Задание 3 требует использования MS Excel (либо же могут использоваться аналогичные редакторы электронных таблиц от OpenOffice или LibreOffice) и согласно спецификации выполняется за 3 минуты.
Для успешного решения третьего задания ЕГЭ нужно не только знать теорию, но и уметь пользоваться редакторами электронных таблиц.
Конкретные функции, облегчающие решение 3-го задания, будут рассмотрены в отдельной статье. В этой же мы познакомимся с теорией.
Для чего используются базы данных
Человек в ходе осуществления своей основной деятельности постоянно сталкивается с необходимостью где-нибудь сохранять до востребования полученную им информацию. Раньше основным средством долговременного и надёжного хранения информации были различные книги и тетради, а теперь их вытесняют информационные системы.
Информация в общем смысле - это какие-либо сведения без определённой формы представления.
Компьютер же устроен так, что он способен работать только с информацией, которую можно закодировать с помощью последовательности единиц и нулей. Для этого информация должна быть представлена в приемлемом для кодирования виде - такая информация называется "данными".
Данные - это информация, представленная в определённом виде. По-другому, данные - это структурированная информация.
Для хранения большого количества информации используются специальные хранилища, работающие по специальным правилам. Эти хранилища называются базами данных.
Реляционные базы данных
В данный момент существует целое множество различных баз данных. Наиболее распространёнными из них являются реляционные.
В реляционных базах данных все данные хранятся в таблицах.
Таблица - это структура, которую действительно можно представлять как самую обычную таблицу со строками и столбцами.
Однако в реляционных базах данных строки называются записями.
Запись - это данные об одном конкретном объекте. Например, если в нашей таблице "Пользователи" хранится информация о всех людях, зарегистрированных на нашем сайте, то одна запись хранит данные об одном конкретном человеке.
Вместо столбцов в реляционных БД существуют "поля".
Поле - это часть записи, имеющее своё имя и тип данных. Например, если мы храним информацию о пользователях сайта, то в таблице могут быть такие поля:
- "Имя" - тип данных "строка".
- "Возраст" - тип данных "целое число".
- "Подтвердил почту" - тип данных "логический".
Проиллюстрирую описанное выше:

Почему база данных является реляционной
Проблема таблиц с большим количеством полей
Чем больше данных нам требуется хранить, тем больше полей появляется в наших таблицах. Часто такой рост таблиц "вширь" приводит к большим проблемам.
Предположим, мы храним информацию о людях, с кем мы работаем. Среди прочих важных сведений, нам важно помнить, кто где живёт. Поэтому мы добавляем в таблицу следующие поля:
- Город - строка, хранящая название города жительства человека.
- Разница по времени - число, описывающее разницу во времени между наших часовым поясом и часовым поясом человека.
- Страна - строка, хранящая страну, в которой живёт наш коллега.
Получится примерно такая таблица:
Сначала нам будет казаться, что всё нормально. При появлении новых коллег, мы будем просто добавлять новые записи в таблицу, аккуратно заполняя информацию, связанную с местом жительства.
Всё будет нормально до тех пор, пока мы не допустим случайную опечатку.
Теперь, когда мы сделаем фильтр, выводящий всех людей, проживающих в Москве, мы не увидим Машу, потому что система будет справедливо считать, что она живёт в другом городе - в Маскве.
Как нам уменьшить шанс появления подобных ошибок? Всё просто - нам нужно просто выносить повторяющиеся данные в отдельные таблицы.
Но для начала нам стоит понять, что такое ключи в реляционных базах данных.
Ключи в таблицах
Задача крайне проста: нам нужно как-то однозначно указывать на нужную нам запись в таблице. Для этого нам нужно каждой записи дать уникальный идентификатор. Поле, описывающее уникальный идентификатор записи, называется первичным ключом таблицы.
Что может быть первичным ключом в рассмотренном нами примере?
Обычно мы привыкли различать людей по именам, но что делать, если у людей одинаковые имена? Тогда мы могли бы смотреть не только на имя, но и на возраст. Но что делать в тех случае, когда записи очень похожи?
Для этого придумали очень простое решение - в качестве первичного ключа используют числовой идентификатор (ID). Посмотрите на таблицу выше и скажите, как зовут человека под номером "2"? Правильно: Пётр.
Обычно в качестве первичных ключей мы используем уникальный номер записи - этот номер называется "суррогатный ключ". Однако, если мы точно знаем, что какое-то поле будет уникально во всех записях (например, уникальный буквенный код), то тогда мы тоже можем использовать его в качестве первичного ключа - это будет естественный первичный ключ.
Ещё раз на примерах:
- Порядковый номер в качестве первичного ключа - это суррогатный ключ.
- Уникальный идентификатор в виде строки - это естественный ключ.
Теперь, когда мы знаем, что такое первичный ключ, мы сможем понять, что такое вторичный ключ.
Всё просто: если мы используем первичный ключ в качестве ссылки на другую таблицу, то этот ключ является вторичным.
Например, предположим, что у нас есть 2 таблицы:
- Таблица с городами. У каждого города есть уникальный номер.
- Таблица с людьми. У каждого человека есть уникальный номер.
Что означает фраза "Человек с ID 3 живёт в городе с ID 5"? Чтобы понять, мы просто найдём запись с первичным ключом "3" в таблице людей и запись с первичным ключом "5" в таблице городов". Вот и связь.
Эта связь называется отношением. А что такое "реляционный"? Это тот, который имеет "отношения". Вот и причина, почему база данных называется реляционной: таблицы связаны друг с другом отношениями.
Строим отношения между таблицами
Вернёмся к рассматриваемому нами примеру. Что мы делаем? Просто превращаем одну таблицу в две: выносим города в отдельную таблицу и связываем её с таблицей учеников с помощью внешнего ключа "номер города".
Теперь скажите, в каком городе живёт ученик с первичным ключом "5"?
Ещё раз, в примере выше:
- Первичные ключи: поле "№" в таблице "Ученики", поле "№" в таблице "Города".
- Внешний ключ: поле "Номер города" в таблице "Ученики".
Схема базы данных
Теперь, когда мы знаем все основы организации реляционных баз данных, мы сможем понять, что такое схема базы данных.
Схема базы данных - это описание таблиц базы данных и связей между ними.
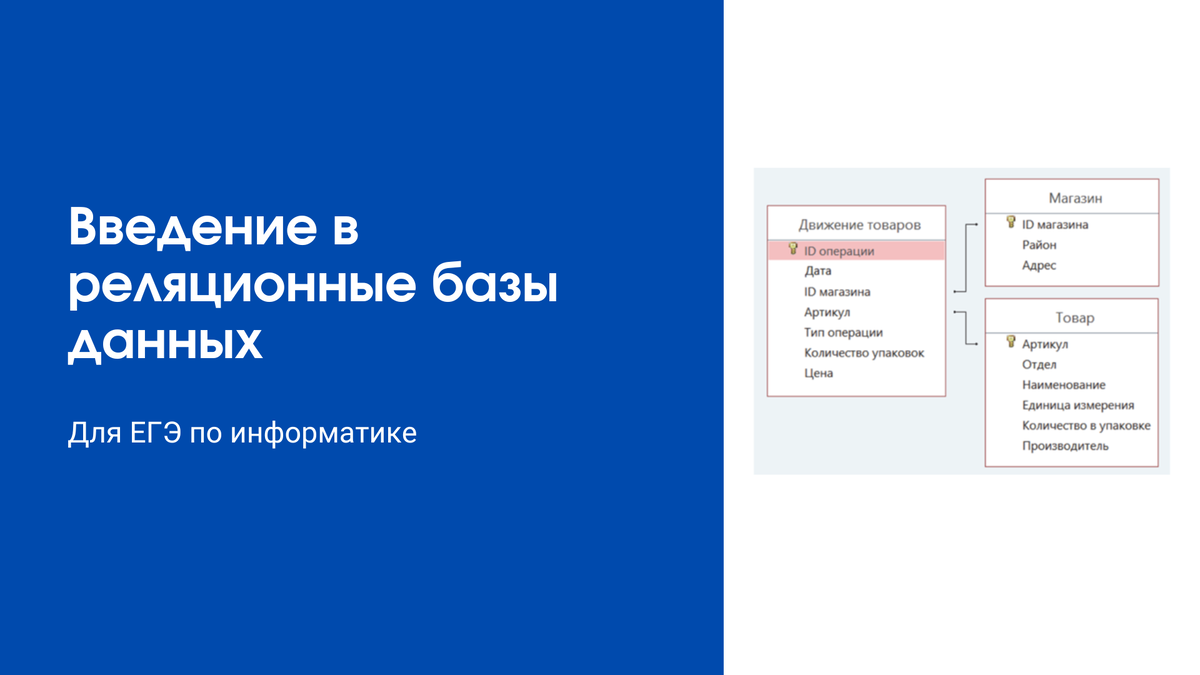
Если посмотреть формулировку 3-го задания в ЕГЭ, мы увидим, что там эта схема тоже есть в упрощённом виде. Вот она:
Теперь, смотря на эту схему, мы можем очень лёгко понять, из чего состоит база данных.
Есть 3 таблицы: "Движение товаров", "Магазин", "Товар". В каждой из таблиц есть свои поля.
В таблицах "Движение товаров" и "Магазин" используются первичные суррогатные ключи. В таблице "Товар" первичный ключ является естественным.
Связи между таблицами тоже ясны. Главной таблицой является "Движение товаров", каждая запись которой ссылается на конкретный магазин и товар.
Эпилог
Реляционные базы данных - это очень мощная технология, которую необходимо изучать подробнее.
Однако в рамках ЕГЭ эта тема затрагивается вскользь. Теории, рассмотренной в данной статье, будет достаточно.
Для лучшего понимания темы рекомендую попытаться разработать собственную схему базы данных с помощью программы MS Access - эта программа не понадобится для подготовки к третьему заданию ЕГЭ по информатике, но позволяет очень просто на практике освоить принципы работы с таблицами и их отношениями.
В одной из следующих статей я рассмотрю решение 3-ей задачи. После прочтения этого материала, проблем не возникнет :3