Дисклеймер
Данная статья создана в образовательных целях, материалы взяты с курса "Поколение Python": курс для профессионалов. Сам материал представляет конспект главы данного курса. Материал создан для совместного обсуждения, а также нахождения наилучших вариантов решений задач.
Повторяем основные конструкции языка: Часть 2
Тимур, Артур и новый курс
Задание:
Напишите программу, которая вычисляет минимальное расстояние, которое потребуется пройти Тимуру, чтобы посетить оба магазина и вернуться домой. Тимур всегда стартует из дома. Он должен посетить оба магазина, перемещаясь только по имеющимся трём дорожкам, и вернуться назад домой. При этом его совершенно не смутит, если ему придётся посетить один и тот же магазин или пройти по одной и той же дорожке более одного раза. Единственная его задача — минимизировать суммарное пройденное расстояние.
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а не в сложности решения.
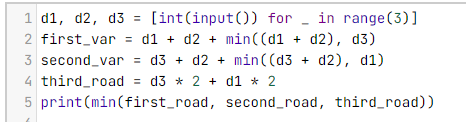
В первой строке считываем входные данные. Важно заметить что так считать можно только данные, которые подаются на отдельных строках.
Далее прогнозируем возможные сценарии маршрута. При этом значение обратного пути мы выбираем функцией "min".
Схожие буквы
Задание:
В русском и английском языках есть буквы, которые выглядят одинаково. Вот список английских букв "AaBCcEeHKMOoPpTXxy", а вот их русские аналоги "АаВСсЕеНКМОоРрТХху". Напишите программу, которая для трёх букв из данных списков букв определяет, русские они, английские или и те и другие (смесь русских и английских букв).
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а не в сложности решения.

Первое что приходит в голову это подобный код. Есть цикл который считывает входные данные, счетчик для букв и не хитрый вывод в виде манипуляций со списком ответов и выражения, которое в свою очередь вызывает нужный вариант. Ноооо, как то громоздко. Да и дважды задействовать цикл не хочется, проблем с памятью не будет при небольшом количестве данных, но что делать если данных будет много?
Немного подумав можно прийти к подобному виду.
Основные изменения лежат во второй строчке. Цикл который ранее только считывал данные, сейчас считывает данные и сразу же проверят их на условие, находится ли данная буква в строке "ru" и возвращает нам True или False, но так как мы используем встроенную функцию "sum", наши True и False превращаются в 1 и 0 соответственно. Тем самым мы получаем такое же значения "счетчика", что и в прошлый раз. В добавок для оптимизации скорости был использован кортеж.
Переворатор
Задание:
Дана последовательность натуральных чисел от 1 до n. Напишите программу, которая сначала располагает в обратном порядке часть элементов этой последовательности от элемента с номером X до элемента с номером Y, а затем от элемента с номером A до элемента с номером B.
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а не в сложности решения. А также в крепком знании срезов.
В первой строке считываем исходные данные, причем следует заметить отличие от задания "Схожие буквы", здесь нам подают одну строку с значениями разделенными пробелом. Поэтому меняется и распаковка.
Для оптимизации кода мы не создаем новые данные, а перезаписываем имеющийся список, а вернее его части.
В первоначальной версии кода я использовал срезы с отрицательным шагом без "reversed", которые аналогично выполняют код.
Более одного
Задание:
Дана последовательность неотрицательных целых чисел. Напишите программу, которая выводит те числа, которые встречаются в данной последовательности более одного раза.
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а не в сложности решения.
Первое что приходит в голову это решения через словарь и словарный метод "get". Тут важно заметить что в 4 строке нам все же придется перевести строку в целочисленное значение, т.к. в дальнейшем нам придется сортировать (3 < 11, но '3' > '11').
Дальше обрабатываем результат по условию из 5 строки и выводим результат. Но получилось громоздко...
Посмотрев на решения преподавателя можно увидеть следующее:
В первой строке аккуратно использовано считывание данных, причем сразу с обработкой данных из строкового типа данных в целочисленный (это необходимо чтобы пройти сортировку).
Но дальше начинается магия (для меня). Обратим внимание на "filter". Само использование встроенной функции "filter" не вызывает вопросов в данной задачи, так как есть условие проверки для нашего списка. Но вот как он работает, стоит объяснить для таких как я.
Обратим внимание на первую часть, работу анонимной функции. Лямбда принимает один элемент по которому происходит итерация "word", далее методом списков "count" мы считаем количество повторений в СПИСКЕ "numbers" и проверяем на условие True или False (что и требует функция "filter"), а дальше то, что вызвало больше всего вопросов. Здесь итерируемым объект является МНОЖЕСТВО списка "numbers".
В чем суть, мы образуем множество из списка "numbers" для того чтобы убрать дубликаты, тем самым лямбда принимает на вход меньше элементов и следовательно производит меньше итераций. А "numbers.count(word)" считаем количество слов в СПИСКЕ, а не в множестве. Тем самым подсчет верный, а итераций меньше.
Максимальная группа
Задание:
Дана последовательность натуральных чисел от 1 до n включительно. Напишите программу, которая группирует все числа данной последовательности по сумме их цифр и определяет длину группы, содержащей наибольшее количество чисел.
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а не в сложности решения.
Все по классике. Считываем данные, для удобства преобразуем в строковый тип данных, а дальше...
Изначально была идея решить через словари, но не смог развить идею, поэтому в голову пришло следующее.
В 3 строке я итерируюсь по цифрам каждого числа из списка и слагаю их. Тем самым я получаю список в котором лежат суммы всех чисел.
Следующим я решил посчитать сколько раз какая сумма встречается раз.
А далее просто вывод самой часто встречаемой суммы. Но опять громоздко...
Модернизируем код.
Считывать данные в список не нужно, так как по заданию нам дадут последовательность элементов. Значит мы можем сразу брать число из последовательности и его итерировать! Причем в строке 3 мы можем обойтись без лямбды. Мы просто складируем в "map" целые числа из итерируемой строки "i". А дальше как раз таки подсчет наших сумм через словарь.
Трудности перевода
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а также в знании множеств и их методов.
Задание:
Зачастую переводить сериалы, не теряя изначальный смысл, невозможно, особенно за счет игр слов. Сумасшедший режиссер хочет снять сериал, в котором бы в целях эксперимента задействовал как можно больше языков, чтобы пользоваться красотой каждого из них. Тем не менее если задействовать слишком много языков, то сериал станет непонятен абсолютно всем, поэтому режиссер достает случайных людей на улице и спрашивает их, какие языки они знают, таким образом он будет использовать языки которые знают все из них.
Во второй строке мы создаем список из множеств. На третьей строке мы создаем множество, важно обратить внимание что мы не вызываем функцию множество, а вызываем класс! Разница в том что при вызове функции "set()" мы будем создавать новое множество ИЗ подаваемого в него итерируемого объекта, а в нашем случае мы обращаемся к классу множества "set" и тем самым можем использовать методы множества. Насколько я смог понять если бы мы использовали "set()", то мы создали бы ПУСТОЕ множество с которым проверяли бы каждый подаваемый элемент и на выходе получили бы "set()". В случае использования класса "set" мы берем все распакованные элементы из списка и создаем на основе их новое множество. За распаковку отвечает "*" у "result".
Далее выводим на печать в соответствии с заданием.
Схожие слова
Задание:
Напишите программу, которая находит все схожие слова для заданного слова. Слова называются схожими, если имеют одинаковое количество и расположение гласных букв. При этом сами гласные могут различаться.
Задача не сложная, скорее стоит вопрос в ее оптимизации. В количестве и качестве кода, а также в знании про существовании функции "enumerate".
Изначально создаем строку со всеми гласными.
На второй строке мы итерируемся по введенному слову и если буква гласная, то в список сохраняем её индекс.
Дальше в цикле проделываем так с каждым введенным словом и сравниваем получившиеся результаты. Важно помнить про "enumerate" без него код был на 12 строк и трудно читаем.
Корпоративная почта 🌶️
Задание:
Вам дан список уже занятых ящиков в порядке их выдачи и имена-фамилии новых сотрудников в заранее подготовленном виде (латиницей с символом - между ними). Напишите программу, которая раздает корпоративные ящики новым сотрудникам школы.
Задача сложная из-за второго теста.
В первом цикле принято интересное решение, ввиду того что для обработки данных нам нужна информация только до символа "@", мы распаковываем каждую строку в две переменные, но только нужную часть добавляем в список "names"
Во втором цикле мы вводим слово, далее заводим счетчик с единицы, для того чтобы в дальнейшем не возникало адресов с значением на конце "0".
После чего запускам второй цикл условием которого является наличие нового адреса в старом списке адресов. То есть если такой адрес уже занят. Если это новый адрес, то просто добавляем его в список "names".
В случае когда адрес повторяется мы перезаписываем переменную, удаляя все ее хвостовые числовые значения. Дело в том, если мы не будем удалять хвостовые значения, а просто будем прибавлять все большое и большое значения счетчика, то вместо "ivan-ivanov4" мы получим "ivan-ivanov1234", т.к. это строковый тип данных. Поэтому если в случае добавления единицы, такой адрес все равно занят (то есть name до сих пор in names), мы при следующем проходе цикла удаляем предыдущее числовое значение и добавляем новое значение счетчика и так далее.
Еще нужно обратить внимание что перед печатью отредактированного в ходе цикла "name" нам ОБЯЗАТЕЛЬНО нужно добавить "name" в "names", потому что нам могут подать сразу двух и более тёзок, в таком случае нам нужно тоже это учесть.
Файлы в файле 🌶️🌶️
Задача средней сложности, скорее она объемная. Очень остро стоит вопрос в оптимизации работающего "Франкенштейна".
Задание:
Напишите программу, которая группирует данные файлы по расширению, определяя общий объем файлов каждой группы, и выводит полученные группы файлов, указывая для каждой ее общий объем. Группы должны быть расположены в лексикографическом порядке названий расширений, файлы в группах — в лексикографическом порядке их имен.
Проблемы:
- Очень много мест занимают логические ветвления для перевода единиц измерений (18 строк).
- Много циклов учитывая циклы в лямбда функциях их 5 и +1 вложенный итого 6 циклов.
- По ощущениям есть лишние обработки данных.
Из положительного стоит отметить прием в строке 19, без которого было бы сложно получить формат файла отдельно от имени.
Рассмотрим лучшее решение данной задачи.
После первой строчке понятно, что нам нужно работать с преобразованием чисел, а модуль "math" очень хорошо дружит с математикой...
Рассмотрим первую функцию "get_unit_name" которая принимает один целочисленный аргумент.
В строке 9 сохраняем кортеж из единиц измерений, что важно, расположенных в порядке возрастания.
В строке 10 мы при помощи логарифма из модуля "math" принимаем значение в виде аргумента "size" по основанию 1024. В случае если размер файла будет 1 048 676 или же (1024 * 1024 + 100), то в переменную "pwr" у нас пойдет значение 2 (int, а не float!!!). Так как получившийся результат мы округляем вниз при помощи "math.floor" мы получаем целое число.
Дальше в теле функции мы возвращаем размер файла. Переменную "size" делим на 1024 в степени "pwr". Как это работает - мы получаем переменную в байтах (после увидим почему), эту переменную мы пытаемся округлить (по возможности) к ближайшей большей единицы измерения. Если переменная "pwr" = 0, то мы и оставим переменную в байтах, если "pwr" = 1, мы переведем в килобайты и т.д.
Также мы приписываем единицу измерения через пробел ссылаясь на индекс в ранее подготовленном кортеже при помощи индекса "pwr". Но стоит обратить в 11 строке также на загадочную запись ":.0f", это запись необходима для того чтобы указать явное форматирование числа с округлением до ближайшего (0 знаков после запятой).
В строках 14-19 мы считываем данные из файла. Причем мы даже не считываем все строки в переменную, а сразу итерируемся по строкам из файла.
Если вам не требуется сохранять содержимое файла после его обработки и обработка каждой строки независима от других строк, то наиболее эффективным подходом будет обрабатывать строки непосредственно из файла, без предварительного считывания всего файла в переменную! Так мы сможем сэкономить память и нам ненужно дожидаться пока файл считается чтобы его обрабатывать.
В строке 18 мы и делаем преобразование из любых единиц измерения в байты. "int(f[1])" получает значение из файла, а "units.get(f[2])" запрашивает значение из словаря "units" по ключу "f[2]" - единицы измерения из файла.
В строке 19 в ранее созданном словаре (в самом начале) запрашиваем/создаем значение по ключу при помощи метода "get", при чем в случае если значение только необходимо добавить мы создаем пустой словарь с которым объединяем имя файла и его размер. Получаем словарь в котором ключи это форматы, а значения - это словарь в котором ключи это имена, а значения это размер в байтах.
Далее в строках 21-26 мы итерируемся по словарю (по факту уже кортежу т.к. применен метод "items" который возращает кортеж (ключ, значение), словари сортировать нельзя это неупорядоченная коллекции) распаковывая в переменные "k"и "v" пары ключ (формат файла), значение (словарь с парами название файла и размером в байтах).
В строке 22 печатаем пару имя файла и его формат. Переменная "s" здесь это значение ключа из словаря нового словаря "v", который в свою очередь получили ранее.
Строка 23 выполняет роль разделителя.
Строка 24 суммируем все значения словаря "v".
Строка 25 выводит на печать с преобразованием единиц при помощи ранее описанной функции.
ВЫВОДЫ
1. В задаче Тимур, Артур и новый курс необходимо подумать математически, на самом деле задачу можно решить также через среднюю арифметическую и сумму минимумов.
2. В задачах на проверку вхождения (Схожие буквы) помнить что логическая проверка "input() in ru" даёт значение 0 или 1, а при помощи "sum" мы можем посчитать количество вхождений.
3. В задачах где нам нужно переворачивать, менять местами и т.д. элементы (Переворатор) мы можем обращаться к списку по индексу и только этому диапазону вносить правки.
4. В тех случаях когда данные подаются через пробел в виде строки и нам необходимо преобразовать элементы в целочисленный тип, можно использовать следующую конструкцию:
В тех случаях когда нам необходимо посчитать количество вхождений элемента по определенному условию (Более одного), есть отличный строковый метод "count", также нужно помнить если мы обрабатываем данные, но нам не нужно обрабатывать дубликаты этих данных, то лучше использовать "set" чтобы снизить количество итераций.
5. В задачах где нам нужно создать последовательность чисел от 1 до n с последующей обработкой по условию (Максимальная группа) можно не создавать отдельные список с обработкой данных, а сразу итерироваться по циклу и обрабатывать порядковый номер итерации.
6. В задачах где нам необходимо проверить некоторое количество списков на общие данные, важно вспомнить про методы множеств и возможность распаковки не только для печати (Трудности перевода)!
7. В случаях когда нам необходимо знать индекс итерируемого объекта, нужно использовать "enumerate" (Схожие слова)!
8. В случаях когда нам нужно получить данные в список, но при этом хотим использовать только часть полученных данных, мы можем при распаковке элемента, ненужную часть сохранить в перменую, которую дальше не будем использовать (Корпоративная почта). Также если нам необходимо использовать числовой индекс в строковом типе данных, то в случае изменения индекса, хорошо поможет строковый метод "rstrip(digit)".
9. Если у нас есть математические преобразования (Файлы в файле) используй модуль MATH! Используй функции для однотипных задач. В случаях когда мы хотим располагать данные по каким-то характеристикам вместе, словарь отличное решение, особенно если есть степень вложенности. Если у нас есть цикл в переменную которого мы сохраняем объект, по которому тоже хотим итерироваться (случай со вложенностью), отличное решение сделать списочное выражение.