«Яндекс» начал нанимать людей гуманитарных профессий для обучения своей LLM YaLM 2.0 — российского аналога ChatGPT.
Короткий ответ зачем и почему кроется в аббревиатуре (RLHF) Reinforcement Learning from Human Feedback. Обучение с подкреплением на основе обратной связи с человеком расскажу что это, и стоит ли вкатываться в AI-тренера.
Искусственный интеллект (ИИ) может выполнять различные задачи, связанные с языком, такие как ведение диалога, или составление краткого содержания. Но как ИИ узнает, как правильно говорить или писать?
Одним из способов обучения ИИ является обучение с подкреплением (RL) . Это метод, при котором ИИ получает награду или штраф за свои действия в зависимости от того, насколько они хороши или плохи для достижения цели. Например, если ИИ хочет выиграть в шахматы, он получает награду за каждый ход, который приближает его к победе, и штраф за каждый ход, который отдаляет его от нее. Таким образом, ИИ учится выбирать лучшие ходы.
Но есть проблема. Как определить, насколько хороши или плохи действия ИИ в задачах, связанных с языком? Как измерить качество диалога? Как учесть разные цели, ситуации и предпочтения людей? Насколько языковая модель следует за инструкцией?
Для этого нужна функция награды — правило, которое говорит ИИ, сколько очков он получает за каждое действие. Но придумать такую функцию очень сложно и дорого.

Поэтому применяется другой способ — обучение с подкреплением от человеческой обратной связи (RLHF). Это метод, при котором ИИ не получает награду или наказание за свои действия напрямую, а спрашивает людей о своем мнении. Люди могут сказать ИИ, какие из его действий им нравятся больше или меньше. С помощью подобного выравнивания (Aligning) модель показывает значительно лучшие результаты.
OpenAI полностью оправдывает свое название Отрытый ИИ и предоставляет крайне мало информации о способах точной настройки GPT. Но совершено точно известно, что RLHF использовалось для превращения GPT-3 в InstructGPT.
И известно, что работа AI-тренера заключалась в ранжировании ответов языковой модели в соответствии критериями на 5 классов. Примеры ниже
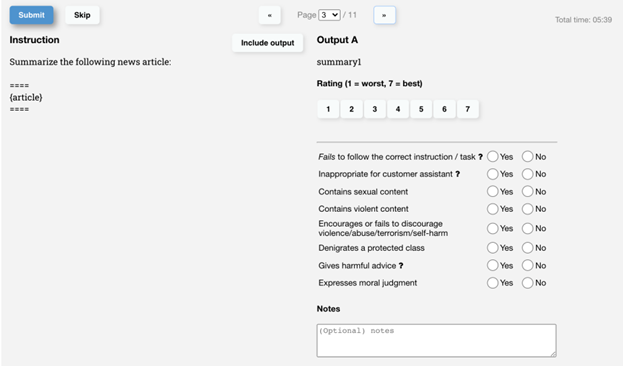
и вот так
Является ли работа AI-тренером самым простым способом вкатиться в ИТ?
Не обязательно, но я уверен в том, что люди первыми освоившие работу с генеративным ИИ получат читерский буст в продуктивности и творчестве. И вовсе не ИИ лишит вас работы, а человек умеющий им пользоваться эффективнее вас. Поэтому AI-тренер как и профессия Промт-инженера — это профессии будущего.
Помимо этого в группе AI тренеров должны быть представлены эксперты с разными областями знаний и опытом, связанными с темой или задачей, для которой обучается LLM модель. Ведь это позволит обеспечить, адекватную оценку модели, конструктивную обратную связь и лучшее выравнивание (aligning) модели под любой запрос.