Всем привет! На днях задумался над тем возможно ли запускать мои обученные модели семейства ruGPT-3 (которые gpt2-based) способом отличным от рекомендованного, то есть не используя код генератора предложенный авторами проекта ru-gpts, а как-нибудь попроще? Ответом на данный вопрос оказалась библиотека LangChain.
Кстати, ранее я публиковал пост про обучение модели ruGPT-3 в домашних условиях, поэтому прежде чем продолжить чтение рекомендую с ней ознакомиться, так как я буду ссылать на некоторые примеры описанные в ней.
Мотивация
На ruGPT-3 разных вариаций мне довелось создать и обучить уже немало специализированных и очень любопытных моделей. И всех их объединяла одна общая черта, для удобства их эксплуатации я писал специальные API-серверы на Flask переиспользуя код generate_samples.py, нужно это было мне чтобы например последовательно прогонять некоторый текст через несколько моделей по цепочки с целью достижения наиболее качественных результатов. Помимо этого модели типа ruGPT-3 удобно использовать для классификации данных, к примеру необходимо понять на какую из моделей нужно перенаправить тот или иной запрос от пользователя в зависимости от контекста.
Где-то на третий или четвёртый раз написания подобного API сервера мне начало казаться, что я что-то делаю не так и поэтому стал искать какой-то альтернативный способ решения данной задачи. Но к сожалению, из-за низкой популярности проекта ruGPT-3, найти что-то заслуживающее внимание мне не удавалось, поэтому приходилось продолжать есть кактус.
Но в какой-то момент наткнулся на публикацию на Хабр под названием LangСhain: создаем свой AI в несколько строк в которой речь шла об инструменте, который как мне показалось идеально подходил для решения моих задач. Ведь при помощи этой библиотеки у меня больше не было бы необходимости писать API-серверы и хитрые HTTP-клиенты, иными словами одним небольшим скриптом можно было бы избавиться от большой части ненужной логики.
Короче мне стало понятно в каком направлении нужно копать.
Немного про LangChain
Итак, давайте поговорим о том, что же такое этот LangChain? Если вкратце то это небольшая, но удивительно мощная библиотека написанная на языке программирования Python, которая поможет вам создавать приложения с помощью больших языковых моделей (Large Language Models или сокращённо LLMs).
LangChain открывает возможности о которых бы вы с большой долей вероятности не задумывались если бы использовали какую-нибудь отдельную LLM, например обёртка над ruGPT-3 в виде API-сервера на Flask. Как вы знаете, большие языковые модели могут быть очень мощными, но их настоящий потенциал проявляется, когда вы комбинируете их с другими языковыми моделями, источниками вычислений и/или источниками знаний.
Нечто похожее можно обнаружить в исходных кодах проекта Koziev/chatbot, в нём автор реализовал что-то вроде цепочек обработки данных у чат-бота, и если нужно дать какой-то ответ который уже есть в базе знаний то бот отдаёт его, а если необходимо сгенерировать что-то при помощи LLM модели то система обращается к ней. Помимо этого проект использует модель для обнаружения синонимичного текста, что позволяет работать с базой знаний намного точнее и проще.
Но вернёмся к LangChain.
С помощью этой библиотеки вы сможете разрабатывать приложения похожие на конструктор LEGO, состоящие из множества разных компонентов, которые включают в себя вопросно-ответные системы для конкретных документов, чат-ботов и агентов. Примеры таких приложений можно найти в документации LangChain (и там дальше вниз по списку после Use Cases), которая содержит полные руководства и примеры использования.
LangChain предлагает решения в шести основных областях: управление LLMs и запросами, создание цепочек запросов, генерация текста с учетом данных, создание агентов, управление памятью и оценка качества генерируемого текста.
И все эти функции объединены в одной удобной библиотеке, любопытно, не правда ли?
ruGPT-3 + LangChain
Осталась только одна проблема, не было внятной документации о том как подружить ruGPT-3 и LangChain. Применим метод научного тыка и побродим по исходных кодам с зажатой клавишей Ctrl (в IDE от Jetbrains это значит следовать по ссылке, то если если навести на название класса и нажать ЛКМ, то откроется файл содержащий этот класс, ну и так далее).
Небольшое исследование
Прежде всего в исходных кодах ru-gpts можно обнаружить, что для запуска обученной модели исполняются стандартные трансформеры HuggingFace, а именно GPT2LMHeadModel и GPT2Tokenizer из пакета transformers.
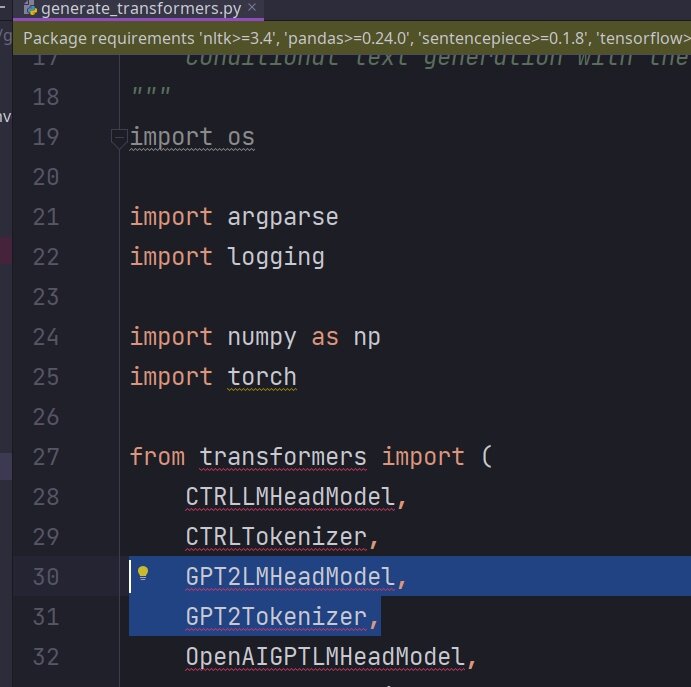
Далее можно посмотреть как эти классы инициализируются. В момент запуска скрипта generate_transformer.py пользователь передаёт ключ model_type, со значением gpt2. Далее из списка MODEL_CLASSES выбирается ключ gpt2, а в нём уже упомянутые ранее классы.
С деталями реализации ru-gpts разобрались, поэтому теперь посмотрим как при помощи LangChain выполнить нечто подобное.
В документации LangChain упоминается один примечательный способ работы с LLMs, называется он HuggingFace Pipeline, примечателен он прежде всего тем, что способен работать с локально загруженными моделями, в отличии от HuggungFace Hub, который выполняет запросы через HuggingFace Inference API на удалённый сервер.
И так, попробуем адаптировать пример из HF Pipeline под модель, которую мы обучали в предыдущей публикации. Для работы с ней нам понадобится содержимое директории под названием dostoevsky_doesnt_write_it (она основана на rugpt3small).
Подготовка мира
Для начала создадим пустую папку, далее создадим в ней поддиректорию models и создадим в ней символическую ссылку на файлы обученной модели:
mkdir rugpt3-langchain
cd rugpt3-langchain
mkdir models
ln -s ../../rugpt3-custom/dostoevsky_doesnt_write_it ./models/
Информация: тут стоит обратить внимание на то что в моё случае директории rugpt3-langchain и rugpt3-custom находятся на одном уровне, поэтому вероятно в вашем случае последняя команда будет отличаться.
Теперь потребуется инициализировать окружение venv и переключить контекст на него:
python3.10 -m virtualenv venv
. venv/bin/activate
Теперь установим необходимые пакеты:
pip install transformers==4.29.2 langchain==0.0.189 torch==2.0.1 xformers==0.0.20 accelerate==0.19.0
Можно также создать файл requirements.txt следующего содержимого:
transformers==4.29.2
langchain==0.0.189
torch==2.0.1
xformers==0.0.20
accelerate==0.19.0
И выполнить команду:
pip install -r requirements.txt
Наше окружение готово и можно переходить к написанию скриптов.
Написание скрипта генератора
Создадим файл huggingface_simple.py, вначале импортируем необходимые элементы и опишем путь до модели:
В аргументе model_id мы передаём относительный путь к модели (можно передать абсолютный, или просто названием модели с сайта HuggingFace после чего она будет предварительно загружена к вам на диск и закеширована).
Далее идёт параметр task, к сожалению ruGPT-3 может работать только в режиме "text-generation", но некоторые другие умеют чуточку больше.
Далее идёт параметр pipeline_kwargs - в нём передаются параметры инициализации модели, нас особенно интересует температура, p и k семлинг, пенальти повторений и максимальная длинна генерируемого текста (количество токенов). Конечно же есть и другие настройки, полный их список можно посмотреть в файле config.json обученной модели или в карточке исходной модели в файле с таким же названием.
Теперь немного поговорим про механизм шаблонов который предлагает система LangChain, при помощи шаблонов можно выполнять необходимые преобразования текста перед тем как передать его в модель. К примеру для создания чатбота обычно в шаблонах описывается небольшой диалог, чтобы модель понимала в каком формате необходимо вести дискуссию. Либо же это будет некий подготовленный шаблон, который вводит модель в курс дела, это удобно например для персонализации ответов модели (допустим для имитации некоего стиля текста).
В нашем же случае шаблон будет максимально просто и содержать всего одну строку: {question} (без пустой строки в конце)
Создадим папку templates, в ней файл simple.tml и в нём будет та самая строка:
mkdir templates
touch ./templates/simple.tpl
echo "{question}" > ./templates/simple.tpl
Теперь добавим инициализацию этого шаблона в наш скрипт:
Двигаемся далее, мне хочется чтобы скрипт мог принимать первым аргументом некий текст, который я хочу передать на обработку:
Ну всё, можно теперь запускать и смотреть, что получилось.
Как видно даже small модель генерирует очень неплохие результаты.
А вот ссылка на исходный код данного скрипта:
Генерация с "прогретым" контекстом
Давайте теперь немного усложним задачу и чуть доработаем шаблон, в нём мы передадим некоторые входные данные, которые модель будет учитывать при генерации своего ответа.
Создадим файл шаблона ./templates/context.tpl и опишем в нём события участниками которых мы хотим сделать нашу модель, например:
Конец 1867 года. Князь Лев Николаевич Мышкин приезжает в Петербург из Швейцарии. Ему двадцать шесть лет, он последний
из знатного дворянского рода, рано осиротел, в детстве заболел тяжёлой нервной болезнью и был помещён своим опекуном и
благодетелем Павлищевым в швейцарский санаторий.
{question}
Данная затравка была взята с сайта Достоевский Ф.М. из краткого содержания к произведению "Идиот", пустой строки после переменной {question} тоже не должно быть.
Далее создадим файл huggingface_context.py, в целом он почти ничем не будет отличаться от huggingface_simple.py из предущей подглавы, кроме пути до шаблона и значения поля max_length, так как текст из шаблона тоже учитывается в момент выполнения запроса (а также и история чата, но об этом в следующей подглаве).
Теперь запустим то что получилось несколько раз и посмотрим на результат:
По итогу видно, что система поняла контекст и пусть в паре мест не совсем корректно его интерпритировала, но в целом получилось очень даже не плохо.
А вот ссылка на исходный код данного скрипта:
Чат с князем Мышкиным
Подходим к последнему примеру, на этот раз реализуем небольшой чат имитирующий диалог князя Мышкина (нейросеть) и купца Рогожина (это мы) из произведения "Идиот", для этого нам напишем новый скрипт.
Необходимо будет сделать бесконечный цикл, который будет общаться с моделью и отвечать нам в определённом формате, а также реагировать на команду exit, она будет приводить к завершению бесконечного цикла. Помимо этого чат будет помнить историю нашей беседы и будет пытаться адекватно реагировать на новые сообщения. Сеть будет воспринимать нас как одного из героев книги, о чём мы ей в процессе инициализации ей и сообщим.
Но давайте ближе к коду, первым делом нужно понять как работает буфер памяти, ну или история чата. Для решения подобных задач у LangChaing есть набор классов для хранения истории переписки, подробности рекомендую почитать в официальной документации, но а мы продолжим.
Создадим шаблон контекста ./templates/chat.tpl, в нём мы как и прежде вкратце опишем события из произведения "Идиот", но немного его дополним, мы попытаемся заставить модель думать, что она ведёт диалог между князем Мышкиным и купцом Рогожиным, пользователь модели будет в выступать роли Рогожина, а модель в роли князя.
Действие первой части происходит на протяжении одного дня, 27 ноября 1867 года.
26-летний князь Лев Николаевич Мышкин возвращается из Швейцарии, где провёл несколько лет, лечась от эпилепсии.
Князь предстаёт человеком искренним и невинным, хотя и прилично разбирающимся в отношениях между людьми.
Он едет в Россию в Санкт-Петербург к единственным оставшимся у него родственникам — семье Епанчиных.
В поезде он знакомится с молодым купцом Парфёном Семёнович Рогожиным и отставным чиновником Лебедевым, которым
бесхитростно рассказывает свою историю.
Начало беседы.
Рогожин: Зябко? — и повел плечами.
Князь: Очень, — ответил сосед с чрезвычайною готовностью, — и заметьте, это еще оттепель. Что ж, если бы мороз? Я даже не думал, что у нас так холодно. Отвык.
Рогожин: Из-за границы что ль?
Князь: Да, из Швейцарии.
Рогожин: Фью! Эк ведь вас!..
Князь: Долго не был в России, слишком четыре года.
Рогожин: Почему поехали на чужбину?
Князь: Отправлен был за границу по болезни, по какой-то странной нервной болезни, в роде падучей или Виттовой пляски, каких-то дрожаний и судорог.
Рогожин: Что же, вылечили?
Князь: Нет, не вылечили.
{chat_history}
Рогожин: {human_input}
Князь:
Не забываем про то, что пустой строки в конце файла быть не должно.
Создадим файл huggingface_chat.py и для начала выполним инициализацию буфера памяти:
Далее инициализируем пайплайн модели, единственное отличие от прошлого примера в том, что контекст увеличит до 2048 токенов.
Теперь создадим бесконечный цикл в формате чата:
Из примечательного тут использованием механизма памяти диалога, по завершению каждого шага выполняется сохранение истории, в дальнейшем эта память используется в момент рендера шаблона.
Ну и вот небольшой пример диалога, который состоялся между купцом Рогожиным и князем Мышкиным во время поездки в поезде до Санкт-Перербурга:
Конечно полученный результат далёк от совершенства, но и мой изначальный датасет был далеко не лучшего вида, в принципе если привести его в нормальный вид, научить делать правильные завершения предложений и использовать более сложную модель, то возможно получится гораздо более адекватный собеседник, умело имитирующий князя Меньшикова, но это уже совсем другая история.
Ссылочка на исходный код:
Завершение
Ну чтож, надеюсь мне удалось продемонстрировать вам как легко и просто запустить обученные модельки ruGPT-3 в связке с библиотекой LangChain. В дальнейшем я планирую применить эти механизмы для того чтобы свести несколько разных моделей в общее API, но про это расскажу отдельно (пока ещё просто не всё для этого готово).
Если вам интересно узнать больше или обсудить что-то конкретное, присоединяйтесь к моему Telegram-каналу. Там я регулярно делюсь своими мыслями и новостями в области IT, а также отвечаю на ваши вопросы.
Спасибо за то, что провели время со мной, увидимся в следующей публикации! До встречи!