
АННОТАЦИЯ
Пояснительная записка 51 с., 17 рис., 4 таб., 17 источников, 5 приложений
ИСКУСТВЕННЫЙ ИНТЕЛЛЕКТ, СИСТЕМА, ВЫБОРКА, МОДЕЛЬ, СВЁРТОЧНАЯ НЕЙРОННАЯ СЕТЬ, РАСПОЗНАВАНИЕ, ИЗОБРАЖЕНИЕ, АНАЛИЗ, ОБУЧЕНИЕ
Объектом исследования является система распознавания наличия пешеходных переходов на изображениях.
Предмет исследования — выборка из 160 фотографий, содержащая 80 изображений с пешеходными переходами, и 80 любых фотографий.
Целью исследования является реализация системы распознавания пешеходных переходов с контролем качества обучения моделей нейронных сетей распознаванию наличия пешеходного перехода (зебры) на фотографии.
В ходе работы был изучен такой метод машинного обучения, как «с учителем». Была произведена работа с библиотеками Matplotlib и Keras, в частности, с тремя моделями обучения из библиотеки Keras: Sequential, InceptionV3 и VGG16. Также были созданы обучающая и контрольная выборки, содержащие изображения с зеброй и без неё.
В результате исследования каждым студентом была разработана и реализована программа обучения нейросети на языке Python для распознавания наличия пешеходных зебр на фотографиях. Также для каждой модели было произведено сравнение, анализ обучения и распознавания для выбора наилучшей из них.
СОДЕРЖАНИЕ
ТЕРМИНЫ И ОПРЕДЕЛЕНИЯ 5
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ И ОБОЗНАЧЕНИЙ 7
ВВЕДЕНИЕ 8
1 МОДЕЛИ ОБУЧЕНИЯ БИБЛИОТЕКИ KERAS 10
2 СИСТЕМА ОБУЧЕНИЯ «С УЧИТЕЛЕМ» 13
3 выбранныЕ моделИ обучЕНИЯ ДЛЯ РАЗРАБОТКИ СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ ПЕШЕХОДНОГО ПЕРЕХОДА 16
3.1 Модель Sequential 16
3.2 Модель InceptionV3 17
3.3 Модель VGG16 22
4 ФОРМИРОВАНИЕ И ПОДГОТОВКА ДАННЫХ ДЛЯ РАЗРАБОТКИ СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ ПЕШЕХОДНОГО ПЕРЕХОДА 25
5 РАЗРАБОТКА СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ ПЕШЕХОДНОГО ПЕРЕХОДА 26
5.1 Система распознавания образов 26
5.2 Система распознавания изображений 27
5.3 Свёрточные нейронные сети в системе распознавания изображений 29
6 АНАЛИЗ РЕЗУЛЬТАТОВ СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ ПЕШЕХОДНОГО ПЕРЕХОДА 35
6.1 Анализ качества обучения системы распознавания наличия пешеходного перехода 35
6.2 Анализ качества распознавания системы распознавания наличия пешеходного перехода 35
ЗАКЛЮЧЕНИЕ 37
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ. 38
ПРИЛОЖЕНИЕ A 40
ПРИЛОЖЕНИЕ Б 42
ПРИЛОЖЕНИЕ В 45
ПРИЛОЖЕНИЕ Г 48
ПРИЛОЖЕНИЕ Д 50
ТЕРМИНЫ И ОПРЕДЕЛЕНИЯ
В настоящей работе применяют следующие термины с соответствующими определениями:
Вес — сила связи между нейронами
Глубокое обучение — это совокупность методов машинного обучения (с учителем, с частичным привлечением учителя, без учителя, с подкреплением), основанных на обучении представлениям, а не специализированных алгоритмах под конкретные задачи
Искусственный интеллект — это технология, позволяющая системе, машине или компьютеру выполнять задачи, требующие разумного мышления, то есть имитировать поведение человека для постепенного обучения с использованием полученной информации и решения конкретных задач
Интерпретируемый язык программирования — язык программирования, в котором исходный код программы не преобразовывается в машинный код для его выполнения центральным процессором (как в компилируемых языках), а исполняется с помощью специальной программы-интерпретатора
Компьютерное зрение — теория и технология создания машин, которые могут производить обнаружение, отслеживание и классификацию объектов
Машинное обучение — это направление искусственного интеллекта, сосредоточенное на создании систем, которые обучаются и развиваются на основе получаемых ими данных
Нейронная сеть (также искусственная нейронная сеть) — это метод машинного обучения, называемый глубоким обучением, использующим взаимосвязанные узлы и нейроны в слоистой структуре, напоминающей человеческий мозг
Нейрон — это единица, которая получает информацию и производит над ней определённые вычисления
Ошибка — это процентная величина, отражающая расхождение между ожидаемым и полученным ответами
Тензор — объект линейной алгебры, линейно преобразующий элементы одного линейного пространства в элементы другого
Python — высокоуровневый динамический язык программирования общего назначения, который относится к интерпретируемым языкам
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ И ОБОЗНАЧЕНИЙ
В настоящей работе применяются следующие сокращения и обозначения:
НС — нейронная сеть
СНС — свёрточная нейронная сеть
ИНС — искусственная нейронная сеть
МО — машинное обучение
ГО — глубокое обучение
ВВЕДЕНИЕ
Нейронные сети и нейрокомпьютеры — отрасль знаний, весьма популярная в настоящее время. Это проявляется, в частности, в большом числе публикаций, конференций и различных областей применения. Одно из оснований такой популярности — их замечательные способности к обучению по наблюдаемым примерам и формированию приемлемых выводов на базе неполной, зашумленной и неточной входной информации. В последние несколько лет нейронные сети (далее - НС) пробрались во все отрасли машинного обучения (далее -МО), но самый большой фурор они бесспорно произвели в области компьютерного зрения [1].
Потенциал у нейронных технологий огромен, но их эффективное использование требует определённого уровня знаний и понимания принципов их действия. НС, в отличие от статистических методов многомерного классификационного анализа, базируются на параллельной обработке информации и обладают способностью к самообучению, то есть получать обоснованный результат на основании данных, которые не встречались в процессе обучения. Эти свойства позволяют НС решать сложные (масштабные) задачи, которые на сегодняшний день считаются трудноразрешимыми [1].
Цель работы — изучение и разработка программы обучения выбранных нами моделей НС распознаванию наличия пешеходного перехода на изображении, а также выбор наилучшей модели по следующим показателям:
- стабильность работы НС;
- скорость обучения;
- точность распознавания;
- объём занимаемой ею памяти.
Задачи работы:
- изучить тему МО;
- выбрать модели, которые будут использованы в обучении;
- сформировать обучающую и контрольную выборки;
- произвести обучение НС;
- произвести сравнительный анализ обучения моделей;
- провести тестирование каждой модели распознавания;
- провести анализ полученных результатов и выбрать наилучшую модель.
1 МОДЕЛИ ОБУЧЕНИЯ БИБЛИОТЕКИ KERAS
Перед тем, как выбрать модель обучения, мы изучили какие бывают модели МО в библиотеке Keras.
Keras — это гибкая модульная, легко настраиваемая, библиотека для языка программирования Python, предназначенная для глубокого обучения (далее - ГО). Она позволяет быстро создавать и настраивать модели искусственных нейронных сетей (далее - ИНС). Она является бесплатной и имеет открытый исходный код [2].
Библиотека Keras имеет узкую специализацию, поскольку это инструмент для специалистов по МО, которые работают с языком Python: именно его чаще всего используют благодаря удобству математических вычислений. Keras применяют разработчики, которые создают, настраивают и тестируют различные системы МО искусственного интеллекта, в первую очередь — НС [2].
Особенности библиотеки Keras:
- написана на чистом Python, чтобы код был понятнее и легче поддерживался;
- работает на большинстве платформ: не только на операционных системах Windows и Linux, но и на микрокомпьютерах, мобильных устройствах, в облаке или в браузере;
- поддерживает работу с CPU и GPU — с обычным или графическим процессором;
- поддерживает разные виды НС: классические перцептроны, свёрточные и рекуррентные сети, их комбинации;
- совместима с Python, начиная с версии 2.7 вплоть до современных.
Keras работает с моделями — схемами, по которым распространяется и преобразуется информация. Обработка информации происходит с помощью НС, где на основе определённых данных делаются те или иные выводы. Список доступных моделей библиотеки Keras представлен в таблице 1.
Таблица 1 – Список моделей библиотеки Keras
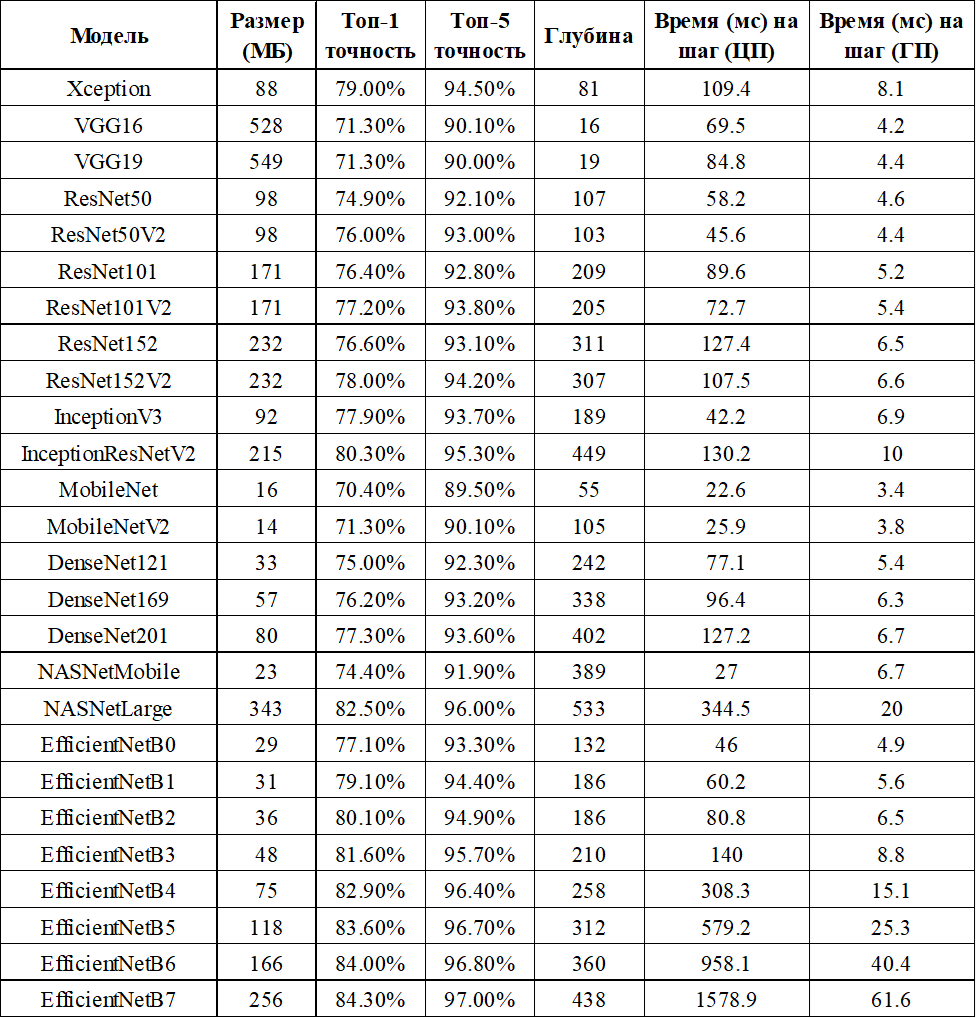
Все модели имеют разные параметры весов, которые загружаются автоматически при создании её экземпляра. Значения столбцов «Топ-1» и «Топ-5» являются результатами взаимодействия модели с набором данных ImageNet. В параметр «Глубина» входит количество слоёв активации, слоёв пакетной нормализации и т.п. Время загрузки и обучения модели зависит от её размера и глубины. Из этого списка мы выбрали модели InceptionV3 и VGG16, так как из предложенных вариантов именно они чаще всего используются для распознавания изображений, из-за чего они имеют подходящую нам архитектуру. Мы также выбрали классическую модель Sequential (её нет в этом списке), потому что она имеет возможность гибкой настройки под наши задачи.
2 СИСТЕМА ОБУЧЕНИЯ «С УЧИТЕЛЕМ»
Обучение с учителем — это направление МО, объединяющее алгоритмы и методы построения моделей на основе множества примеров, содержащих пары «известный вход — известный выход». Данную систему обучения также часто называют «контролируемым».
Сильные стороны МО с учителем — простота и лёгкость структуры. Такая система полезна при прогнозировании возможного ограниченного набора результатов, разделении данных на категории или объединении результатов двух других алгоритмов МО. Однако маркировка миллионов немаркированных наборов данных является сложной задачей [3].
Маркировка данных — это процесс категоризации входных данных с соответствующими им определёнными выходными значениями. Помеченные обучающие данные необходимы для обучения с учителем. Например, миллионы изображений яблок и бананов должны быть помечены словами «яблоко» или «банан». Это делается для того, чтобы НС могла использовать эти обучающие данные, чтобы угадывать название фрукта по его изображению [3].
Иными словами, чтобы алгоритм относился к обучению с учителем, он должен работать с примерами, которые содержат не только вектор независимых переменных (атрибутов, признаков), но и значение, которое должна выдавать модель после обучения (такое значение называется целевым).
Разность между целевым и фактическим выходами модели называется ошибкой обучения (невязкой, остатками), которая минимизируется в процессе обучения и выступает в качестве «учителя». Значение выходной ошибки затем используется для вычисления коррекций параметров модели на каждой итерации обучения. Общая схема алгоритма представлена на рисунке 1 [4].
Рисунок 1 – Общая схема системы обучения «с учителем»
В анализе данных МО используется в задачах классификации и регрессии. В первом случае в качестве целевой переменной используется метка класса, а во втором — числовая переменная целого или вещественного типа.
В настоящее время разработано большое число алгоритмов обучения с учителем, каждый из которых имеет свои сильные и слабые стороны. Не существует единого алгоритма , который лучше всего подходит для всех задач анализа.
К числу алгоритмов обучения с учителем для решения задач классификации относятся:
- деревья решений;
- машины опорных векторов;
- байесовский классификатор;
- линейный дискриминантный анализ;
- метод k-ближайших соседей.
Алгоритмами обучения с учителем для решения задачи регрессии являются:
- линейная регрессия;
- логистическая регрессия;
- нейронные сети.
Это деление является нестрогим поскольку, например, НС могут быть адаптированы для классификации, а некоторые виды деревьев решений позволяют производить численное предсказание [4].
3 выбранныЕ моделИ обучЕНИЯ ДЛЯ РАЗРАБОТКИ
СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ ПЕШЕХОДНОГО
ПЕРЕХОДА
3.1 Модель Sequential
Sequential — это последовательная модель, состоящая из простого стека слоёв, имеющих ровно один входной и один выходной тензоры. Теоретически, число скрытых слоёв может быть сколь угодно большим. Для описания такой модели как раз и применяется Sequential [5]. Главное её достоинство заключается в том, что её структуру можно гибко настраивать под различные задачи. Архитектура нашей модели содержит в себе:
1) Слой свёртки с размером ядра 3 × 3, 32 картами признаков и функцией активации;
2) Сжимающий слой (с функцией максимального сжатия (англ. Max Pooling));
3) Слой свёртки с размером ядра 3 × 3, 32 картами признаков и функцией активации;
4) Сжимающий слой (с функцией максимального сжатия (англ. Max Pooling));
5) Слой свёртки с размером ядра 3 × 3, 64 картами признаков и функцией активации;
6) Сжимающий слой (с функцией максимального сжатия (англ. Max Pooling));
7) Слой преобразования из двумерного в одномерное представление;
8) Полносвязный слой из 64 нейронов и с функцией активации;
9) Слой Dropout (для исключения «переобучения»);
10) Выходной слой из 1 нейрона и с функцией активации.
Слои с 1 по 6 используются для выделения важных признаков в изображении, а слои с 7 по 10 — для его классификации.
Основная идея модели Sequential заключается в простом расположении её слоёв в последовательном порядке, из-за чего она и называется Sequential (с англ. — последовательный).
В большинстве своём модель Sequential успешно используется в ГО, но она не подходит, если [6]:
- модель должна иметь несколько входов и/или несколько выходов;
- какой-либо из слоёв должен иметь несколько входов и/или несколько выходов;
- нужно сделать совместное использование слоёв;
- нужна нелинейная топология (например, остаточная НС или модель с несколькими ответвлениями).
3.2 Модель InceptionV3
InceptionV3 — свёрточная нейронная сеть (далее - СНС), которая обучена более чем на миллионе изображений базы данных ImageNet. Эта НС состоит из 50 слоёв и имеет 1000 категорий объектов для классификации, таких как клавиатура, мышь, карандаш т. д. Архитектура модели InceptionV3 изображена ниже на рисунке 2.
Рисунок 2 - Архитектура модели InceptionV3
Стоит сказать, что архитектура InceptionV3 является одной из версии семейства архитектур, основанных на совокупности базовых комбинаций фильтров. Схема этого базового Inception модуля изображена на рисунке 3. В данной версии снижение вычислительной сложности операции свёртки достигается за счёт замен фильтров, которые мы рассмотрим далее. Также стоит отметить, что одним из принципов построения архитектур СНС может являться исключение резкого снижения размерности представления данных, и зачастую для этого используются слои подвыборки. Однако при использовании слоёв подвыборки необходимо увеличивать глубину выходных данных в два раза за счёт использования дополнительной свёртки в глубину размерностью 1 × 1 [7].
Рисунок 3 - Базовый Inception модуль
При формировании модели InceptionV3 большой 5 × 5 свёрточный слой заменили на два последовательных слоя размером 3 × 3 [8]. Этот модуль (на рисунке 2 - Inception Module A) изображён на рисунке 4.
Рисунок 4 - Inception модуль после замены слоя 5 × 5 на два последовательных слоя размером 3 × 3
Далее, слой 3 × 3 заменили на 3 × 1 + 1 × 3. Процесс такой замены показана ниже на рисунке 5, а схема этого модуля (на рисунке 2 - Inception Module С) изображена на рисунке 6.
Рисунок 5 - Процесс замены слоя 3 × 3 на слои 3 × 1 + 1 × 3
Рисунок 6 - Inception модуль после замены слоёв 3 × 3 на слои 3 × 1 + 1 × 3
Затем, слои 3 × 1 + 1 × 3 заменяют на n × 1 + 1 × n. Итоговый Inception модуль (на рисунке 2 - Inception Module B) показан на рисунке 7.
Рисунок 7 - Inception модуль после замены слоёв 3 × 1 + 1 × 3 на слои n × 1 + 1 × n
Вместе с тем, для эффективного уменьшения размера сетки в InceptionV3 расширен размер активации сетевых фильтров. Авторы использовали гибридную схему — на одной половине блок свёртки (на рисунке 8 - Conv), а на другой половине блок объединения (на рисунке 8 - Pool). При такой схеме размер сетки уменьшается в 2 раза, а группы фильтров расширяются в 2 раза [8]. Эта гибридная схема изображена на рисунке 8.
Рисунок 8 - Уменьшение размера сетки при расширении групп фильтров
Компоненты, из которых состоит модель InceptionV3, представлены в таблице 2.
Подводя итог можно выделить следующие достоинства InceptionV3:
1) Обладает более высокой эффективностью;
2) Имеет более глубокую сеть по сравнению с предыдущими версиями;
3) Менее затратно подобных СНС в вычислительном отношении;
4) Веса для InceptionV3 меньше, чем у VGG16 и составляют 96 МБ;
5) Размер входного изображения составляет 299 × 299 пикселей, что больше, чем у VGG19.
Таблица 2 – Компоненты модели InceptionV3
3.3 Модель VGG16
VGG16 — модель СНС, предложенная Кареном Симоняном и Эндрю Зиссерманом из Оксфордского университета в статье «Very Deep Convolutional Networks for Large-Scale Image Recognition». Модель достигает точности 92.7% при тестировании на ImageNet в задаче распознавания объектов на изображении. Эта выборка состоит из более чем 14 миллионов изображений, принадлежащих к 1000 различным классам [9].
VGG16 — одна из самых знаменитых моделей, отправленных на соревнование ILSVRC-2014. Она является улучшенной версией AlexNet, в которой заменены большие фильтры (размерами 11 × 11 и 5 × 5 в первом и втором свёрточных слоях, соответственно) на несколько фильтров размера 3 × 3, следующих один за другим.
2D архитектура этой модели представлена ниже на рисунке 9, а более подробная 3D архитектура представлена на рисунке 10.
Рисунок 9 – 2Dархитектура VGG16
Рисунок 10 – 3D архитектура VGG16
На вход слоя Сonv1-1, изображённого на рисунке 9, подаются изображения размером 224 × 224. Далее изображения проходят через стек свёрточных слоёв (на рисунке 10 - convolution + ReLU), в которых используются фильтры с очень маленьким рецептивным полем размера 3 × 3 (который является наименьшим размером для получения представления о том, где находится право/лево, верх/низ, центр) [9].
После стека свёрточных слоёв идут три полносвязных слоя (на рисунке 10 - fully connected + ReLU): первые два имеют по 4096 каналов, третий — 1000 каналов. Так как в соревновании ILSVRC требовалось классифицировать объекты по 1000 категориям; следовательно, классу соответствовал один канал. Последним идёт, как показано на рисунке 10, softmax слой. Softmax — это то, насколько сеть уверена в том, что определённое изображение принадлежит к определённому классу [9].
Все скрытые слои снабжены функцией ReLU (англ. Rectified Linear Unit), которая возвращает 0, если она принимает отрицательный аргумент, и возвращает само число, если же аргумент положителен. К сожалению, модель VGG16 не содержит слоя нормализации (англ. Local Response Normalisation).
При этом VGG16 имеет два серьёзных недостатка:
1) Очень медленная скорость обучения;
2) Сама архитектура сети весит слишком много (появляются проблемы с пропускной способностью).
Из-за глубины и количества полносвязных узлов, VGG16 весит более 533 МБ. Это делает процесс её развёртывания утомительной задачей, поэтому меньшие архитектуры будут более предпочтительны, например, SqueezeNet или GoogLeNet. Однако, несмотря на эти недостатки, данная модель является отличным строительным блоком для обучения, так как её легко реализовать [9].
4 ФОРМИРОВАНИЕ И ПОДГОТОВКА ДАННЫХ ДЛЯ РАЗРАБОТКИ СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ
ПЕШЕХОДНОГО ПЕРЕХОДА
Для формирования общей выборки мы сделали 160 фотографий двух видов (с зеброй и без нее) на мобильные телефоны марок Apple и Xiaomi. Фотографии в ней мы разделили на два вида, по 80 штук в каждом. Далее, из общей выборки мы сформировали обучающую выборку объемом в 104 фотографии, которая содержит 52 изображения с пешеходной зеброй и 52 изображений без неё. Из остальных 56 фотографий мы составили контрольную выборку с папками по 28 изображений каждого вида. Схема формирования данных показана ниже на рисунке 11.
Рисунок 11 – Схема формирования обучающей и контрольной выборок
Поскольку все наши изображения имели разный размер, а также для входных данных они должны быть намного меньше, чем они были изначально, то мы их сжали до размера 225 × 225 пикселей. В качестве названия мы использовали схему «папка + .номер», например, «zebra.1» или «nezebra.4».
5 РАЗРАБОТКА СИСТЕМЫ РАСПОЗНАВАНИЯ НАЛИЧИЯ
ПЕШЕХОДНОГО ПЕРЕХОДА
5.1 Система распознавания образов
Распознавание образов — раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций, объектов, которые характеризуются конечным набором некоторых свойств и признаков. В данном случае нас интересует распознавание объектов.
Распознавание объектов — это метод компьютерного зрения для идентификации объектов на изображениях или видео. Распознавание объектов является основным результатом алгоритмов глубокого и машинного обучения. При просмотре фотографий или видео, человек может легко распознать людей, предметы, сцены и визуальные детали. Цель состоит в обучении компьютера делать то, что естественно для людей: достичь уровня понимания того, что содержит изображение [10].
Будем считать, что все объекты или явления разбиты на конечное число классов. Для каждого класса известно и изучено конечное число объектов — прецедентов. Задача распознавания состоит в том, чтобы отнести новый распознаваемый объект к какому-либо классу.
Задача распознавания объектов является основной в большинстве интеллектуальных систем. Рассмотрим примеры интеллектуальных компьютерных систем.
- символьное распознавание (буквы, цифры);
- машинное зрение;
- медицинская диагностика;
- распознавание речи;
- распознавание лиц;
- распознавание объектов (дорожных знаков, разметки, препятствий и т.д.) при автопилотировании транспорта.
При построении системы распознавания необходимо проанализировать информацию об объектах исследования и решить следующие вопросы:
1) Какими общими характеристиками и свойствами обладают объекты исследования и чем они различаются;
2) Если необходимые характеристики могут быть получены в результате измерений, какова точность этих измерений;
3) Существует ли подходящая модель (модели) для формального описания и анализа данных характеристик.
На основании проведённых исследований определяется тип и структура системы распознавания [11]. Ниже, на рисунке 12, представлена общая схема разработки системы распознавания объектов.
Рисунок 12 – Общая схема разработки системы распознавания объектов
Одной из задач распознавания образов является распознавание изображений, именно поэтому этот метод лёг в основу нашей системы распознавания наличия пешеходных переходов.
5.2 Система распознавания изображений
Распознавание изображений — информационная технология, созданная для получения и понимания фотографий реального мира, их преобразования в цифровую информацию для дальнейшей обработки и анализа. В эту область вовлечены ГО, расширение базы знаний, интеллектуальный анализ данных, распознавание образов [12].
В отличие от МО, где входные данные анализируются с помощью алгоритмов, в ГО используется многоуровневая НС. Здесь задействованы три типа слоёв: входной, скрытый и выходной. Ввод информации принимается входным слоем, обрабатывается скрытым слоем, а результаты генерируются выходным слоем. Пример такой НС показан на рисунке 13.
Рисунок 13 – Пример структуры многослойной НС
Поскольку все слои взаимосвязаны, каждый уровень зависит от результатов предыдущего слоя. Поэтому для обучения НС необходим огромный набор данных, чтобы система ГО склонялась к имитации процесса человеческого мышления и продолжала учиться [13].
На сегодняшний день лучшие результаты в распознавании изображений получают с помощью свёрточных нейронных сетей. В среднем точность распознавания таких сетей превосходит обычные ИНС на 10-15%. СНС — это ключевая технология ГО [12]. Более детальное описание НС этого типа будет представлено далее.
Алгоритм распознавания изображений (также известный как классификатор изображений) принимает изображение (или фрагмент изображения) в качестве входных данных и выводит то, что содержит изображение. Другими словами, вывод — это метка класса (например, «кошка», «собака», «таблица» и т.д.) [14].
5.3 Свёрточные нейронные сети в системе
распознавания изображений
Свёрточная нейронная сеть — специальная архитектура ИНС, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов. Она входит в состав технологий глубокого обучения [14].
СНС обеспечивают некоторую устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям. Этот вид НС объединяют три архитектурных идеи, для обеспечения инвариантности к этим видам искажений:
1) Локальные рецепторные поля (обеспечивают локальную двумерную связность нейронов);
2) Общие синаптические коэффициенты (обеспечивают детектирование некоторых черт в любом месте изображения и уменьшают общее число весовых коэффициентов);
3) Иерархическая организация с пространственными подвыборками.
На данный момент СНС и её модификации считаются лучшими по точности и скорости алгоритмами нахождения объектов на изображениях или видео. Начиная с 2012 года, этот тип нейросетей занимает первые места на известном международном конкурсе по распознаванию образов ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [16].
Главной особенностью СНС является «свёртка». Суть этой операции состоит в том, что каждый фрагмент изображения умножается на ядро — матрицу весовпоэлементно, после чего результат суммируется и записывается в аналогичную позицию выходного изображения. Таким образом, изображение, свёрнутое с неким ядром, даст нам уже другое изображение, каждый пиксель которого будет означать степень похожести фрагмента изображения на фильтр. Ниже, на рисунке 14 показан пример такой операции.
Рисунок 14 - Пример свёртки двух матриц размера 5 × 5 и 3 × 3
СНС состоит из трёх основных видов слоёв, изображённых на рисунке 15:
1) Свёрточные слои (convolutional);
2) Субдискретизирующие слои (pooling);
3) Полносвязный слой (full connection).
Рисунок 15 -Архитектура свёрточной нейронной сети
Первый слой СНС (на рисунке 15 - Input) принимает все пиксели изображения. После того, как все данные введены в сеть, к изображению применяются различные фильтры, которые формируют понимание различных частей изображения. Это извлечение признаков, которое создает «карты признаков». Этот процесс извлечения признаков из изображения выполняется с помощью свёрточного слоя (на рисунке 15 - Conv). Операция свёртки просто формирует представление части изображения [17].
Размер фильтра влияет на то, сколько пикселей проверяется за один раз. Общий размер фильтра равен 3, и он охватывает как высоту, так и ширину, поэтому фильтр проверяет область пикселей 3 × 3.
В то время как размер фильтра покрывает высоту и ширину фильтра, глубина фильтра также должна быть указана. Дело в том, что цифровые изображения отображаются в виде высоты, ширины и некоторого значения RGB (англ. Red, Green, Blue), которое определяет цвет пикселя, поэтому отслеживаемая «глубина» — это количество цветовых каналов, которые имеет изображение. Изображения в градациях серого (бесцветные) имеют только 1 цветной канал, в то время как цветные изображения имеют глубину в 3 канала. Это означает, что для фильтра размером в 3, примененного к полноцветному изображению, итоговые размеры этого фильтра будут 3 × 3 × 3 [17].
Для каждого пикселя, охватываемого этим фильтром, сеть умножает значения фильтра на значения самих пикселей, чтобы получить числовое представление этого пикселя. Затем этот процесс выполняется для всего изображения, чтобы получить полное представление. Фильтр перемещается по остальной части изображения в соответствии с параметром, называемым «шаг», который определяет, на сколько пикселей должен быть перемещен фильтр после того, как он вычислит значение в своей текущей позиции. Обычный размер шага равняется двум [17].
Конечным результатом всех этих расчётов является карта признаков. Этот процесс обычно выполняется с несколькими фильтрами, которые помогают сохранить сложность изображения.
После того, как карта признаков изображения была создана, значения, представляющие изображение, передаются через функцию активации. Функ-
ция активации принимает эти значения, которые благодаря свёрточному слою находятся в линейной форме (то есть просто список чисел) и увеличивает их нелинейность, поскольку сами изображения являются нелинейными. Типичной функцией активации, используемой для достижения этой цели, является выпрямленная линейная единица (англ. ReLU) [17].
После активации данные отправляются через объединяющий слой (на рисунке 15 - Pool). Объединение «упрощает» изображение: берёт информацию, которая представляет изображение, и сжимает её. Процесс объединения делает сеть более гибкой и способной лучше распознавать объекты и изображения на основе соответствующих функций [17].
Поскольку сеть должна принимать решения относительно наиболее важных частей изображения, расчёт идёт на то, что она изучит только те части
изображения, которые действительно представляют суть рассматриваемого объекта. Это помогает предотвратить «переобучение» — когда сеть слишком хорошо изучает все аспекты учебного примера и уже не может обобщать новые данные, поскольку учитывает нерелевантные отличия [17].
Существуют различные способы объединения значений, но чаще всего используется максимальное объединение (англ. Max Pooling). Максимальное объединение подразумевает взятие максимального значения среди пикселей в пределах одного фильтра (в пределах одного фрагмента изображения). Это отсеивает информации, при условии использования фильтра размером 2 × 2. Пример выполнения такого вида объединения изображён на рисунке 16.
Рисунок 16 - Формирование новой карты на основе предыдущей карты с помощью Max Pooling
Максимальные значения пикселей используются для того, чтобы учесть возможные искажения изображения, а количество параметров (размер изображения) уменьшены, чтобы контролировать переобучение. Существуют и другие принципы объединения, такие как среднее (англ. Average Pooling) или суммарное объединение (англ. Total Pooling), но они используются не так часто, поскольку максимальное объединение даёт наибольшую точность [17].
Конечные слои СНС представляют собой плотно связанные слои (на рисунке 15 - FC) или ИНС. Основной функцией ИНС является анализ входных признаков и объединение их в различные атрибуты, которые помогут в классификации. Эти слои образуют наборы нейронов, которые представляют различные части рассматриваемого объекта, а набор нейронов может представлять собой, например, висячие уши собаки или красноту яблока. Когда достаточное количество этих нейронов активируется в ответ на входное изображение, то оно будет классифицировано как объект. Пример структуры ИНС изображён ниже на рисунке 17.
Рисунок 17 - Пример структуры ИНС
Ошибка или разница между рассчитанными значениями и ожидаемым значением в обучающем наборе рассчитывается с помощью ИНС. Затем сеть подвергается методу обратного распространения ошибки, где рассчитывается влияние данного нейрона на нейрон в следующем слое и затем его влияние (вес) корректируется. Это сделано для оптимизации производительности модели. Этот процесс повторяется снова и снова: так сеть обучается на данных и изучает связи между входными признаками и выходными классами [17].
Нейроны в средних полносвязных слоях будут выводить двоичные значения, относящиеся к возможным классам. Если у вас есть 4 класса (например, собака, машина, дом и человек), нейрон будет иметь значение «1» для класса, который представляет изображение, и значение «0» для других классов.
Конечный полносвязный слой (на рисунке 15 - Output), получив выходные данные предыдущего слоя, присваивает вероятность каждому из классов в пределах единицы (в совокупности). Если категории «собака» присвоено значение 0.75 — это означает 75% вероятность того, что изображение является собакой.
6 АНАЛИЗ РЕЗУЛЬТАТОВ СИСТЕМЫ РАСПОЗНАВАНИЯ
НАЛИЧИЯ ПЕШЕХОДНОГО ПЕРЕХОДА
6.1 Анализ качества обучения системы
распознавания наличия пешеходного перехода
В процессе обучения нейросеть выводит данные об обучении и распознавании контрольной выборки. Мы использовали их для анализа результатов нашей системы распознавания. Результаты качества обучения всех трёх моделей представлены в таблице 3, а скриншоты процесса и результатов обучения для каждой модели представлены в приложении А.
Таблица 3 - Результаты качества обучения
Анализируя результаты, можно сделать вывод, что все 3 модели имеют очень высокую или 100% оценку обучения.
6.2 Анализ качества распознавания системы
распознавания наличия пешеходного перехода
Для анализа качества распознавания мы использовали контрольную выборку. Оценки распознавания для каждой модели будет представлены в таблице 4. Изображения, которые не распознали наши нейросети, будут показаны в приложении Б.
Таблица 4 - Результаты распознавания
Таким образом, можно увидеть, что наилучшие результаты показали модели InceptionV3 и VGG16. Они наравне друг с другом — 96.4%. Однако обучение и тестирование модели VGG16 заняло много времени, поскольку она достаточно много весит, так что модель InceptionV3 в этом плане показала себя лучше VGG16.
Программный код модели Sequential представлен в приложении В, модели InceptionV3 — в приложении Г, а модели VGG16 — в приложении Д.
ЗАКЛЮЧЕНИЕ
Проанализировав результаты исследования, целью которого являлось обучить три модели нейронной сети для разработки системы распознавания наличия пешеходного перехода при помощи языка программирования Python, мы выбрали модель InceptionV3 из-за следующих её качеств: быстрого обучения, малого объёма памяти, высокого качества распознавания и оптимальности работы.
В начале работы мы составили общую выборку и изучили метод глубокого обучения «с учителем» на языке программирования Python, что позволило больше узнать об этом виде обучения и правильно его использовать в процессе разработки программ обучения для наших моделей.
В середине работы был проведён анализ существующих моделей в библиотеке Keras. Также были выбраны и детально изучены три выбранные нами модели. Далее, мы подробно рассмотрели принцип работы свёрточных нейронных сетей и систем распознавания образов, а также изображений, для написания программного кода к каждой модели.
В конце работы мы обучили и протестировали все три наши модели: Sequential, InceptionV3, VGG16. Мы проанализировали результаты обучения и распознавания, определив наилучшую модель.
В процессе работы нами были освоены такие библиотеки языка программирования Python, как Keras и Matplotlib. Мы научились с ними работать и применять их в глубоком обучении.
Таким образом, после изучения и применения на практике теоретических материалов, каждый из нас самостоятельно обучил нейронную сеть распознаванию наличия пешеходного перехода на изображении и овладел навыками глубокого обучения на языке программирования Python.
Такие системы распознавания, как наша, могут использоваться в разработке автопилотирования в различных видах транспорта (например, Tesla), для соблюдения правил дорожного движения.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1 Keras [Электронный источник]. – 2018. – URL: https://blog.skillfactory.ru/glossary/keras/ (дата обращения: 02.03.2023).
2 Абрагин А.В. Перспективы развития и применения нейронных сетей//Современные проблемы науки и образования. – 2015. – N 12. – С. 12-15.
3 Что такое машинное обучение? [Электронный ресурс]. – 2021. – URL: https://aws.amazon.com/ru/what-is/machine-learning/ (дата обращения: 07.03.2023).
4 Обучение с учителем (Supervised learning) [Электронный ресурс]. – 2019. – URL: https://wiki.loginom.ru/articles/supervised-learning.html (дата обращения: 06.03.2023).
5 Keras –последовательная модель Sequential[Электронный ресурс]. – 2021. – URL: https://proproprogs.ru/tensorflow/keras-posledovatelnaya-model-sequential (дата обращения: 06.03.2023).
6 The Sequential model [Электронный ресурс]. – 2020. – URL: https://tensorflow.rstudio.com/guides/keras/sequential_model (дата обращения: 06.03.2023).
7 Каздорф С.Я., Першина Ж.С. Архитектура свёрточной нейронной сети для классификации типов сцен мобильного робота//Современные наукоемкие технологии. – 2018. – N 10. – С. 32-37.
8 Эволюция нейросетей для распознавания изображений в Google: InceptionV3 [Электронный ресурс]. – 2016. – URL: https://habr.com/ru/post/302242/ (дата обращения: 05.06.03).
9 Муаль М. Н. Б. Использование предобученной нейросети (VGG16) для решения задачи переноса стиля изображения//Modern Information Technologies and IT-Education. – 2022. – Vol. 18, No. 2. P. 241-248.
10 Object Recognition. 3 things you need to know [Электронный ресурс]. – 2020. – URL: https://ch.mathworks.com/solutions/image-video-processing/object-recognition.html (дата обращения: 04.03.2023).
11 Чабан Л.Н., Теория и алгоритмы распознавания образов. Учебное пособие. – М.: МИИГАиК, 2004. – 70 с.
12 Система распознавания изображений [Электронный ресурс]. – 2021. – URL: https://polygant.net/ru/ai/sistema-raspoznavaniya-izobrazhenij/ (дата обращения: 03.03.2023).
13 Что такое распознавание изображений AI и как оно работает? [Электронный ресурс]. – 2022. – URL: https://ru.shaip.com/blog/what-is-ai-image-recognition-and-how-does-it-work/ (дата обращения: 04.03.2023).
14 Image Recognition and Object Detection : Part 1 [Электронный ресурс]. – 2016. – URL: https://learnopencv.com/image-recognition-and-object-detection-part1/ (дата обращения: 04.03.2023).
15 Lecun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., Jackel, L. D. Backpropagation applied to handwritten zip code recognition//Neural Computation. – 1989. – Vol. 1, No. 4. P. 541-551.
16 Сверточная нейронная сеть, часть 1: структура, топология, функции активации и обучающее множество. [Электронный ресурс]. – 2018. – URL: https://habr.com/ru/post/348000/ (дата обращения: 05.03.2023).
17 Распознавание изображений на Python с помощью Tensorflow и Keras [Электронный ресурс]. – 2020. – URL: https://evileg.com/ru/post/619/ (дата обращения: 06.03.2023).
ПРИЛОЖЕНИЕ А
Рисунок A.1 – Результаты процесса обучения для модели Sequential («accuracy» – точность на обучающей выборке, а «val_accurancy» – точность распознавания контрольной выборки)
Рисунок A.2 – Результаты процесса обучения для модели InceptionV3 («accuracy» – точность на обучающей выборке, а «val_accurancy» – точность распознавания контрольной выборки)
Рисунок A.3 – Результаты процесса обучения для модели VGG16 («accuracy» – оценка обучения, а «val_accurancy» – оценка распознавания контрольной выборки)
ПРИЛОЖЕНИЕ Б
Рисунок Б.1 – Неправильно распознанные моделью Sequential изображения с зеброй
Рисунок Б.2 – Неправильно распознанные моделью Sequential изображения без зебры
Рисунок Б.3 – Неправильно распознанные моделью InceptionV3 изображения с зеброй
Рисунок Б.4 – Неправильно распознанные моделью VGG16 изображения без зебры
ПРИЛОЖЕНИЕ В
from keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Conv2D, MaxPooling2D
from tensorflow.python.keras.layers import Activation, Dropout, Flatten, Dense
import matplotlib.pyplot as plt
import keras.utils as image
from os import listdir
#Иван Скорский - УИБ-213
def result(dir, true, false, model): #функция, выводящая результат распознавания каждого изображения в каждой папке контрольной выборки
img_dir = listdir(dir) #применение функции listdir из пакета os для перебора файлов
for file in img_dir: #цикл перебора файлов
img = image.load_img(dir+"/"+file, target_size=(225, 225)) #загружаем изображение
x = image.img_to_array(img)
x = x.reshape(1,225, 225, 3)
x /= 255
prediction = model.predict(x) #распознавание изображения нейросетью
if (prediction[0][0]<(0.5)):#оценка распознавания
show(false, prediction[0][0], img) #вывод в неправильном случае
else:
show(true, prediction[0][0], img) #вывод в правильном случае
def show(title, pred, img): #функция показа результата распознавания
plt.imshow(img.convert('RGBA'))
plt.title(title + str(pred)) #установка названия
plt.show() #показ результата
#каталог с данными для обучения
train_dir = 'train'
#каталог с данными для тестирования
test_dir = 'test'
#размеры изображения
img_width, img_height = 225, 225
#размерность тензора на основе изображения для входных данных в нейронную сеть
#backend Tensorflow, channels_last
input_shape = (img_width, img_height, 3)
#количество эпох
epochs = 25
#размер мини-выборки
batch_size = 4
#количество изображений для обучения
nb_train_samples = 104
#количество изображений для тестирования
nb_test_samples = 56
#accuracy - обучающий набор данных
#val_accuray - проверочный набор данных
model = Sequential()
#начало каскада свертки
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#конец каскада свертки
#полносвязная часть необходимая для классификации
model.add(Flatten())#слой преобразует двухмерный вывод, который мы получаем из слоя MaxPooling в одномерный вектор
model.add(Dense(64))#полносвязный слой, в котором 64 нейрона
model.add(Activation('relu'))#функция активации полулинейная
model.add(Dropout(0.5))#слой для регуляризации и предотвращения переобучения
model.add(Dense(1))#выходной слой, который содержит 1 нейрон с сигмоидальной функцией активации(2 значения 0 и 1(зебра или не зебра)
model.add(Activation('sigmoid'))
#компиляция сети
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
datagen = ImageDataGenerator(rescale=1. / 225)#обеспечение загрузки данных и их преобразования(делим каждый пиксель на изображения размерностью 225)
#генераотр данных для обучения на основе изображений из каталога
train_generator = datagen.flow_from_directory( #загрузка изображения из каталога
train_dir,#каталог
target_size=(img_width, img_height),#размер изображения
batch_size=batch_size,#размер выборки(кол-во изображений которые будут прочитаны за один раз)
class_mode='binary')
#генератор данных для тестирования на основе изображений из каталога
test_generator = datagen.flow_from_directory(
test_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
model.fit_generator(#данные мы берем от генераторов
train_generator,
steps_per_epoch=nb_train_samples // batch_size,#общее кол-во изображений, делённое на количество изображений
epochs=epochs,#кол - во эпох(16 - 25)
validation_data=test_generator,
validation_steps=nb_test_samples // batch_size)#сколько раз мы обращаемся к проверочному генератору
scores = model.evaluate_generator(test_generator, nb_test_samples // batch_size)
print("Accuracy: ",scores[1])
result('test/zebra', "Зебра -> ", "Не зебра -> ", model)
result('test/nezebra', "Зебра -> ", "Не зебра -> ", model)
ПРИЛОЖЕНИЕ Г
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
from keras.applications import InceptionV3
import matplotlib.pyplot as plt
import keras.utils as image
from os import listdir
#Полина Миронова - УИБ-213
def result(dir, true, false, model): # функция, выводящая результат распознавания каждого изображения в каждой папке контрольной выборки
img_dir = listdir(dir) # применение функции listdir из пакета os для перебора файлов
for file in img_dir: # цикл перебора файлов
img = image.load_img(dir+"/"+file, target_size=(225, 225)) # загружаем изображение
x = image.img_to_array(img)
x = x.reshape(1,225, 225, 3)
x /= 255
prediction = model.predict(x) # распознавание изображения нейросетью
if (prediction[0][0]<(0.5)): # оценка распознавания
show(false, prediction[0][0], img)
else:
show(true, prediction[0][0], img)
def show(title, pred, img): # функция показа результата распознавания
plt.imshow(img.convert('RGBA'))
plt.title(title + str(pred))
plt.show()
train_path = 'train' # путь для обучающей выборки
test_path = 'test' # путь для контрольной выборки
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
batch_size = 5 # размерность подвыборки
img_width, img_height = 225, 225 # размерность тензора на основе изображения для входных данных в нейронную сеть
train_generator = train_datagen.flow_from_directory(train_path, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') # генератор для обучения
test_generator = test_datagen.flow_from_directory(test_path, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary') # генератор для тестирования на контрольной выборке
inception = InceptionV3(include_top=False, input_shape=(img_width, img_height, 3)) # импорт модели InceptionV3
for layer in inception.layers:
layer.trainable = False # игнорируем слой для классификации изображений на ILSVRC
model = Sequential() # немного модифицируем нашу модель, добавляя несколько дополнительных слоёв
model.add(inception)
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
epochs = 20 # устанавливаем кол-во эпох - 20
steps_per_epoch = train_generator.n // train_generator.batch_size # устанавливаем размеры шагов для обучения сети и распознавания контрольной выборки
validation_steps = test_generator.n // test_generator.batch_size
model.fit(train_generator, epochs=epochs, steps_per_epoch=steps_per_epoch, validation_data=test_generator, validation_steps=validation_steps)
accuracy = model.evaluate(test_generator)
print("Accuracy = ", accuracy[1])
result('test/zebra', "Зебра -> ", "Не зебра -> ", model)
result('test/nezebra', "Зебра -> ", "Не зебра -> ", model)
ПРИЛОЖЕНИЕ Д
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.applications import VGG16
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import keras.utils as image
from os import listdir
def result(dir, true, false, model): #функция, выводящая результат распознавания каждого изображения в каждой папке контрольной выборки
img_dir = listdir(dir)
for file in img_dir: #перебор файлов в папке
img = image.load_img(dir+"/"+file, target_size=(225, 225)) #загрузка изображения
x = image.img_to_array(img)
x = x.reshape(1,225, 225, 3)
x /= 255
prediction = model.predict(x) #обработка нейросетью
if (prediction[0][0]<(0.5)): #вывод результата в зависимости от успешности распознавания
show(false, prediction[0][0], img)
else:
show(true, prediction[0][0], img)
def show(title, pred, img): #функция показа результата распознавания с помощью библиотеки matplotlib
plt.imshow(img.convert('RGBA'))
plt.title(title + str(pred))
plt.show()
train_dir = 'train' #установка путей к обучающей и контрольной выборкам
test_dir = 'test'
img_width, img_height = 225,225 #размеры для изображений
input_shape = (img_width, img_height, 3)
batch_size = 5 #размер мини-выборки
nb_train_samples=104 #количество изображений для обучения
nb_test_samples = 56 #количество изображений для распознавания
vgg16_net = VGG16(weights='imagenet', include_top=False, input_shape=(225,225, 3)) #импорт модели VGG16
vgg16_net.trainable = False #игнорирование тренировки на ImageNet
vgg16_net.summary()
model = Sequential() #немного кастомизируем модель VGG16, добавляя некоторые слои
model.add(vgg16_net)
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.summary()
model.compile(loss='binary_crossentropy',
optimizer=Adam(lr=1e-5),
metrics=['accuracy'])
datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = datagen.flow_from_directory( #обучающий генератор
train_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
test_generator = datagen.flow_from_directory( #генератор для тестов
test_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
model.fit_generator(
train_generator,
steps_per_epoch=nb_train_samples // batch_size,
epochs=30,
validation_data=test_generator,
validation_steps=nb_test_samples // batch_size)
accuracy = model.evaluate(test_generator)
print("Результат: ", accuracy[1])
result('test/zebra', "Зебра -> ", "Не зебра -> ", model) #выводим результат распознавания изображений из обоих папок тестовой выборки
result('test/nezebra', "Не зебра -> ", "Зебра -> ", model)