Созрела задача: получить сведения о компаниях, зарегистрированных в Вологодской области на последние 3 года. Компании должны быть исключительно коммерческими.
Доступ к открытым данным ИФНС России предоставляет на своём сайте:
https://egrul.nalog.ru/index.html. Форма получения - ручная, со вводом каждого запрашиваемого ИНН или ОГРН. Такой формат нам не подходит, в виду того, что займет очень много времени.
Доступ к официальному API налоговой - платный. Бюджет нашей задачи - "ноль рублей". Снова не подходит :)
Активный поиск информации в сети - привел на страницу https://dzen.ru/a/Yjg9moPTCSE1LIuJ
Автор канала -
купил доступ к базе ЕГРЮЛ и организовал API-доступ к ней для всех желающих. Красавчик!
Я выбрал вариант получения JSON с данными по ссылке: https://egrul.itsoft.ru/{ИНН}.json
Требуемые данные:
- ИНН
- Дата присвоения ОГРН
- Полное и сокращенное наименование юридического лица
- ОКОПФ (для фильтрации до организационно-правовой форме)
Требуется также контактный EMAIL организации, которого нет в ЕГРЮЛ, но есть (в большинстве случаев) на сайте РБК Компании:
Ссылка на страницу ЮЛ: https://companies.rbc.ru/search/?query=ИНН_компании
Листинг кода на Python (с #комментариями):
#импортируем нужные библиотеки
import re
import time
import urllib3
import requests
import time
import csv
import datetime
import pytz
from lxml import html
from bs4 import BeautifulSoup
link_org_head = '' #задаём наличие ссылки на страницу ЮЛ в РБК
inn = '' #задаем наличие ИНН
#список ОКОПФ, которые нам подходят, остальные - не нужны:
okopf = ['12200','12247','12267','12300','14000','14100','14153','14154','14155','14200','15300','20109','20110','20111','20112','20115','20116']
#список НЕНУЖНЫХ разделов ОКВЭД, остальные - подходят:
iskl_okved = ['55','58','64','69','68','84','85','86','87','88','90','91','92','93','94','97','98']
#задаём заголовок запроса на сайт РБК.Компании - без него данные не дадут :)
headers_rbc = {
'Authority' : 'companies.rbc.ru',
'Method' : 'GET',
'Path' : f"{link_org_head}",
'Scheme' : 'https',
'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding' : 'gzip,deflate,br',
'Accept-Language' : 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7',
'Cookie': 'splituid=UET9B2QwD+Q2r+4BBY5MAg==; _ga=GA1.2.12832177.1680871397; _ym_uid=1680871397978041325; _ym_d=1680871397; __rmid=x7Tw3K49Rz63tLid1CPv4g; _gid=GA1.2.1658767539.1687766208; _ym_isad=2; __rmsid=iuDUwbZDShG6ggbFmcFDFw; _ym_visorc=w; csrftoken=KYFNwAcMr1cEAaYk6U0k8f0vAgum5UesobAzzz34EKfL6wZnb2EmKxK1zPV2qpVi; __rfabu=0; _gat_RBC=1; tmr_lvid=c65b443a99645868e46ca8b363b8ed7e; tmr_lvidTS=1687849892287; tmr_detect=0%7C1687849894655',
'Sec-Ch-Ua' : '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
'Sec-Ch-Ua-Mobile' : '?0',
'Sec-Ch-Ua-Platform' : '"Linux"',
'Sec-Fetch-Dest' : 'document',
'Sec-Fetch-Mode' : 'navigate',
'Sec-Fetch-Site' : 'none',
'Sec-Fetch-User' : '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
#задаём заголовок запроса на сайт https://egrul.itsoft.ru/
headers = {
'Accept-encoding': 'gzip'
}
#ищем последние зарегистрированные ИНН на сайте РБК по ссылке: с фильтром "Возраст компании" = "менее 3 лет"
#эмпирическим путем устанавливаем начальный ИНН для поиска по каждому району области:
inn_che = 3528310623 #город Череповец
zip_che = range(inn_che, inn_che + 5000) #задаем диапазон в количестве 5000 ИНН от начального (для городов)
inn_vol = 3525452000 #город Вологда
zip_vol = (inn_vol, inn_vol + 5000)
inn_sok = 3527024919 #Сокольский район
zip_sok = range(inn_sok, inn_sok + 2000) #задаем диапазон в количестве 2000 ИНН от начального (для районов)
inn_bel = 3503006000 #Белозерский район
zip_bel = range(inn_bel, inn_bel + 2000)
inn_nyu = 3515005000 #Нюксенский район
zip_nyu = range(inn_nyu, inn_nyu + 2000)
inn_vyt = 3508010036 #Вытегорский район
zip_vyt = range(inn_vyt, inn_vyt + 2000)
inn_she = 3524017000 #Шекснинский район
zip_she = range(inn_she, inn_she + 2000)
inn_har = 3521004000 #Харовский район
zip_har = range(inn_har, inn_har + 2000)
inn_chr = 3523020000 #Сокольский район
zip_chr = range(inn_chr, inn_chr + 5000)
inn_vor = 3507310000 #Вологдский район
zip_vor = range(inn_vor, inn_vor + 5000)
inn_usg = 3523023000 #Великоустюгский район
zip_usg = range(inn_usg, inn_usg + 2000)
inn_kdy = 3510010000 #Кадуйский район и т.д.
zip_kdy = range(inn_kdy, inn_kdy + 2000)
inn_bab = 3502006000
zip_bab = range(inn_bab, inn_bab + 2000)
inn_vus = 3526021010
zip_vus = range(inn_vus, inn_vus + 3000)
inn_nik = 3514004000
zip_nik = range(inn_nik, inn_nik + 2000)
inn_szh = 3516004000
zip_szh = range(inn_szh, inn_szh + 2000)
inn_vaz = 3505007000
zip_vaz = range(inn_vaz, inn_vaz + 2000)
inn_tot = 3518004000
zip_tot = range(inn_tot, inn_tot + 2000)
inn_grz = 3509004000
zip_grz = range(inn_grz, inn_grz + 2000)
inn_vsk = 3504030000
zip_vsk = range(inn_vsk, inn_vsk + 2000)
inn_vzh = 3506004000
zip_vzh = range(inn_vzh, inn_vzh + 2000)
inn_bbu = 3502006000
zip_bbu = range(inn_bbu, inn_bbu + 2000)
inn_kgr = 3512002000
zip_kgr = range(inn_kgr, inn_kgr + 2000)
#объединяем все ИНН в один список
all_list = list(zip_che)+list(zip_vol)+list(zip_sok)+list(zip_bel)+list(zip_nyu)+list(zip_vyt)+list(zip_she)+list(zip_har)+list(zip_chr)+list(zip_vor)+list(zip_usg)+list(zip_kdy)+list(zip_bab)+list(zip_vus)+list(zip_nik)+list(zip_szh)+list(zip_vaz)+list(zip_tot)+list(zip_grz)+list(zip_vzh)+list(zip_vsk)+list(zip_bbu)+list(zip_kgr)
#функция создания ЛИДа в ESPOCRM (опишу в отдельной публикации)
def create_lead_espo(data_dict):
api = ''
header = {
'X-Api-Key': '',
'Content-Type': 'application/json',
'Accept': 'application/json'
}
url = 'https://api/v1/LeadCapture/'
url_c = f'{url}{api}'
data = data_dict
res = requests.post(url_c, data=data)
if res.text == 'true':
print(f'Лид создан:{res.text}')
return 'lead create'
else:
print(f'Лид НЕ создан:{res.__dict__}')
return 'lead not create'
#Функция сбора и анализа требуемых данных
def parse_info():
ch = 1 #счетчик
data_dict = {} #словарь требуемых данных
for inn in all_list: #начинаем перебор ИНН из списка ALL_LIST
org_email = '' #задаем наличие строки EMAIL
url = f'https://egrul.itsoft.ru/{str(inn)}.json' #шаблон ссылки на запрос, в которую подставляется строковое значение ИНН (не число, как задано изначально)
result = requests.get(url) #делаем GET-запрос
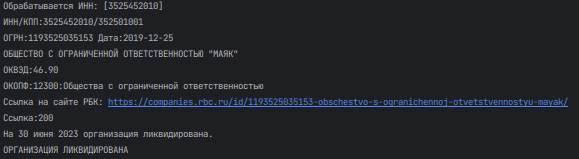
print(f'Обрабатывается ИНН: [{inn}]') #выводим на экран обрабатываемый ИНН
if result.status_code == 200 and result.text != 'false': #обрабатываем условия возникновения ошибок
a = result.json() #извлекаем JSON из ответа сервера
try: #"ЕСЛИ НЕТ ОШИБОК", все переменные и ключи присутствуют в ответе сервера
print(f"ИНН/КПП:{str(inn)}/{a['СвЮЛ']['@attributes']['КПП']}") #выводим ИНН/КПП из ответа сервера
print(f"ОГРН:{a['СвЮЛ']['@attributes']['ОГРН']} Дата:{a['СвЮЛ']['@attributes']['ДатаОГРН']}") #выводим ОРГН и его дату из ответа сервера
print(f"{a['СвЮЛ']['СвНаимЮЛ']['@attributes']['НаимЮЛПолн']}") #выводим Полное наименование ЮЛ из ответа сервера
print(f"ОКВЭД:{a['СвЮЛ']['СвОКВЭД']['СвОКВЭДОсн']['@attributes']['КодОКВЭД']}") #выводим КОД ОКВЭД из ответа сервера
print(f"ОКОПФ:{a['СвЮЛ']['@attributes']['КодОПФ']}:{a['СвЮЛ']['@attributes']['ПолнНаимОПФ']}") #выводим КОД ОКОПФ из ответа сервера
if str(a['СвЮЛ']['СвОКВЭД']['СвОКВЭДОсн']['@attributes']['КодОКВЭД'])[0:2] in iskl_okved: #Сравниваем первые два символа КОДа ОКВЭД со списком исключений [iskl_okved]
print('ОКВЭД не подходит') #Если код в списке
else: #иначе
if str(a['СвЮЛ']['@attributes']['КодОПФ']) in okopf and str(a['СвЮЛ']['@attributes']['КодОПФ']) != '': #Если КОД ОКОПФ в списке [okopf] и не равен пустой строке
url = f"https://companies.rbc.ru/search/?query={str(inn)}" #Ищем ссылку на страницу компании на сайте РБК
response = requests.get(url, headers=headers_rbc) #делаем GET-запрос с обязательным "спецзаголовком" headers_rbc
tree = html.fromstring(response.content) #извлекаем xml-данные из ответа
link_org = tree.xpath('/html/body/div[5]/main/div[2]/a/@href') #находим среди них ссылку на страницу нужной компании
link_org1 = str(link_org).replace("[", "").replace("'", "").replace("]", "")#убираем из строки лишние символы [],
link_org_head = link_org1[24:len(link_org1)] #убираем из строки https://companies.rbc.ru или первые 24 символа
headers_rbc['Path'] = link_org_head #добавляем уразанную строку в ключ "Path" заголовка "headers_rbc" запроса
print(f'Ссылка на сайте РБК: {link_org1}') #выводим всю ссылку на экран
if str(link_org1) != '': #если ссылка не пустая
response1 = requests.get(str(link_org1), headers=headers_rbc)#делаем по ней GET-запрос с тем же спецзаголовком "headers_rbc"
print('Ссылка:'+str(response1.status_code)) #выводим на экран статус ответа, нужен 200, все остальные - неуспешные
if response1.status_code == 200: #если статус-код 200
soup = BeautifulSoup(response1.text, 'html.parser') #парсим данные из ответа
tree = html.fromstring(response1.content) #извлекаем xml-формат
desc = tree.xpath('//*[@id="description"]/p[2]/text()') #находим блок с описанием компании
print(str(desc[-2])) #выводим второй с конца элемент описания
if 'ликвидирована' in str(desc[-2]): #если элемент содержит слово "ликвидирована"
print('ОРГАНИЗАЦИЯ ЛИКВИДИРОВАНА') #выводим информацию на экран, заканчиваем обработку данного ИНН
else: #иначе
print('['+str(ch)+']:')#выводим счетчик успешно обработанных ИНН
links1 = soup.findAll('span', class_='copy-text') #ищем в коде xml все span с классом "copy-text"
for link in links1: #перебираем все найденные span
emails = re.findall("([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)", str(link))# ищем в них Email-адрес по маске [a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+
for email in emails:
org_email = email #присваиваем найденный адрес переменной "org_email"
print(f'Email: {org_email}') #выводим на экран
try: #если все данные без ошибок получены, то формируем словарь data_dict с правильными ["ключами"] для передачи в ESPO CRM
data_dict["accountName"] = str(a['СвЮЛ']['СвНаимЮЛ']['СвНаимЮЛСокр']['@attributes']['НаимСокр'])
except:
data_dict["accountName"] = str(a['СвЮЛ']['СвНаимЮЛ']['@attributes']['НаимЮЛПолн'])
data_dict["emailAddress"] = str(org_email)
data_dict["inn"] = str(inn)
data_dict["oGRN"] = str(a['СвЮЛ']['@attributes']['ОГРН'])
data_dict["dateGRN"] = str(a['СвЮЛ']['@attributes']['ДатаОГРН'])
data_dict["oKVED"] = str(a['СвЮЛ']['СвОКВЭД']['СвОКВЭДОсн']['@attributes']['КодОКВЭД'])
data_dict["okopf"] = f"{str(a['СвЮЛ']['@attributes']['КодОПФ'])} {str(a['СвЮЛ']['@attributes']['ПолнНаимОПФ'])}"
data_dict["status"] = "AutoCreate"
data_dict["rBCURL"] = str(link_org1)
data_dict["assignedUserId"] = 1
data_dict["date"] = str(datetime.datetime.now(pytz.timezone('utc')))[:19]
print(data_dict) #выводим словарь на экран
create_lead_espo(data_dict) #передаем сведения в карточку ЛИДа ESPO CRM
time.sleep(3) #делаем паузу
ch = ch+1 #крутим счетчик
else: #обрабатываем исключения и ошибки
org_email = ''
print(f'Email: {org_email}, RBC: нет данных EMAIL')
else:
print('RBC not LINK!')
else:
print(f"ОКОПФ:{a['СвЮЛ']['@attributes']['КодОПФ']} не подходит под условия")
except Exception as e: print(e)
#print('Нет данных в каком-либо блоке!')
else:
print(f'https://egrul.itsoft.ru/ не выдал данных!')
parse_info() #запускаем основную функцию
Уфффф, всем спасибо за внимание, оказывается комментировать листинг программы - даже дольше и утомительнее, чем писать сам код программы!