Всем привет, меня зовут Андрей, это снова я!
Продолжим говорить про решение японских кроссвордов с помощью эксель.
Пусть, например, у нас есть следующий японский кроссворд, который нужно разгадать:
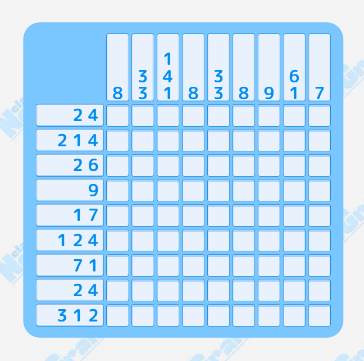
Вначале перерисуем наши основные исходные данные в эксель, и вот что мы должны получить:
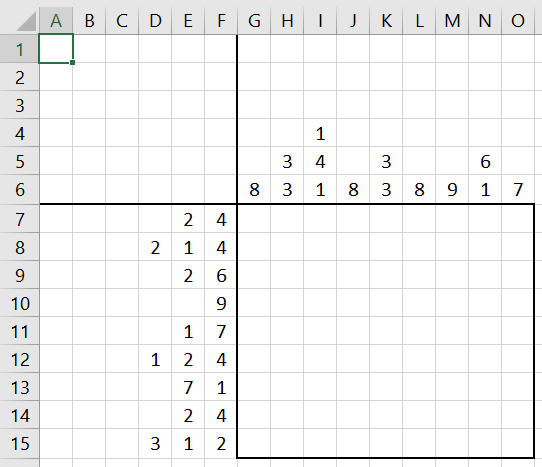
Затем предположим, что в закрашенных клетках должны быть единицы, а в не закрашенных – ноли. Найдем все суммы закрашенных ячеек, которые должны быть по строкам, по столбцам, и всего по всему японскому кроссворду:
Затем выделим ячейки для подсчета единиц, то есть сумм закрашенных ячеек, по строкам и по столбцам. Вот что получится:
Вот какие формулы будут в основных ячейках, которые нам понадобятся:
А теперь представим, что внутри того квадрата находятся переменные от х1 до х81 (потому что наш квадрат – это поле 9 на 9, там 81 клетка). На этом этапе уже можно привлечь элемент эксель «поиск решения» для нахождения значений этих переменных икс.
Вот как будут располагаться наши переменные:
Итак, подключим «поиск решения». Первым делом установим целевую функцию. Она у нас будет в ячейке S17, потому что именно там у нас происходит подсчет суммы всех тех ячеек, которые нужно закрасить. Другими словами, целевая функция – это сумма всех переменных от Х1 до Х81, и она должна быть равна 65, потому что именно столько ячеек должно быть закрашено. Эта сумма вычисляется просто, ведь у нас в исходных данных содержатся все те цифры (как по вертикалям, так и по горизонталям), которые нужно просто сложить.
На этом рисунке установлены основные параметры, которые нужно задать в первую очередь. Целевая функция – это та ячейка, в которой мы предварительно установили формулу. Неважно, как именно мы будем суммировать значения переменных от Х1 до Х81 в целевой функции (там может быть либо сумма тех ячеек, в которых находятся сами эти переменные, либо сумма промежуточных ячеек, то есть тех ячеек, в которых содержатся суммы тех строк или столбцов, из которых состоят нужные нам переменные). Главное в том, чтобы в той ячейке, в которой находится целевая функция, была формула, и чтобы эта формула производила подсчет суммы переменных от Х1 до Х81.
Кроме того, мы видим, что нужно оптимизировать значение целевой функции до значения 65 (потому что именно столько ячеек нам надо закрасить), а в графе «Изменяя ячейки переменных» мы видим именно тот диапазон ячеек, в котором находятся наши переменные от Х1 до Х81.
В графе «метод решения» мы выбираем симплекс-метод, а галочка чуть выше этой графы означает, что все переменные не должны быть меньше ноля.
На следующем этапе можно вводить все ограничения, то есть те уравнения и неравенства, которые помогут нам решить японский кроссворд.
Первое ограничение, которое нам понадобится, будет означать, что каждая из переменных не должна быть больше единицы:
Второе ограничение будет иметь отношение к первой строке переменных (от Х1 до Х9). Сумма этих переменных должна быть равна 6. Это значит, что значение ячейки S7 (потому что именно в эту ячейку мы заранее ввели формулу: сумму переменных от Х1 до Х9) должно быть равно 6 (именно 6, потому что для этой строки нам известны две суммы по закрашенным ячейкам – это 2 и 4, они в сумме составляют 6).
Кстати, в графе «ограничения» можно использовать как какие-то конкретные числа (как уже говорилось выше, можно было в ограничении написать цифру 6), но можно вместо цифр ввести и ссылки на ячейки, как это мы и сделали в нашем случае (S7=Q7), ведь мы уже заранее нашли суммы тех ячеек, которые должны быть закрашены, как по строкам, так и по столбцам. А в ячейку Q7 мы уже заранее поместили формулу подсчета закрашенных ячеек в первой (верхней) строке.
Удобство ввода не констант, а формул со ссылками на конкретные ячейки, заключается в том, что если мы несколько раз хотим отгадывать японские кроссворды одной и той же размерности, то достаточно один раз ввести все ограничения, а при решении каждого нового кроссворда просто заменять те исходные данные, что даются в самом начале. Можно даже в одном и том же файле создать несколько листов, каждому листу будет соответствовать своя размерность кроссворда. При решении нового кроссворда нужно будет только отсортировать все ограничения, оставив те, которые будут применимы для любых других кроссвордов той же размерности. В нашем конкретном случае только что добавленное ограничение можно будет применять ко всем кроссвордам той же размерности (9 на 9).
После того, как мы аналогичным образом введем все ограничения, которые имеют отношения к суммам строк, уже можно попробовать найти значения переменных. Конечно же, мы получим только предварительные данные, и они, скорее всего будут неправильными, потому что у нас будет только лишь совпадать количество закрашенных ячеек каждой из строк. Но мы еще не вводили аналогичные ограничения для столбцов. Вот какие предварительные значения переменных мы можем получить, если попробуем решить задачу на данном этапе ввода данных:
Конечно же, это не окончательный вариант. Теперь можно приступить к аналогичным ограничениям, в которых содержится сумма столбцов. Начнем с самого левого столбца: Х1+Х10+Х19+Х28+Х37+Х46+Х55+Х64+Х73=8:
Здесь аналогичная ситуация, хоть мы и знаем, что в нашем конкретном случае сумма закрашенных ячеек левого столбца равна восьми, но в графу "ограничения" мы вводим не цифру 8, а ссылку на ячейку G17, где мы заранее поместили формулу, которая суммирует число закрашенных ячеек левого столбца, то есть тех, которые были нам даны с самого начала.
Затем аналогичным образом введем все другие суммы столбцов. После этого еще раз найдем решение. Оно тоже будет не окончательным, но в нем уже будут сходиться суммы и по строкам, и по столбцам:
Далее можно с помощью условного форматирования выделить те строки и столбцы, в которых точно известны все нужные цифры. Например, у нас квадрат 9 на 9, и где-то есть строка с одной девяткой. Или одна срока, где есть единица и семерка (их сумма равна 8, между ними всего одна не закрашенная ячейка, и ясно, что она может быть только в одном месте).
Вот как будут выглядеть числа, выделенные с помощью условного формата:
Здесь все просто. Для каждой области (строки или столбца) формула условного форматирования будет такой, что если к сумме всех закрашенных ячеек этой области прибавить количество блоков этой же области, и получится 10 (потому что у нас 9 строк и 9 столбцов, а 10=9+1), то для этой области известны все закрашенные клетки.
Таким образом, у нас выявилось несколько строк, для которых известны все цифры. По этим строкам отдельно выделим (например, красной заливкой) те ячейки, в которых точно должны быть ноли.
Что касается столбцов – с ними все понятно, у нас есть только один столбец, для которого однозначно можно сказать, что по нему известны все цифры, и все эти цифры – единицы. Поэтому там и выделять ничего не надо.
В нашем конкретном примере вот как будут выглядеть те ячейки, где должны быть ноли:
Кроме того, мы можем выделить (также условным форматированием) те числа среди основных первоначальных данных, которые превышают половину от размерности нашего кроссворда (в нашем конкретном случае размерность равна 9, поэтому нас интересует то, что больше либо равно 5):
Те оранжевые квадратики, что образовались в столбцах E и F, нас в данной ситуации не интересуют, потому что они оказались в тех строках, насчет которых мы уже и так выяснили, что там нам уже известна каждая цифра. Поэтому обратим внимание на те оранжевые квадратики, которые оказались в строках 5 и 6 эксель.
Там есть несколько восьмерок, а у нас всего 9 строк. Это значит, что в тех столбцах, что содержат восьмерку, 7 цифр подряд (в середине) будут единицами, и только одна (пока не известно, вверху или внизу) будет не единицей, то есть нулем.
Аналогично можно сказать про все семерки (рыжая семерка в исходных данных будет означать, что там есть пять подряд единиц в середине). В любом случае, если N не четно (N – это размерность области, в нашем случае и строка, и столбец состоят из 9 элементов), тогда можно сделать следующее:
- вначале удвоим «рыжую» цифру, то есть ту, что превышает половину от N;
- затем из полученного результата отнимем N, и мы получим ровно столько клеток, сколько должно быть закрашенными в середине рассматриваемой области. Даже если останется одна клетка, это значит, что именно в самой середине нужной области должна быть единица, то есть закрашенная клетка.
Исходя из всего изложенного, выделим зеленым цветом только те клетки, где точно должна быть единица.
Тот столбец, который состоит только из одних девяток, мы не выделили, потому что там в любом случае будут только девятки, потому что предыдущие ограничения, которые мы наложили на все переменные, исключают другие варианты.
Нам остается только наложить ограничения как на те переменные, что равны нулю, так и на те, что равны единице. Эти ограничения полностью идентичны тем, что мы уже накладывали, когда речь шла о сумме переменных по строкам или столбцам.
Но и тут мы видим, что соблюдены не все те условия, о которых говорилось в исходных данных. Выделим светло-зеленым фоном те ноли, которые должны точно должны быть единицами, а светло-красным те единицы, что точно должны быть нулями:
На эти недавно выделенные клетки тоже наложим ограничения и снова найдем решение, вот что получим:
Но, к сожалению, полученный результат тоже не соответствует всем тем условиям, что были заданы в начале. Снова найдем и выделим желтым те цифры, что стоят не на своих местах:
Уже сейчас очевидно: как только мы заменим «желтые» цифры, то решение будет найдено. Эти замены «желтых» цифр (нули на единицы, единицы на нули) можно произвести как вручную, так и с помощью новых ограничений. Вот что мы получим в результате:
Решение получено, осталось только с помощью условного форматирования сделать так, чтобы у всех единиц был черный фон и черный шрифт, а у всех нолей – белый фон и белый шрифт. Вот что получится:
Какие бы ни были цвета фона и шрифта, условное форматирование все равно победило.
Это и будет нашим рисунком.
Если кому больше нравится не черный цвет, а другой, можно черный цвет заменить на другой, например, на зеленый:
В названии этой статьи я намекнул, что при таком использовании эксель для решения судоку мы себе создаем помощника (помогатора, выражаясь языком современной детской песенки). Это значит, что эксель не берет на себя всю работу по разгадыванию японского кроссворда, а только помогает. Если у меня возникнут идеи о том, как можно еще больше, еще сильнее увеличить роль судоку в составлении японских кроссвордов, я обязательно об этом напишу!