Рассмотрим довольно простую тему организации циклов. Почему я решил это сделать – потому что оказалось, что за привычными, особенно для уже замыленного глаза, вещами может скрываться неожиданное.
Для начала обратимся к основам – как циклы делаются на ассемблере. Я буду использовать диалект x86, хотя это не принципиально.
Итак, задача: Создать цикл, который повторяется 10 раз.
Первый вариант:
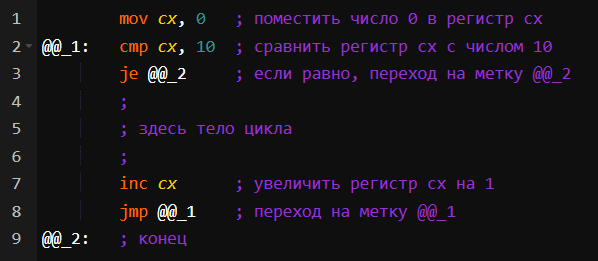
Этот цикл равносилен конструкции:
for (i = 0; i < 10; i++) { ... }
Как видим, здесь сначала i присваивается 0, затем указывается условие повторения цикла (i < 10), затем то, как меняется i (i++ увеличивает i на 1). Те же части цикла и в том же порядке есть в ассемблерном варианте. Данный цикл обладает одной особенностью – он не выполнится ни разу, если условие повторения заведомо невыполнимо.
Также, на каждом шаге цикла i увеличивается на 1 и значит служит не только счётчиком шагов, но и порядковым номером. А этот номер можно использовать, например, для последовательного доступа к элементам массива: a[i].
Второй вариант:
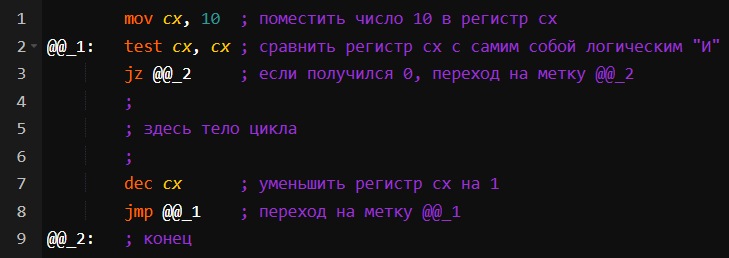
Этот цикл равносилен конструкции:
i = 10;
while (i != 0) { ...; i--; }
Фактически это цикл for, развёрнутый задом наперёд: мы движемся не от 0 к 10, а от 10 к 0, вычитая по единице из счётчика.
Но есть нюанс: в ассемблере используется не команда сравнения с нулём:
cmp cx, 0
а команда неразрушающего логического "И":
test cx, cx
И операция cmp (compare), и операция test дают один и тот же результат, если cx равен 0. При этом один из служебных флагов процессора, который отвечает за нулевой результат операции, устанавливается в активное состояние и следующая команда jz (jump if zero) срабатывает именно на этот флаг.
Почему используется test, а не cmp? Это небольшой лайфхак. В силу устройства процессора операции с регистрами быстрее. А операция test cx, cx использует только регистры. Если устроить cx логическое "И" с самим собой, то результат 0 получится только тогда, когда cx равен 0. Значит, мы получили эквивалент сравнения с 0.
На ассемблере сравнения с 0 делать выгоднее, чем сравнения с другими числами. Следовательно, цикл, который идёт от 10 к 0, более эффективен, чем цикл, который идёт от 0 к 10.
А также любые сравнения в программе, которые можно переделать на сравнения с 0 или "не 0", теоретически более эффективны.
Вышеизложенное будет зависеть от разных факторов, и чтобы заметить разницу, нужно очень сильно постараться. Методы оптимизации, которые существовали для старых процессоров много лет назад, на сегодняшний день могут быть не столь актуальны.
Третий вариант:
Этот цикл равносилен конструкции:
i = 10;
do { ... } while (--i != 0);
Посмотрите, насколько проще стал ассемблерный код. Сейчас в нём вообще нет сравнений и исчезла одна метка. Сразу после уменьшения cx на 1 следует команда jnz (jump if not zero).
Нам не нужно сравнивать cx с 0, потому что флаг нулевого результата активируется не только при сравнениях, но и при арифметических действиях. Следовательно, сразу после dec cx мы можем использовать команду jnz.
Не правда ли, очень просто и эффективно? Данный цикл самый лучший, но за это приходится платить. Ему придётся выполниться хотя бы один раз, даже если условие повторения сразу невыполнимое. В программах, однако, таких циклов бывает предостаточно, так что возможности для их использования есть (хотя насколько заметный эффект это даст, чтобы быть оправданным?)
Также в циклах "задом наперёд" нельзя использовать счётчик как индекс массива. Вернее можно, но тогда массив тоже будет перебираться задом наперёд, что зачастую недопустимо, а если и допустимо, то как правило работает против процессорного кеширования.
Бонус. Четвёртый вариант:
Он аналогичен третьему, только здесь используется специализированная команда loop, которая эквивалентна двум командам:
dec cx
jnz @@_1
Она работает только с регистром cx, и поменять это нельзя. Она процессорно-зависима, поэтому как общий пример я не стал её приводить.
Python, Rust и другие
В таких языках, как C, Java, Javascript мы привыкаем к конструкции цикла, которая у них одинакова:
for (i = 0; i < 10; i++) { ... }
Если после этого начать писать на Python, то мы встретим такой цикл:
for i in range(0, 10): ...
Аналогично в Rust:
for i in 0..10 { ... }
И можем чисто интуитивно решить, что это наш старый добрый for, просто в другом синтаксисе.
И тут нас может ждать неприятный сюрприз. Да, если "ванильно" пользоваться этими циклами, то с виду всё будет хорошо. Переменная i будет проходить от 0 до 9 как обычно, и мы даже сможем использовать её как индекс массива и т.п.
Но если мы попытаемся внутри цикла изменить i...
Постойте, это плохая идея. Не нужно менять в цикле счётчик цикла. Но вообще никто не запрещает нам это делать. В конце концов счётчик это просто переменная, не несущая никакого сакрального смысла, и мы можем ею манипулировать как хотим. Это может быть нужно для организации рекурсии, для неких слияний или удалений элементов массива и т.д.
Но суть тут вот в чём. В "нормальных" языках мы действительно можем поменять значение счётчика и тем самым повлиять на цикл. Например, на JavaScript внутри цикла присвоим переменной i значение 100:
И цикл выполнится всего 1 раз. Присвоив счётчику нужное значение, мы можем спровоцировать досрочный выход из цикла. Либо наоборот, продолжать его бесконечно, пока нам это надо.
Попробуем сделать это на Питоне:
И... цикл выполнится 10 раз. Каждый раз присваивая i = 100:
Пример на Rust приводить не буду, но картина там аналогичная. Что происходит?
Итераторы
Конструкция range(0, 10) в Питоне это вовсе не красивый синтаксис для обёртки классического цикла for. Она создаёт отдельный объект-итератор, который содержит внутри себя числа от 0 до 9. Как именно содержит, в каком виде – от нас скрыто, нам предоставляется только интерфейс к этому итератору.
И цикл, написанный как
for i in range(0, 10)
вовсе не создаёт счётчик i, который увеличивается на 1 на каждом шаге и работает до 9. Вместо этого в i каждый раз попадает очередное число из объекта-итератора.
Чтобы было наглядней, перепишем цикл так:
Становится очевидно, что мы можем получить очередное значение i из итератора, присвоить ему что угодно, но на следующем шаге цикла i снова заменится очередным значением из итератора, и всё, что мы присваивали до этого, будет потеряно.
Настоящий цикл работает внутри итератора, скрытый от нас.
В Rust всё так же, только ещё и менее подозрительно, так как вместо range(0, 10) пишется невинное 0..10. И вывести его на чистую воду можно лишь использовав отдельную переменную iterator:
Конечно, все эти трудности решаются одним способом. Надо просто знать язык, на котором пишешь, и не принимать на веру никакие конструкции, даже если они внешне похожи на те, которые ты уже знаешь из других языков, и работают с виду так же.
Но что с обычными циклами?
Как можно видеть, итераторы это объекты с собственным внутренним устройством и поведением, и следовательно для "ванильных" циклов они слишком громоздкие – что следует уже учитывать.
Чтобы сделать цикл с обычным счётчиком на Python или Rust, нужно воспользоваться while:
В таком виде мы получим классический цикл с переменной-счётчиком, значение которой при желании можно изменить.