Недавние новости часто упоминают достижения нейросетевых моделей, таких как ChatGPT, и объясняют, почему они могут угрожать вашей работе. Однако мало кто осознает, как эти модели устроены и что находится в их основе.
Давайте рассмотрим это с простой стороны. ChatGPT можно сравнить с функцией T9 на клавиатуре телефона, но в значительно более продвинутой форме. Оба этих технологии относятся к классу языковых моделей, то есть моделей, которые предсказывают следующее слово на основе имеющегося текста.

В начале 2010-х годов функция T9 на смартфонах стала развиваться, позволяя учитывать контекст, ставить пунктуацию и предлагать следующее возможное слово. Именно здесь возникает аналогия с более сложной версией автозамены.
Как и T9 на клавиатуре, ChatGPT обучается решать простую задачу - предсказывать следующее слово на основе имеющегося текста. Это основа языкового моделирования. Для таких предсказаний моделям необходимо оперировать вероятностями следующих слов. Ведь если бы смартфон предлагал абсолютно случайные слова в автозаполнении при вводе текста, вы, вероятно, были бы разочарованы.
Давайте представим ситуацию, когда ваша жена отправляет вам сообщение: "Что сегодня на ужин?" Вы начинаете отвечать: "Сегодня на ужин я хочу съесть ...". Если ваш смартфон предлагает вам завершить предложение словом "север", это, честно говоря, не будет особенно полезным. Вместо этого вы ожидаете, что смартфон предложит вам более разумные варианты. И если вы сейчас попробуете ввести эту фразу "Сегодня на ужин я хочу съесть ..." и посмотрите, что предложит ваш смартфон, вы, скорее всего, увидите вполне адекватные продолжения, например, "Я хочу съесть торт", "суп" или "шаурму".
Каким образом T9 понимает, какие слова могут следовать с большей вероятностью за вводимым текстом и какие не следует предлагать? Чтобы ответить на этот вопрос, нам нужно погрузиться в основы работы простейших нейронных сетей. Начнем с более простого вопроса:
Откуда нейросети получают вероятности слов?Как мы можем предсказывать зависимость одних вещей от других?
Предположим, мы хотим обучить математическую модель предсказывать вес человека на основе его роста. Как мы подошли бы к этой задаче? В первую очередь, нам нужно собрать данные, на которых будем искать закономерности. Давайте для простоты ограничимся только мужчинами и рассмотрим статистику роста и веса нескольких тысяч мужчин. Мы попытаемся обучить математическую модель найти зависимость между ними. Для наглядности давайте построим график, где по оси X будет отложен рост человека, а по оси Y - его вес.
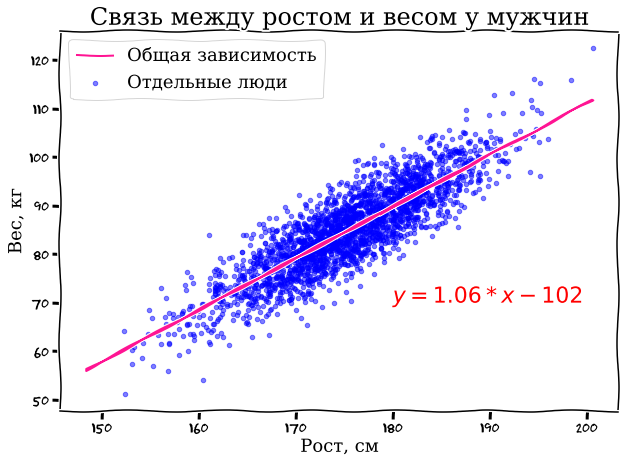
Даже визуально мы можем заметить определенную зависимость: более высокие мужчины обычно весят больше. Эту зависимость можно описать с помощью простого линейного уравнения, такого, как y = kx + b, которое нам всем знакомо с уроков математики. Такая линейная регрессия позволяет выбрать оптимальное уравнение, которое лучше всего описывает зависимость наших данных. Вы можете даже сейчас попробовать подставить свой рост в это уравнение и узнать, предсказывает ли оно ваш вес.Теперь вы, вероятно, задаетесь вопросом:
Что же это имеет отношение к текстовым языковым моделям?
Нейросети, такие как ChatGPT, являются сложными математическими моделями, которые используют набор уравнений, чтобы предсказывать следующее слово на основе введенного текста. Они подобны функции T9 на клавиатуре смартфона, которая автоматически предлагает возможные варианты слов при вводе текста.
Подобно тому, как T9 учитывает контекст и предлагает наиболее вероятные слова, ChatGPT использует вероятности слов, чтобы предсказывать следующее наиболее вероятное слово. Обучение модели заключается в подборе оптимальных коэффициентов для этих уравнений, которые позволят модели точнее предсказывать зависимости в тексте.
Более крупные модели, известные как LLM (Large Language Models), имеют больше параметров и уравнений, что позволяет им генерировать более качественные тексты. Они могут генерировать текст по словам, предсказывая каждое следующее слово на основе предыдущего контекста.
Важно отметить, что нейросетевые модели не всегда предсказывают одно единственное следующее слово. Они могут проявлять вариативность и предлагать разные варианты, подобно творческому процессу человека. Это делает ответы модели более интересными и насыщенными.
В итоге, языковые модели, включая функцию T9 и ChatGPT, представляют собой набор уравнений, обученных на предсказание следующего слова в тексте. Они используют вероятности слов и контекст, чтобы предлагать наиболее вероятные варианты. Более крупные модели могут генерировать связанный текст, предсказывая каждое следующее слово. Вариативность в ответах модели делает ее более похожей на человека.
На текущий момент мы выяснили, что несложные языковые модели применяются в функциях «T9/автозаполнения» смартфонов с начала 2010-х; а сами эти модели представляют собой набор уравнений, натренированных на больших объемах данных предсказывать следующее слово в зависимости от поданного «на вход» исходного текста.
Далее мы узнаем об истории ChatGPT-1, откуда в него загружали информацию и сколько он имеет уравнений в своем алгоритме.
(2010г)