
В предыдущей статье мы рассмотрели развёртывание стека ELK посредством docker-compose. Сегодня мы рассмотрим сбор и отправку логов Kubernetes в вышеупомянутый стек.
С ростом популярности Kubernetes в мире контейнеризации и оркестрации приложений возникает необходимость эффективного сбора, хранения и анализа логов, генерируемых внутри кластера. Логи являются ценным источником информации, позволяющим отслеживать состояние приложений, выявлять проблемы и выполнять анализ производительности.
Одним из распространенных подходов к сбору и анализу логов является использование стека ELK (Elasticsearch, Logstash и Kibana). Этот мощный инструментарий предоставляет возможности для сбора, хранения, обработки и визуализации логов в реальном времени.
В данной статье мы рассмотрим процесс отправки логов Kubernetes кластера в стек ELK, используя интеграцию между Kubernetes и стеком ELK. Мы покажем, как настроить и настроить компоненты стека ELK, чтобы они могли эффективно собирать и обрабатывать логи из различных компонентов Kubernetes, таких как контейнеры, поды и узлы.
Мы также рассмотрим различные подходы к сбору логов в Kubernetes, включая использование библиотек логирования, таких как Fluentd или Filebeat, и настройку правил сбора логов на уровне приложения и инфраструктуры. Мы объясним, как настроить конфигурацию Kubernetes, чтобы отправлять логи в Logstash для дальнейшей обработки и индексации в Elasticsearch, а затем визуализировать и анализировать эти данные с помощью Kibana.
В итоге, отправка логов Kubernetes кластера в стек ELK предоставляет мощный инструментарий для мониторинга, анализа и отладки вашего приложения и инфраструктуры Kubernetes. Следуя шагам и рекомендациям, представленным в этой статье, вы сможете создать эффективный процесс сбора и анализа логов в вашем Kubernetes кластере, повышая уровень наблюдаемости и улучшая производительность вашего приложения.
Отправка логов кластера K8S в ELK будет осуществляться посредством сборщика fluentd.
Fluentd - это популярная открытая платформа сбора и агрегации логов, разработанная для обработки и доставки данных логирования в различные системы хранения и анализа. Он предоставляет унифицированный подход к сбору логов из различных источников и пересылке их в централизованное хранилище.
Для того, чтобы отослать логи кластера нужно лишь установить Fluentd DaemonSet, предварительно изменив конфигурацию по умолчанию.
Обо всём по порядку.
Шаг 1:
склонируем репозиторий, содержащий в себе официальные конфигурации деплоя fluentd в K8s:
git clone https://github.com/fluent/fluentd-kubernetes-daemonset.git
Шаг 2:
Переходим в папку склонированного репозитория и открываем файл fluentd-daemonset-elasticsearch-rbac.yaml. В блоке fluentd следует указать host и port, на котором находится elasticsearch, чуть ниже - username и password.
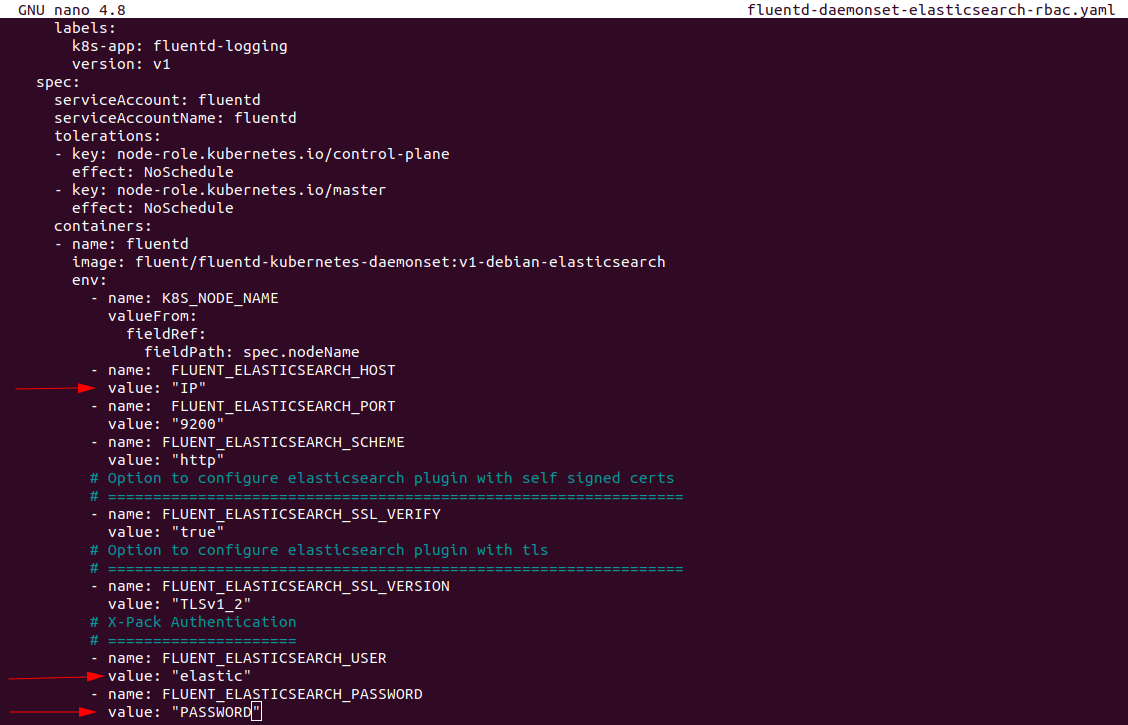
Далее нужно понять, какие логи нужно собирать с кластера. По умолчанию в файле конфигурации fluentd будет собирать логи с этой директории /var/log/pods. Нам же нужны были логи контейнеров (по умолчанию volumeMounts и volumes для контейнеров закомментированы). Конфигурация файла для сбора логов контейнеров выглядит вот так:
В данном шаге мы закомментировали логи подов, и расскоментировали логи контейнеров.
Шаг 3:
Далее следует задеплоить fluentd в наш кластер Kubernetes для дальнейшего сбора логов. Скопируем файл Kubeconfig в папку репозитория (папку, где сейчас находится fluentd-daemonset-elasticsearch-rbac.yaml).
Экспортируем KUBECONFIG следующей командой:
export KUBECONFIG=test-rancher.yaml
И задеплоим конфигурацию fluentd в наш кластер, воспользовавшись командой:
kubectl apply -f fluentd-daemonset-elasticsearch-rbac.yaml
Для визуализации K8S будем использовать rancher. Во вкладке DaemonSet можем увидеть, что fluentd был развёрнут и успешно работает.
Шаг 4:
Переходим по адресу, на котором находится Kibana нашего стека ELK. Чтобы отобразить логи, воспользуемся поиском. Нам нужна вкладка Kibana/data-views.
Кликаем на Create data view. Задаём имя папки логов, а в поле index pattern прописывам logstash* .
В поле Timestamp field оставляем @timestamp, после чего сохраняем конфигурацию.
Далее перейдём во вкладку Discover и выберем в качестве отображения, только что созданный data-view test.
Fluentd собрал логи с кластера Kubernetes отправил их в elasticsearch и вывел их в Kibana!
Отправка логов Kubernetes кластера в стек ELK с использованием Fluentd предоставляет мощный инструментарий для сбора, агрегации, хранения и анализа данных логирования в реальном времени. Эта интеграция позволяет эффективно управлять и мониторить логи из различных компонентов Kubernetes, обеспечивая лучшую наблюдаемость и возможность быстрого выявления проблем.
На этом всё. Если у вас есть вопросы или требуется помощь - мы всегда рады помочь!
--------------------
DevOps-инженер
Васькин Вадим
ООО Кодер
Наши группы:
Telegram:
https://t.me/kodepteam
ВКонтакте:
https://vk.com/kodepteam