В мире все взаимосвязано и мы — часть этого круговорота. А потому в Мировом Древе нигде не может быть одиноко торчащей ветки: где-то и она связана с какой-то другой ветвью (Брайанна Рид).
Раскрываемый в статье метод более универсален, чем многие другие, так как позволяется вычислять взаимосвязи между различными типами признаков (категориальными, непрерывными и их комбинациями), в нем используются передовые статистические методики и его легко применить с библиотекой phik.
Суть метода базируется на подсчете хи-квадрат статистики, затем ее трансформации в нечто подобное коэффициенту корреляции только на отрезке от 0 (нулевая взаимосвязь) до 1 (максимальная взаимосвязь). С этой целью разработчики считают аналогичную хи-квадрат статистику для различных значений корреляции p случайных величин из двумерного нормального распределения. Опуская нюансы, возвращается p двумерного распределения, соответствующее найденной хи-квадрат статистике между заданными признаками.
Для нахождения хи-квадрат статистики двумерного распределения значения разбиваются на площади, где для каждой находится совместная вероятность путем интегрирования плотности распределения:
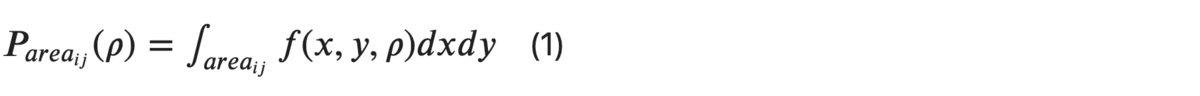
Затем статистику хи-квадрат для заданного коэффициента взаимосвязи считают так:
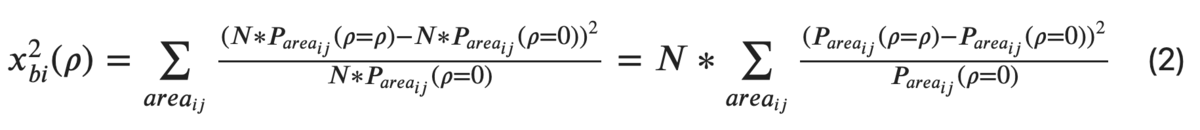
Эта формула аналогична определению хи-квадрат статистики, о которой я рассказывал ранее (сумме квадратов разности между наблюдаемым и ожидаемым количеством точек в заданной области, деленных на ожидаемое количество в заданной области). То есть функция (2) позволяет по p найти хи-квадрат для двумерного нормального распределения.
Еще нам понадобится способ отображения (2) на диапазон значений хи-квадрат величин для исследуемых переменных. Этот способ базируется на статистической оценке минимальных и максимальных хи-квадрат значений, исходя из характеристик распределения - параметров таблицы совместной встречаемости, количестве исследуемых точек (N). В результате устанавливается следующее соответствие:
Для потенциальных хи-квадрат исследуемых переменных меньше оцененного минимума считаем p=0, остальные значения возрастают вплоть до посчитанного максимума (с увеличением p до 1):
Имея функцию (2), мы можем найти такое значение p, при котором масштабированная к заданному диапазону (3), становится равной наблюдаемому значению. Эта задача решается путем нахождения корня на отрезке от 0 до 1 для функции:
Резюмируя, алгоритм подсчета p=phi_k следующий:
- Непрерывные признаки разбиваются на n равных отрезков (по умолчанию n=10);
- Составляется таблица совместной встречаемости признаков и считаются ее показатели - хи-квадрат статистика, степени свободы, параметры таблицы;
- Решается задача нахождения p двумерного нормального распределения на отрезке от 0 до 1, для которого масштабированная величина хи-квадрат (3) совпадает с полученной на предыдущем шаге. Результат принимается равным phi_k .
Теперь рассмотрим, как считать коэффициенты на практике. Для этого сгенерируем набор данных о продажах авто в трех областях с заданными вероятностями и ценами:
Коэффициенты взаимосвязи считаются путем вызова метода phik_matrix:
Таблица отражает взаимосвязь между признаками, которую мы установили при генерации данных.
Непрерывные признаки разбиваются по бинам (по умолчанию на 10 равномерных частей). Однако это можно регулировать с аргументами interval_cols, в котором задается список колонок, и словаря bins, задающего для колонки число бинов или список границ:
df.phik_matrix(interval_cols=['cost'], bins={'cost':5})
С методом hist2d можно построить таблицу совместной встречаемости, на базе которой считается хи-квадрат статистика и коэффициент phi_k для пары признаков:
Для сверки ее аналог можно получить вручную так:
Для демонстрации качества нового подхода выведем коэффициент корреляции Пирсона между действительной переменной и ее квадратом, а также значение зависимости, устанавливаемое phik:
Как можно заметить, во втором случае связь диагностируется, в то время как корреляция Пирсона выводит близкое к нулю значение (разбирал ранее).