Солнечные панели и особенности логистики
Один из наших заказчиков занимается техническим обслуживанием и аналитикой состояния солнечных панелей при их перепродаже.
Панель - сложная в производстве конструкция и очень хрупкая. При эксплуатации она зачастую получает различные дефекты, которые влияют на ее производительность. При перепродаже солнечной панели покупатель хочет подтверждения, что продукт будет надлежащего качества, для этого он запрашивает у продавца снимки в специальном спектре, на которых видны все огрехи. При этом если сломанная панель доехала до места назначения, и на месте выяснились ее дефекты, то она должна также быть доставлена в ремонтный цех. Логистика перегружена, а покупатель несет убытки.
Для того, чтобы не везти бракованное изделие через весь мир и обратно, необходимо как можно раньше выявлять дефекты и не покупать такие панели. Для этого панели фотографируют с серийными номерами в специальном спектре, отправляют покупателю на проверку.
Bottlenecks
Изучение каждой панели - длительный процесс. Уполномоченные специалисты очень редки как квалифицированный персонал, поэтому их функцию порой выполняет любой кто более-менее “в теме”, что сказывается на качестве. А если еще мы добавим сюда человеческий фактор - халатность, или обычную усталость, когда глаз "замыливается" и становится сложно различить мелкие дефекты, в итоге перед вами ложноотрицательный результат. А ведь еще нужно заполнять отчет, документируя каждую царапину. На обработку одной панели уходило до 20 минут, что существенно ограничивало маневр и создавало “бутылочные горла”
Стоит ли говорить, что квалификация техника по качеству - вещь трудно-масштабируемая и трудно-заменяемая, и в случае болезни или невыхода на работу в терминалах образуется логистический “тромб” из панелей ожидающих инспекции. А это уже подрыв ожиданий конечных покупателей, которые очень ждут оборудование в нужный срок.
Быть может ML нам поможет?
Заказчик решил, что эту задачу нужно срочно автоматизировать и ставить на рельсы машинного зрения. Для этого была нанята команда из Индии, которая попыталась собрать решение на базе OpenCV применив эвристики для поиска трещин. При этом подходе изображение панели в специальном черно-белом спектре подавалось на вход, на снимке находилась сетка из ячеек, а затем уже внутри сетки при помощи отсева шумов искались различные паттерны трещин.
Обработка одной панели доходила до 30 (!) минут (при 20 минутах обработки человеком), а качество оставляло желать лучшего. В день нужно было обрабатывать несколько сотен снимков, а с такой скоростью это просто не представлялось возможным.
Идем на помощь
Заказчик расстроился и почти потерял веру в машинное зрение, но тут проект попал в наши заботливые руки.
В самой первой итерации мы отказались от CV-эвристик и решили сразу пустить в атаку нейронные сети, а именно нашу любимую архитектуру YOLO. Время обработки сократилось до 10 минут на одну панель, но качество было не слишком выше решения команды из Индии. Тогда нам стало понятно, что принцип “garbage in - garbage out” (плохие данные на входе приводят к плохим результатам анализа) - это не просто блажь, а выстраданная максима - в нашем датасете были существенные проблемы.
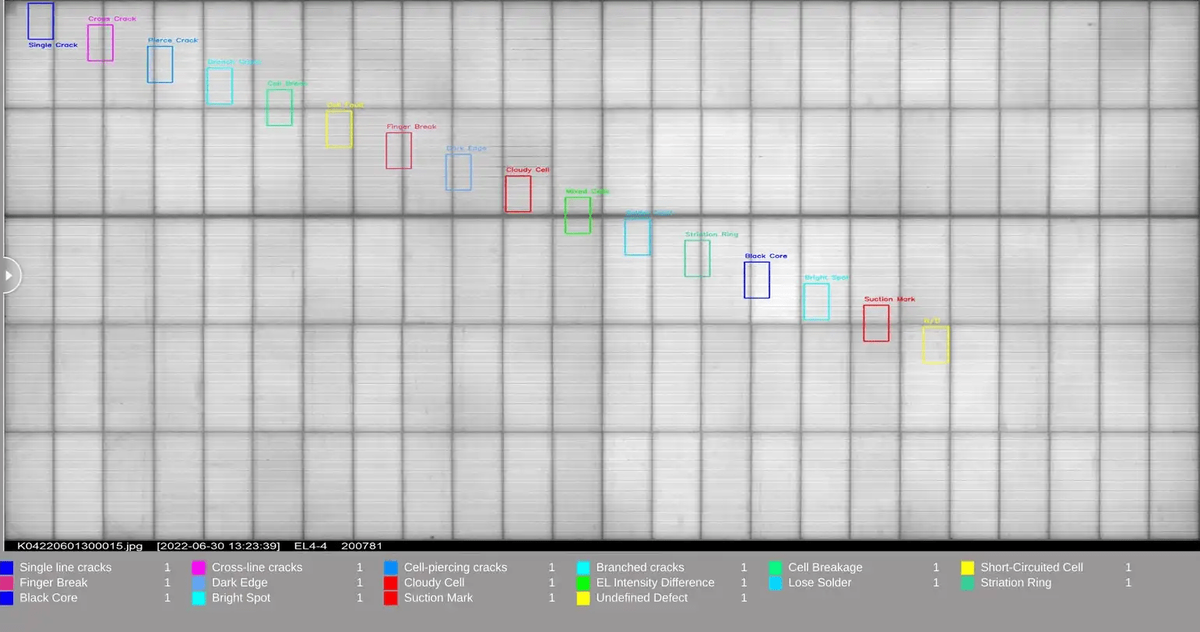
Все непросто с данными
Очень большим ограничением для нас был исходный датасет: у нас были изображения, на которых на рисунке было синим обведены и подписаны дефекты. Более того, дефекты были обведены овалами вместо привычных квадратных боксов в специализированной программе, и были очень плохо локализованы (одна маленькая трещина была обведена огромным овалом). В такой ситуации нельзя отделить данные от разметки, и эти артефакты существенно портили нам жизнь.
Вообщем качество исходного датасета оставляло желать лучшего, и к нам пришло понимание, что датасет нуждается в доработке. Мы пробовали разметить данные своими силами, но быстро поняли, что это плохая идея -
ML-инженер для этого не подходит, а отвлекать остальных также слишком хлопотно. И тогда мы решили пойти с переразметкой в краудсорсинг-решения.

Мудрость коллектива
На площадке Яндекс.Толока мы создали проект. Постарались сделать все
по-взрослому: обучающие материалы, онлайн экзамен, присвоение навыков разметчикам, ручной (а затем и автоматизированный) контроль качества исполнителей.
Благодаря выстроенному процессу и наличию пула квалифицированных разметчиков теперь мы могли масштабировать разметку: добавлять новые классы дефектов, размечать новые пачки данных, получать готовый результат за пару часов (при 2 неделях in-house разметки) за весьма приятный бюджет.
Вперед к внедрению
После загрузки переразмеченных данных модель прогрессировала: IoU (intersection over union - пересечение реального бокса с дефектом и предсказанного бокса) поднялся с 40% до 75%, что уже было хороший доверительным порогом. А дополнительный тюнинг YOLO позволи сократить время обработки с 10 до 1 минуты. Модель созрела и пора было выпускать ее в мир.
В рамках работ по внедрению мы сделали десктоп-приложение для специалистов логистических центров, куда они могли заливать гигабайты изображений. В результате они получали отчет с аналитикой по самым проблемным панелям, а также могли через браузер смотреть автоматически размеченные панели онлайн. Общее время обработки на узлах маршрутов сократилось в два раза.
Для изготовителя мы разработали back-office, через который можно смотреть загруженные данные с логистических узлов, смотреть сами панели с подсветкой дефектов, формировать детализированные отчеты и делать по ним выводы.
На очереди новые вызовы
Несмотря на то, что проект был успешно запущен, мы понимаем, нет предела совершенству и решаем задачи с дальнейшей оптимизацией, помогая заказчику умно экономить деньги. Мы переходим на более дешевые CPU инстансы для обработки вместо дорогих GPU машин, боремся с fraud-ом (да, бывает изображения фотошопят, чтобы скрыть дефекты), и непрестанно повышаем IoU показатели нашей модели.