
Должен сказать, что я был чрезвычайно очарован мощью LLM после появления GitHub Co-pilot и OpenAI ChatGPT. У меня всегда была забавная идея построить очень маленькую языковую модель, которая тренируется на моих разговорах с моей девушкой, надеясь, что она сможет разговаривать с ней, когда меня нет, обманывая ее, что она разговаривает с настоящим мной, по крайней мере, в течение нескольких минут!
Я попытался обучить некоторые модели, используя существующее программное обеспечение для этой цели, результаты были вдохновляющими, но недостаточно хорошими, чтобы обмануть мою девушку! С тех пор мне стало любопытно, как на самом деле работают эти модели, и, как всегда, я попытался изучить их, построив все с нуля.
Когда я говорю «с нуля», я не имею в виду определение модели с использованием библиотеки глубокого обучения, такой как Tensorflow/PyTorch (или даже NumPy!). Я буквально хотел начать с абсолютного нуля, как будто единственное, что я хотел использовать, это операции с плавающей запятой и родную математическую библиотеку Rust. В результате получилась femtoGPT, относительно быстрая библиотека для обучения небольших моделей GPT на ЦП.
Вы можете сказать, что я сумасшедший, но так я понял, как «Multi-headed Attention» работает на самом деле. И были некоторые концепции, которые, как мне казалось, я знал, но оказалось, что это не так. Например, я был уверен, что знаю, как работает уровень нормализации в глубоком обучении, но оказалось, что нет. Оказалось, что я знал, как получить только производную скалярного значения, а не полный тензор. Я также не знал, как вычислить производную многопараметрических функций, таких как Softmax, пока не узнал о матрицах Якобиана. Построение модели прогнозирования текста с нуля значительно улучшило мои навыки и понимание глубокого обучения в целом.
Вот что я сделал в этом путешествии:
- Сначала я увидел видео Андрея Карпатия о тренировке небольшой GPT-модели с использованием PyTorch: https://www.youtube.com/watch?v=kCc8FmEb1nY
- Тогда я подумал, что он также записывает видео о том, как работают нейросети и вычислительные графики в целом и некоторые из них: https://www.youtube.com/watch?v=VMj-3S1tku0
- Я попытался реализовать похожий дифференциатор вычислительного графа, как у Андрея в Rust, с той разницей, что он способен вычислять градиенты тензоров вместо одиночных скалярных значений.
- Я реализовал точно такую же архитектуру, описанную Андреем, реализовав прямой проход и обратный проход этих функций: Add, MatMul, LayerNorm, Transpose, Mask, Softmax, Relu и, наконец, потерю CrossEntropy.
- Я попробовал обучить модель на текстах. Потери уменьшались, но не так сильно, как следовало бы. У меня было ощущение, что, безусловно, некоторые градиенты неверны.
- Я застрял в вычислении правильных градиентов для функции LayerNorm, которая является важным строительным блоком архитектуры GPT и, вероятно, самым сложным.
- Наконец-то я нашел нечто, называемое методом проверки градиента для отладки правильности градиентов в нейронной сети. По сути, это просто численное вычисление производной, используя определение производной, а затем сравнение ее с градиентом, который вы получаете, используя его прямую формулу!
- Я исправил все ошибки, и сеть, наконец, начала выдавать интересные выходные данные после того, как градиенты стали правильными!
Вот некоторые из интересных результатов, которые мы получили после обучения небольшой модели femtoGPT на наборе данных сообщений Reddit в течение примерно ~ 10 часов на 32-ядерном процессоре:
Основным компонентом языковых моделей GPT является то, что называется Self-Attention. Основная идея механизма «Внимание» очень проста. Пусть модель решает, какие предыдущие слова ему интереснее при прогнозировании следующего слова! Наивным методом при предсказании следующего слова уделяется равное внимание всем предыдущим словам.
Хорошо, достаточно разговоров, посмотрим, как можно использовать femtoGPT в собственном проекте! На самом деле это довольно просто. Просто подготовьте текстовый набор данных в текстовом файле dataset.txt, (Могут быть стихи на вашем языке, Reddit публикации, твиты, Python коды и т.д.) и добавьте femto-gpt = «0.1.0» к вашим зависимостям проекта, и вы готовы!
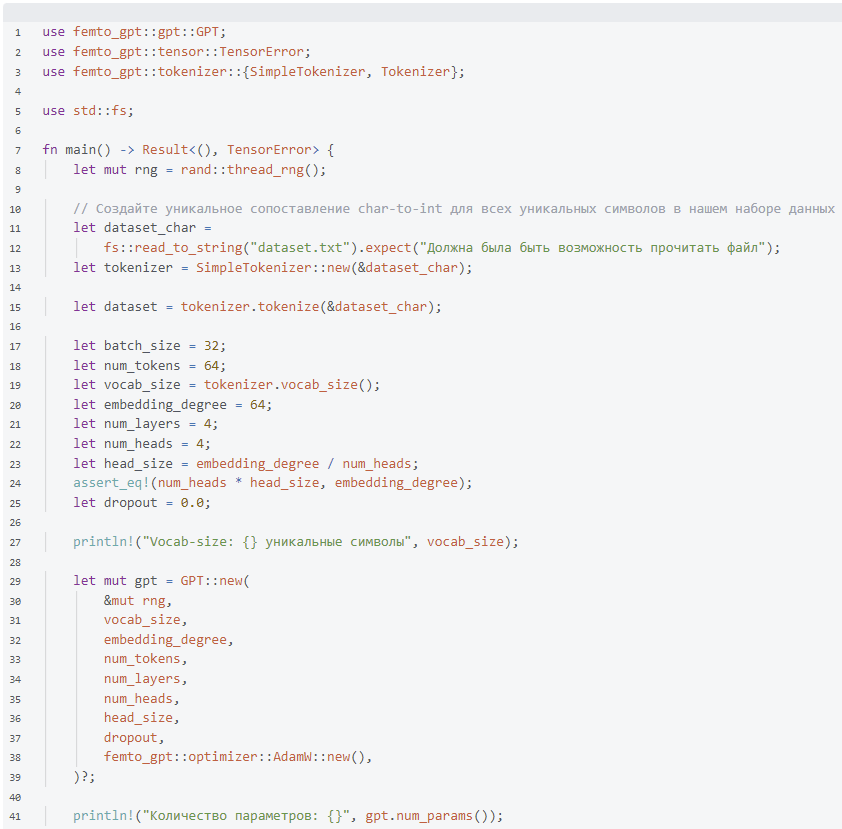
femtoGPT находится в разработке, он, скорее всего, изменится и станет совсем другим в ближайшие несколько месяцев!
Хорошая новость заключается в том, что люди проявили большой интерес к femtoGPT, и я решил продолжить разработку этого проекта как действительно полезного программного обеспечения производственного уровня. Если вы хотите помочь, пожалуйста, не стесняйтесь обращаться ко мне! Вы можете найти мою контактную информацию в моем профиле GitHub: https://github.com/keyvank.
Статья на rusty-code.ru