данных.
ОБОБЩЕНИЕ ИНФОРМАЦИИ
Обобщение информации включает в себя преобразование большого объема текста в более короткую и лаконичную версию. Это полезно в ситуациях, когда необходимо быстро передать большой объем информации, например, в новостных статьях или отчетах. LLM могут анализировать текст и предоставлять сводку, отражающую основные моменты исходного текста. В настоящее время на рынке существует ряд инструментов для обобщения ИИ .
Мы загрузили в чат огромный документ, с информацией о кошках и попросили написать короткое резюме.
Чат справился на отлично, за считанные секунды.
ПЛАНИРОВАНИЕ
Планирование с помощью LLM включает в себя создание планов на основе набора целей и ограничений. Это полезно в различных приложениях, таких как планирование, логистика и распределение ресурсов. LLM могут анализировать цели и ограничения и создавать планы, отвечающие этим требованиям.
Мы попросили чат: “напиши план питания на 3 дня, для вегетарианца, который не ест перец и авокадо”. И вот, что он нам ответил:
ЯЗЫКОВОЙ ПЕРЕВОД
Языковой перевод с помощью больших языковых моделей может быть полезен для отдельных лиц и организаций, которым необходимо общаться по всему миру и преодолевать языковые барьеры. От заметок о деловых встречах до мгновенного перевода субтитров к видео — LLM могут анализировать текст и предоставлять перевод, отражающий смысл исходного текста.
ВМЕСТО ЗАКЛЮЧЕНИЯ
Большие языковые модели относительно недавно появились в семействе фундаментальных моделей, и тем не менее именно они привели к тому, что искусственный интеллект и его использование вошли в обиход. Вирусная популярность ChatGPT положила начало дискуссии о внедрении искусственного интеллекта в нашу жизнь и работу, в результате чего многие забеспокоились, что могут остаться далеко позади.
Теперь технологические гиганты наперегонки разрабатывают, совершенствуют и продвигают свои собственные модели, внедряя их в продукты, которыми мы пользуемся ежедневно. Преимущества могут быть огромными: невиданный прогресс в здравоохранении, образовании, науке и технике. Однако нам еще предстоит увидеть, насколько подобные модели, а также неизбежная негативная реакция, нормативные акты, исследования и открытия повлияют на наше общество.
Подписывайтесь на наш канал и будьте в курсе самых интересных новостей в мире нейросетей 👇🤖
#chatgpt #нейросети #будущее #интересное