Для анализа данных на предмет оценки влияния каждого из параметров на целевую величину (коэффициент рождаемости) я использовал обученные на этих данных модели. Модель — формула, описывающая всю совокупность собранной статистики. Работал с данными и обучал модели с помощью библиотек 3-го Питона.
Этап первый — подготовка данных.
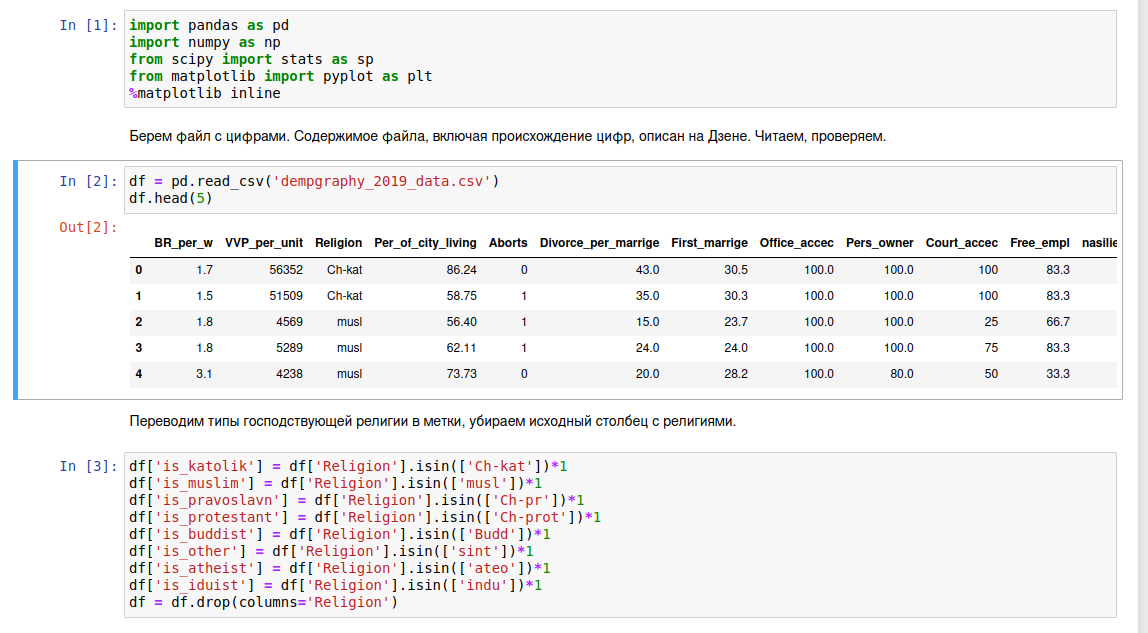
В рамках оной заменяю столбец религии на столбцы маркеров принадлежности к каждой из них.
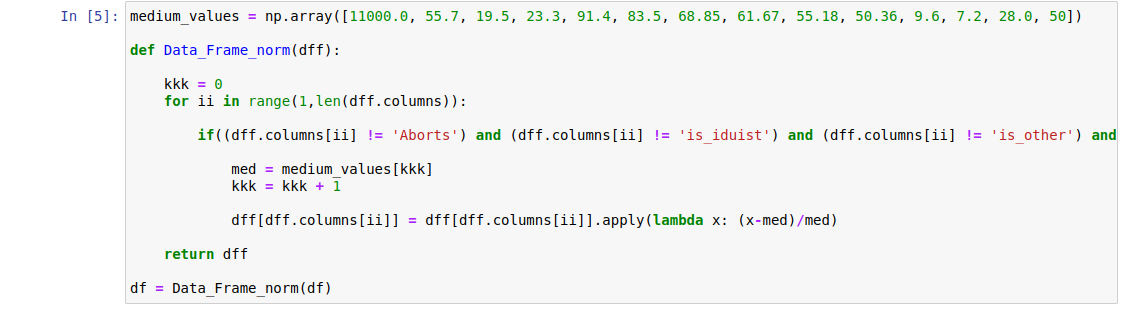
Вещественные признаки обезразмериваем. Нас же интересует не зависимость рождаемости от абсолютных значений отдельных параметров, а ее зависимость от их отклонений от среднемировых значений. Соответственно, из абсолютных значений параметров вычитаем среднемировые, после чего на них же и делим. Т.е. переводим вопрос из плоскости «как изменится рождаемость при изменении ВВП на N долларов?» в «как она изменится при отклонении ВВП от среднемирового на N процентов?»
Существенно, что преобразованные таким образом значения параметров демонстрируют значимый разброс. Есть что анализировать.
Этап 2 — Линейное приближение
В качестве предварительного анализа построим самую простую модель — формулу вида «А = w1*X1 + w2*X2 + w3*X3 + ...» (А — коэффициент рождаемости, Х — относительное отклонение параметра от среднемирового значения, w — коэффициент пропорциональности, показывающий степень влияния Х на А). Понятно, что реальные зависимости редко имеют линейный вид. Т.е. модель будет крайне грубой, с большой погрешностью. Но этот минус порождает и плюс - линейная модель проста с точки зрения анализа влияния отдельных параметров на результат.
Замечу, что в рамках построения линейной (и не только линейной) модели А (т.е. коэффициент рождаемости) обладает неопределенностью. Все же количество как женщин, так и детей с точностью до человека обычно не известны. Даже перепись населения допускает погрешность в виде не переписанных / «мертвых душ» и т.д. Данная неопределенность, безусловно, варьируется от страны к стране. Но в качестве среднего общемирового значения можно принять +/- 20 % (на основании погрешности по отдельным регионам). Учитываться она будет путем вариантных расчетов коэффициентов модели w — т.е. обучаем модель 100-200 раз, варьируя каждый раз коэффициент рождаемости случайным образом по нормальному распределения с относительной сигмой 0.2. Получаем 200 вариантов коэффициенты w, вычисляем среднее.
В качестве результатов обучения модели получаем список значений ее коэффициентов. Для простоты анализа отнормируем их на максимальный и выведем списком. Описание условных обозначений в списке привел в таблице ниже по тексту.
Абсолютно лидируют два пункта - возраст выдачи женщины взамуж и распространенность контрацептивов. На мой взгляд, самая вероятная интерпретация этого - никто на планете не плодится во вменяемых количествах только ради детей. Всякое слезливо-сопливое или высокие материи уровня "хочу дитятку", "хочу наследника", "нужно рожать, а то русские/татарские/мордовские вымрут" - это не про рождаемость. И никакие деньги так же не решают (что тоже вполне объяснимо).
Рожают много там, где, с одной стороны, есть мощная сторонняя мотивация (к примеру, желание потрахаться), побочным продуктом которой становятся дети. С другой - где женщин особо не спрашивают, когда они соберутся рожать.
Ну ок, линейная модель - примитив, первое приближение. С, понятно дело, большой погрешностью - 44 % (при погрешности коэффициента рождаемости в 20 %). Далее можно попробовать обучать что-то, способное выявлять зависимости посложнее.
Предварительно сделаем еще проверку нашей линейной модели (т.е. что все корректно запрограммировано и проанализировано). Для этого можем попробовать использовать обучение логистической регрессии. Это когда мы значения линейной модели проверяем пороговой функцией, дающей на выходе 0 или 1. С точки зрения программирования и обучения - таки разница. С точки же зрения первых производных модели по параметрам - результат должен быть схожим (с учетом того, как вид должна иметь первая производная).
Логистическая регрессия будет описывать, будет ли при заданном сочетании параметров рождаемость в стране превышать порог самовоспроизведения (2.2 ребенка на женщину) — 0 или 1.
Отличие от предыдущего пункта будет заключаться в подходе к оценке первых производных. Модель имеет вид куда сложнее, чем в линейном случае. Потому будем оценивать производные «в лоб» - задавая приращения аргумента и вычисляя приращение функции, делим одно на другое. Делаем это для всей выборки (т.е. находим среднее значение). В случае бинарных параметров в качестве приращения аргумента будем брать 1 (как интеграл по некоторому малому интервалу от дельта-функции).
Результаты получились качественно близкими — лидерами по влиянию, опять же, оказались возраст выхода в брак и распространенность контрацептивов. Не один-в-один, но и модель описывает другое распределение (пороговое - выше 2.2 или нет). В частности, с точки зрения линейной модели страны с уровнем рождаемости 3.0 и 7.0 - это таки разные страны. В рамках же этой модели они попадают в одну группу.
На втором месте по силе влияния оказался уровень ВВП на душу населения (где беднее - там больше рожают). Это объяснимо - низкийй ВВП характерен для развивающихся стран, где и с доступом к контрацептивам все хуже, да и люди потрадиционнее.
Влияние других параметров получилось иным, да. Но ведь и вопрос был поставлен иначе — не «где рожают больше?», а «где рожают выше порога 2.2?» А это уже несколько иной список стран.
Усложним модель дальше - перейдем к "случайному лесу".
"Случайный лес" позволяет проверять не только преодоление порога самовоспроизводства, но и оценить, насколько сильно он преодолен. Соответственно, можно анализировать рождаемость не в упрощенной постановке вида "выше уровня самовоспроизводства или нет", а в близкой к полной (как в случае линейной модели). Но, в отличие от линейной модели, "случайный лес" нелинейные зависимости учитывать уже может.
Непрерывный ряд возможных значений коэффициента рождаемости можно разбить на интервалы. Модель будет предсказывать номер интервала. Разбиение будем делать неравномерно, т.к. стран с коэффициентом рождаемости от 1 до 2 примерно столько же, сколько и с коэффициентом от 2 до 7. Последний интервал суммируем с предпоследним, т.к. иначе в нем будет очень мало объектов.
В итоге получаем +/- сбалансированную по числу объектов в интервале выборку.
С ней обучаем «случайный лес», производные (силу влияния параметров) при этом оцениваем так же, как и в случае логистической регрессии.
Интересно, что в случае модели, способной учитывать нелинейные зависимости, мы видим качественное изменение результатов — хотя возраст заключения брака и остался самым значимым параметром, теперь на второе место по степени влияния вышел уровень ВВП. Правда, со знаком «минус» - т.е. чем беднее страна, тем лучше плодится население. Да, это, вероятно, корреляция, а не причинно-следственная связь. Но, полагаю, объяснить ее наличие не трудно — население нищих регионов, с одной стороны, меньше тратятся на контрацепцию (см. значимость последней с точки зрения линейно модели), с другой — имеют более традиционалистские взгляды. Это подтверждают следующие по значимости параметры, объясняющие различия в уровне рождаемости уже между странами с низким ВВП — количество разводов, распространенность контрацепции и детская занятость.
Зафиналим наш анализ кросс-верификацией «случайного леса» обученной аналогичным образом нейросетью.
Сеть будет с одним промежуточным слоем (что достаточно для задачи такого уровня сложности). Число выходных нейронов равно числу интервалов, на которые разбит диапазон значений коэффициента рождаемости. Произвольными параметрами модели остаются число нейронов на внутреннем слое и количество итераций при обучении. Их оптимальные значения искал стандартным поиском по сетке (делал на основном ПК, потому здесь только результат без принтскрина — делать это на ноуте слишком долго) — 10 нейронов на промежуточном слое и 600 итераций.
Видим, что результат случайного леса мы очень близко воспроизвели.
Итого, что у нас влияет/коррелирует с высокой рождаемостью, а что, согласно имеющимся данным, не имеет статистической связи (и, вероятно, влияния) с высокой рождаемостью (1 — максимальное влияние, 0 — не влияет; знак «-» - если параметр растет, рождаемость падает и наоборот, знак «+» - если параметр растет, рождаемость так же растет, и наоборот):
Сам юпитеровский файл можно скачать по ссылке: https://disk.yandex.ru/d/F6VWjRuKSKbyDg