Строка — это набор символов, представляющих текстовую информацию. Строки в Python являются неизменяемыми объектами, что означает, что после создания строки ее нельзя изменить.
Строки являются одним из наиболее распространенных типов данных в Python и используются для хранения и обработки текстовой информации во многих приложениях, таких как:
- Обработка текстовых файлов, например, для чтения и записи данных.
- Работа с пользовательским вводом, например, при вводе имени или адреса электронной почты.
- Создание и форматирование текстовых сообщений, например, для отправки по электронной почте или SMS.
- Работа с базами данных, где данные хранятся в виде строк.
- Обработка и анализ данных, содержащих текстовую информацию, например, анализ отзывов пользователей на товары или услуги.
В работе с строками в Python используются различные операции и методы для выполнения задач, таких как:
- Получение длины строки.
- Извлечение подстроки из строки.
- Поиск символов и подстрок в строке.
- Замена символов и подстрок в строке.
- Разделение строки на части и объединение строк в одну.
- Форматирование строк для вывода информации в нужном виде.
Примеры задач, где необходима работа со строками:
- Поиск и замена подстроки в тексте — для обработки больших объемов текстовой информации, например, для замены определенного слова в тексте на другое или для поиска всех вхождений слова в тексте.
- Разбиение строки на подстроки — для анализа данных, содержащих список значений, разделенных запятыми или другими символами.
- Валидация пользовательского ввода — для проверки, соответствует ли введенное пользователем значение формату строки, например, для проверки правильности ввода адреса электронной почты или номера телефона.
- Форматирование текстовых сообщений — для вывода информации в нужном формате, например, для создания уведомлений или сообщений об ошибках.
- Обработка текстовых файлов — для чтения и записи данных в текстовых файлах, например, для создания отчетов или обработки данных в формате CSV.
Запись строк
В Python строки могут быть записаны в кавычках одного из трех типов: одинарных кавычек ('), двойных кавычек (") и тройных кавычек (''' или """). Использование тройных кавычек позволяет записывать многострочные строки.
Примеры записи строк:
# Одинарные кавычки string_1 = 'Это строка, записанная в одинарных кавычках'
# Двойные кавычки string_2 = "Это строка, записанная в двойных кавычках"
# Тройные кавычки string_3 = '''Это многострочная
строка, записанная в тройных
кавычках'''
Специальные символы в Python. Как сделать принудительный перевод строки.
Также можно использовать обратный слеш (\) для записи специальных символов, таких как перевод строки (\n), табуляция (\t), кавычки и т.д.
Примеры:
# Использование обратного слеша для записи специальных символов string_4 = 'Это строка с переводом\nстроки' string_5 = "Это строка с табуляцией\tвнутри"
# Использование обратного слеша для записи кавычек string_6 = "Это строка со \"знаками\" кавычек" string_7 = 'Это строка с \'одинарными\' кавычками'
Какие кавычки лучше использовать: одинарные или двойные?
Разница между одинарными (') и двойными (") кавычками при записи строк в Python заключается только в способе записи кавычек внутри строки.
Если строка записана в одинарных кавычках, то внутри строки можно использовать двойные кавычки без необходимости экранировать их обратным слешем (\), и наоборот.
Пример:
string_1 = 'Это строка с "двойными" кавычками' string_2 = "Это строка с 'одинарными' кавычками"
Строковые операторы
Строковые операторы — это операторы, которые могут быть применены к строкам в Python и позволяют производить над ними различные операции.
Список строковых операторов в Python:
- +: объединение строк
- *: повторение строки
- %: форматирование строк
- in: вхождение подстроки в строку
Примеры использования строковых операторов на реальных задачах:
Конкатенация (слияние) строк
Достигается с помощью оператора `+`
# объединяем две строки first_name = 'John' last_name = 'Doe' full_name = first_name + ' ' + last_name
print(full_name) # John Doe
Повторение строки
# повторяем строку три раза message = 'Python is great!' triple_message = message * 3
print(triple_message) # Python is great!Python is great!Python is great!
Форматирование строки
Форматирование позволяет отобразить строку в определенном виде. Подробно, о форматировании строк, я расскажу далее по тексту, а пока небольшой пример.
# выводим информацию о продукте product_name = 'Кофеварка' product_price = 1999.99
info = 'Название: %s, Цена: %.2f руб.' % (product_name, product_price)
print(info) # Название: Кофеварка, Цена: 1999.99 руб.
В данном примере в текст info подставляется значение переменных product_name и product_price, причем цена округляется до 2 знаков после запятой.
Операторы in, not in
Операторы in и not in позволяют проверить, содержится ли подстрока в строке или нет. Они возвращают логическое значение True или False (Истина или Ложь).
Оператор in используется, чтобы проверить, содержится ли подстрока в строке:
text = "Hello, world!" substring = "world"
if substring in text: print("Substring found!") else: print("Substring not found!")
Задания для закрепления строковых операторов
Задание 1. Написать программу, которая спрашивает у пользователя его имя и фамилию, а затем выводит приветствие вида «Привет, Имя Фамилия!» с использованием оператора +.
Решение
Задание 2. Написать программу, которая спрашивает у пользователя слово и повторяет его три раза через пробел с использованием оператора *
Решение
Срезы и индексы
Срезы (slicing) и индексы позволяют получить часть строки, выбрав определенный диапазон символов.
Индексы элементов строк
Индексы используются для доступа к отдельным символам строки в Python.
Индексация (нумерация) начинается с 0, то есть первый символ имеет индекс 0, второй — индекс 1 и т.д. Отрицательные индексы начинаются с -1, то есть последний символ имеет индекс -1, предпоследний — индекс -2 и т.д.
Пример: Получение символа по индексу (номеру)
my_string = "Hello, world!" # Получение символа по индексу first_char = my_string[0] last_char = my_string[-1] print(first_char) # 'H' print(last_char) # '!'
В данном примере, мы получаем первый и последний символ строки Hello, world! Первый элемент имеет индекс (номер) 0, а последний -1 (минус 1). Также, можно обратиться к последнему элементу, указав индекс 12, а к первому -13 (минус 13)
Важно помнить, что строки в Python являются неизменяемыми объектами. Это означает, что если вы попытаетесь изменить символ в строке, вы получите ошибку. Однако вы можете получать подстроки из строки с помощью индексов и срезов
my_string = "Hello, world!" # Изменение символа по индексу my_string[0] = 'h' # Ошибка! Строки в Python являются неизменяемыми объектами
Срезы
Для извлечения подстроки из строки можно использовать срезы. Срезы позволяют выбирать из строки подстроку, начиная с определенного индекса и до определенного индекса. Синтаксис срезов в Python выглядит следующим образом:
s[start:stop:step]
где s — это строка, start — начальный индекс среза, stop — конечный индекс среза (данный элемент не будет включен в срез, только все элементы до него!), step — шаг среза.
Примеры:
Извлечение подстроки из строки:
s = "Hello, world!" substring = s[0:5] # Выбираем подстроку "Hello" print(substring) # Выводим на экран "Hello"
В данном примере, мы выбрали символы с 0 (начального) до 4 (пятый не включается!). Получилась строка из 5 символов — Hello
Извлечение каждого второго символа из строки:
s = "abcdefghijklmnopqrstuvwxyz" substring = s[::2] # Выбираем каждый второй символ из строки print(substring) # Выводим на экран "acegikmoqsuwy"
Здесь, мы с вами пропустили два первых значения среза (start и stop). Об этом говорят пустые двоеточия без цифр. Это означает, что мы будет работать со всей строкой от начала до конца. А третий параметр — step, задали равным 2. То есть, возьмем каждый второй символ, начиная с начального (нулевого).
Извлечение подстроки из строки с отрицательным индексом:
s = "Hello, world!" substring = s[-6:-1] # Выбираем подстроку "world" print(substring) # Выводим на экран "world"
Здесь, мы используем в срезе отрицательные индексы. Напомню, что отрицательные индексы позволяют делать нумерацию с конца строки. -6 в параметре start, позволяет задать начало среза с шестого с конца символа (w). -1 в stop означает, что конечный символ среза — последний элемент строки. Напомню, что срез делается ДО элемента с индексом stop и не включает его. То есть, в срезу возьмутся все символы, начиная с шестого с конца и до предпоследнего.
Извлечение подстроки с определенным шагом
s = "abcdefghijklmnopqrstuvwxyz" substring = s[2:10:2] # Выбираем каждый второй символ из подстроки "cdefghij" print(substring) # Выводим на экран "cegi"
В данном примере, мы получаем в срез все символы начиная с индекса 2 (символ c) до индекса 9 (символ j) и берем их с шагом 2, то есть каждый второй.
Отрицательные значения в срезах
Отрицательные значения в срезах используются для обращения к символам или подстрокам с конца строки. Так, например, если мы хотим получить последний символ строки, мы можем использовать индекс -1, предпоследний -2, и так далее.
При использовании отрицательных индексов в срезах, счет начинается с конца строки, то есть последний символ имеет индекс -1, предпоследний -2 и так далее. При этом левый конец среза должен быть больше правого, иначе будет возвращаться пустая строка.
Пример:
s = "Hello, World!" # Получаем последний символ last_char = s[-1] # '!' # Получаем последние 4 символа last_chars = s[-4:] # 'ld!' # Получаем все символы кроме первых 7 without_first = s[-7:] # ' World!'
Шаг в срезе
При использовании среза можно указать не только начальный и конечный индексы, но и шаг. Шаг указывает, через сколько символов следует брать элементы из строки. По умолчанию шаг равен 1.
Если значение шага отрицательное, то выбираются элементы в обратном порядке. Например, если у нас есть строка «hello world», и мы хотим выбрать каждый второй символ в обратном порядке, то можно использовать срез с отрицательным шагом:
s = "hello world" result = s[::-2] print(result) # "drlolh"
В случае использования отрицательного шага в срезе строк, начальный индекс (start) должен указывать на конечный символ среза, а конечный индекс (stop) должен указывать на первый символ среза.
Например, если у нас есть строка «hello world» и мы хотим извлечь подстроку «dlrow», используя отрицательный шаг, то мы можем использовать следующий срез:
s = "hello world" sub = s[9:3:-1] print(sub) # "dlrow"
Здесь start равен 9, так как это индекс символа «d», который является последним символом в срезе, а stop равен 3, так как это индекс символа «w», который является первым символом в срезе. Шаг равен -1, что означает, что мы переходим от конца строки к ее началу.
Важно помнить, что в случае использования отрицательного шага в срезе, индексы должны быть указаны в порядке убывания.
Пропуски значений в срезе
Пропуск компонента среза в Python обозначается двумя точками подряд :. Он используется для указания значения по умолчанию для start, stop и step в срезе.
Если при задании среза опустить start, то считается, что он равен нулю. Если опустить stop, то это означает, что срез должен браться до конца строки. Если опустить step, то считается, что он равен 1.
Рассмотрим несколько примеров:
string = "Hello, world!"
# извлечение первых 5 символов print(string[:5]) # выведет "Hello"
# извлечение последних 6 символов print(string[-6:]) # выведет "world!"
# извлечение символов с шагом 2, начиная с третьего символа print(string[2::2]) # выведет "lo ol"
В первом примере мы использовали пропуск для start, чтобы получить первые 5 символов строки. Во втором примере мы использовали пропуск для step, чтобы получить все символы строки с шагом 1, начиная с шестого символа с конца. В третьем примере мы использовали пропуск для stop, чтобы получить все символы строки с шагом 2, начиная с третьего символа.
Также можно использовать несколько пропусков для задания среза, который включает в себя всю строку:
string = "Hello, world!"
# получение всей строки print(string[:]) # выведет "Hello, world!"
Задания для закрепления работы со срезами
Задание 3. Напишите программу, которая принимает строку от пользователя и выводит на экран первые 3 символа строки. Если строка короче 3 символов, выведите всю строку.
Задание 4. Напишите программу, которая принимает строку от пользователя и выводит на экран последние 3 символа строки. Если строка короче 3 символов, выведите всю строку.
Задание 5. Напишите программу, которая принимает строку от пользователя и выводит на экран символы с 2 по 5. Если строка короче 5 символов, выведите всю строку.
Задание 6. Напишите программу, которая принимает строку от пользователя и выводит на экран каждый третий символ начиная с 2-го символа. Если строка короче 2 символов, выведите всю строку.
Задание 7. Напишите программу, которая принимает строку от пользователя и выводит на экран каждый второй символ в обратном порядке. Если строка короче 2 символов, выведите всю строку.
Задание 8. Напишите программу, которая принимает строку от пользователя и выводит на экран символы с шагом 2 начиная со второго символа и до предпоследнего символа. Если строка короче 3 символов, выведите всю строку.
Как посчитать количество символов в строке
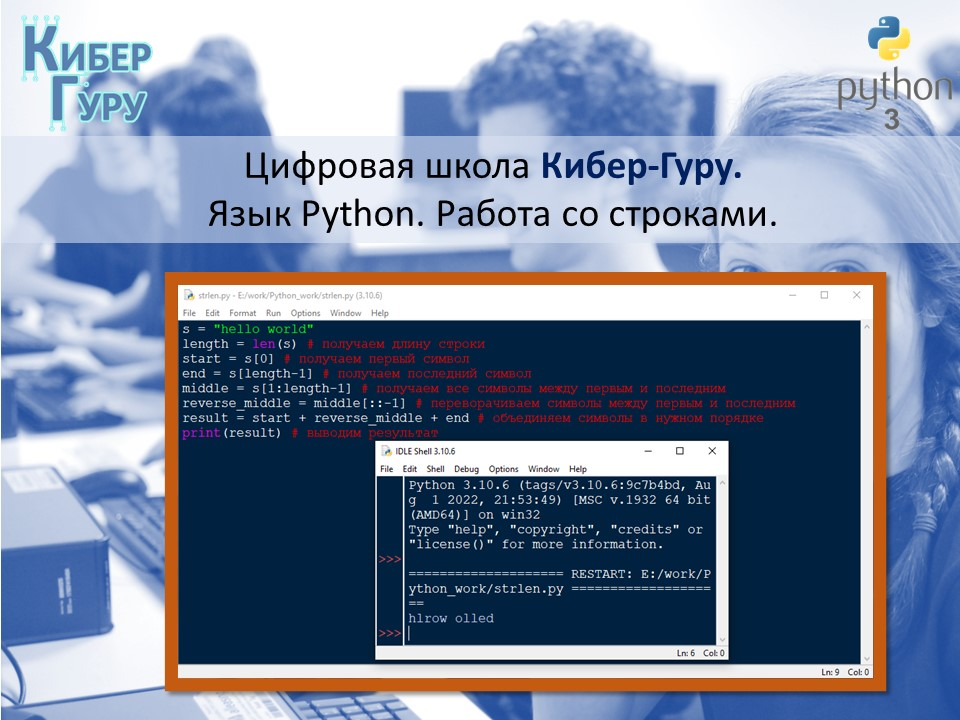
Для того чтобы узнать длину строки в Python, можно использовать встроенную функцию len(). Эта функция принимает на вход объект, длину которого нужно узнать, и возвращает целое число, равное количеству элементов в этом объекте.
Пример 1: определение длины строки
string = "Hello, world!" length = len(string) print(length) # 13
В этом примере мы создаем строку "Hello, world!" и вызываем функцию len() для определения ее длины. Результатом выполнения программы будет число 13, так как в этой строке содержится 13 символов.
Задание для закрепления работы с функцией len()
Задание 9. Написать программу, которая принимает на вход строку и выводит первую и последнюю букву строки, а также все символы между ними в обратном порядке.
Строковые методы
Методы строк — это функции, которые могут быть применены к строке в Python. Они предназначены для выполнения различных операций со строками, таких как поиск подстроки, замена символов, преобразование регистра и многое другое.
Методы строк очень полезны, потому что они позволяют легко изменять и манипулировать строками, что может быть особенно полезно при обработке данных. Вместо того, чтобы написать свой собственный код для выполнения этих операций, можно использовать готовые методы, которые уже встроены в Python.
Для вызова метода по отношению к строковой переменной нужно написать имя переменной, затем точку и имя метода, а после открывающей скобки передать аргументы метода (если они нужны). Например, если у нас есть строковая переменная my_string и мы хотим применить метод upper() для преобразования строки в верхний регистр, то мы можем вызвать его следующим образом:
my_string = "Hello, World!" my_string = my_string.upper()
Некоторые примеры методов строк:
- upper(): преобразует все символы в верхний регистр.
- lower(): преобразует все символы в нижний регистр.
- replace(): заменяет одну подстроку на другую.
- find(): ищет подстроку в строке и возвращает ее позицию.
- count(): считает количество вхождений подстроки в строку.
Например, метод upper() можно использовать для преобразования всех символов в строке в верхний регистр:
s = "hello world" s_upper = s.upper() print(s_upper) # Выведет: HELLO WORLD
Метод replace() можно использовать для замены всех вхождений одной подстроки на другую:
s = "hello world" s_replaced = s.replace("o", "0") print(s_replaced) # Выведет: hell0 w0rld
Обзор методов Python
Метод find(): возвращает индекс первого вхождения подстроки в строке (или -1, если подстрока не найдена). Метод может принимать два параметра: искомую подстроку и индекс начала поиска (опционально). Если индекс начала поиска не указан, то поиск начинается с начала строки. Метод rfind() является аналогом метода find(), но возвращает индекс последнего вхождения подстроки в строку (с конца строки), а не первого.
Пример:
s = 'Hello, world!' print(s.find('l')) # выводит 2, индекс первого вхождения буквы 'l' print(s.find('world')) # выводит 7, индекс первого вхождения подстроки 'world' print(s.find('l', 3)) # выводит 3, индекс первого вхождения буквы 'l' начиная с индекса 3 print(s.find('x')) # выводит -1, так как буква 'x' не найдена
Метод count(): возвращает количество вхождений подстроки в строку. Метод также может принимать два параметра: искомую подстроку и индекс начала поиска (опционально). Если индекс начала поиска не указан, то поиск начинается с начала строки.
Пример:
s = 'Hello, world!' print(s.count('l')) # выводит 3, так как буква 'l' встречается 3 раза в строке print(s.count('world')) # выводит 1, так как подстрока 'world' встречается 1 раз в строке print(s.count('l', 3)) # выводит 2, так как буква 'l' встречается 2 раза начиная с индекса 3 print(s.count('x')) # выводит 0, так как буква 'x' не встречается в строке
Метод replace(): заменяет все вхождения одной подстроки на другую подстроку в строке. Метод принимает два параметра: подстроку, которую нужно заменить, и подстроку, на которую нужно заменить первую подстроку.
Пример:
s = 'Hello, world!' new_s = s.replace('o', 'i') print(new_s) # выводит 'Helli, wirld!'
Метод chr(): возвращает символ по заданному коду символа.
Пример:
print(chr(65)) # выводит 'A'
Python
Copy
Метод ord(): возвращает число Unicode для заданного символа.
Пример:
print(ord('A')) # выводит 65
Метод split() используется для разделения строки на подстроки по определенному разделителю. Разделитель может быть передан как аргумент метода или, если аргумент не указан, то пробел является разделителем по умолчанию. Результатом работы метода является список подстрок. Пример использования:
# Разделение строки по пробелу text = "Hello, world!" words = text.split() print(words) # ['Hello,', 'world!']
# Разделение строки по запятой text = "apple,banana,pear" fruits = text.split(",") print(fruits) # ['apple', 'banana', 'pear']
Метод join() используется для объединения элементов последовательности в строку, используя заданный разделитель. Метод применяется к разделителю и передается последовательность в качестве аргумента. Результатом является строка, состоящая из элементов последовательности, объединенных разделителем. Пример использования:
# Объединение списка в строку с разделителем запятая fruits = ['apple', 'banana', 'pear'] text = ','.join(fruits) print(text) # 'apple,banana,pear'
# Объединение списка в строку с разделителем пробел words = ['Hello,', 'world!'] text = ' '.join(words) print(text) # 'Hello, world!'
Прочие строковые методы
Список методов строк, отвечающих за разделение и сборку строки:
- split(sep=None, maxsplit=-1): разделяет строку на подстроки, используя заданный разделитель sep. Если разделитель не указан, используется пробел. maxsplit определяет максимальное количество разбиений (по умолчанию все).
- rsplit(sep=None, maxsplit=-1): разделяет строку на подстроки, используя заданный разделитель sep, начиная справа.
- splitlines(keepends=False): разделяет строку на подстроки по символам перевода строки. Если keepends=True, символы перевода строки остаются в строке.
- join(iterable): объединяет элементы итерируемого объекта в строку, разделяя их текущей строкой.
- replace(old, new, count=-1): заменяет все вхождения подстроки old на подстроку new. count определяет максимальное количество замен (по умолчанию все).
- partition(sep): разделяет строку на три части: все, что находится до первого вхождения sep, само sep, и все, что находится после первого вхождения sep. Если sep не найден, возвращает оригинальную строку и две пустые строки.
- rpartition(sep): аналогичен partition(), но разделение производится справа.
Проверки вхождения
- str.endswith(suffix[, start[, end]]): Возвращает True, если строка заканчивается заданным суффиксом, иначе возвращает False.
- str.startswith(prefix[, start[, end]]): Возвращает True, если строка начинается заданным префиксом, иначе возвращает False.
- str.isalnum(): Возвращает True, если все символы в строке являются буквами или цифрами, иначе возвращает False.
- str.isalpha(): Возвращает True, если все символы в строке являются буквами, иначе возвращает False.
- str.isdecimal(): Возвращает True, если все символы в строке являются десятичными цифрами, иначе возвращает False.
- str.isdigit(): Возвращает True, если все символы в строке являются цифрами, иначе возвращает False.
- str.isidentifier(): Возвращает True, если строка является допустимым идентификатором Python, иначе возвращает False.
- str.islower(): Возвращает True, если все символы в строке являются строчными буквами, иначе возвращает False.
- str.isnumeric(): Возвращает True, если все символы в строке являются числами, иначе возвращает False.
- str.isprintable(): Возвращает True, если все символы в строке печатаемые, иначе возвращает False.
- str.isspace(): Возвращает True, если все символы в строке являются пробельными символами, иначе возвращает False.
- str.istitle(): Возвращает True, если строка начинается с заглавной буквы и все остальные символы в строке являются строчными, иначе возвращает False.
- str.isupper(): Возвращает True, если все символы в строке являются заглавными буквами, иначе возвращает False.
- str.count(sub[, start[, end]]): Возвращает количество вхождений подстроки в строку.
- str.find(sub[, start[, end]]): Возвращает индекс первого вхождения подстроки в строку, или -1, если подстрока не найдена.
- str.index(sub[, start[, end]]): То же, что и str.find(), но если подстрока не найдена, вызывает исключение.
- str.rfind(sub[, start[, end]]): Возвращает индекс последнего вхождения подстроки в строку, или -1, если подстрока не найдена
Преобразование строк
- upper(): переводит все символы строки в верхний регистр
- lower(): переводит все символы строки в нижний регистр
- capitalize(): переводит первый символ строки в верхний регистр, а все остальные в нижний
- title(): переводит первый символ каждого слова в верхний регистр, а все остальные в нижний
- swapcase(): переводит символы верхнего регистра в нижний и символы нижнего регистра в верхний
- strip([chars]): удаляет все вхождения указанных символов с начала и конца строки (по умолчанию пробелы)
- rstrip([chars]): удаляет все вхождения указанных символов с конца строки (по умолчанию пробелы)
- lstrip([chars]): удаляет все вхождения указанных символов с начала строки (по умолчанию пробелы)
- replace(old, new[, count]): заменяет все вхождения указанной подстроки old на подстроку new, не более count раз (по умолчанию все вхождения)
- translate(table[, deletechars]): возвращает копию строки, в которой все символы, указанные в таблице table, заменены на соответствующие символы или удаляются (если передан параметр deletechars)
- maketrans(x[, y[, z]]): создает таблицу, используемую для перевода символов с помощью метода translate(). Если указан один аргумент, он должен быть словарем, где ключи — это символы, которые нужно заменить, а значения — символы, на которые нужно их заменить. Если переданы два аргумента, они должны быть строками равной длины, где каждый символ первой строки заменяется соответствующим символом из второй строки. Если передан третий аргумент, он должен быть строкой, в которой указаны символы, которые нужно удалить из строки.
Задания на закрепление использования строковых методов
Задание 10.Найти индекс первого вхождения символа в строке и вывести его на экран.
Задание 11. Посчитать количество вхождений символа в строке и вывести результат на экран.
Задание 12. Заменить все вхождения символа в строке на другой символ и вывести результат на экран.
Задание 13. Найти индекс последнего вхождения символа в строке и вывести его на экран.
Форматирование строк
Форматирование строк — это когда мы хотим напечатать какой-то текст, но в нем надо заменить некоторые слова на другие слова или значения, например, числа.
Мы используем специальные знаки, чтобы показать, где мы хотим, чтобы произошла эта замена. Такой способ делает текст удобным для чтения.
Вместо того, чтобы создавать длинные строки с конкатенацией и разделителями, можно использовать специальные символы, которые обозначают места вставки значений.
В Python есть несколько способов форматирования строк, включая использование оператора %, метода format(), а также f-строк (начиная с Python 3.6). Они позволяют указывать значения, которые будут вставлены в строку, а также форматировать их в соответствии с определенными правилами.
Например, мы можем использовать форматирование строк, чтобы вывести значение переменной в предложении:
name = "John" age = 30 print("My name is %s and I'm %d years old." % (name, age))
Здесь символ %s обозначает место, где должно быть вставлено значение строки, а символ %d обозначает место, где должно быть вставлено целое число. Значения для вставки передаются в виде кортежа в круглых скобках после символа %.
Результат выполнения данного кода будет следующим:
My name is John and I'm 30 years old.
Таким образом, форматирование строк позволяет создавать более читабельный и понятный код, упрощая работу с динамическими значениями в строках.
Синтаксис использования форматирования
Для форматирования строк в Python можно использовать общий синтаксис, который состоит из строки-шаблона и значения, которые нужно вставить в этот шаблон. Чтобы вставить значение в строку-шаблон, нужно использовать фигурные скобки {} и перед ними указать номер позиции в списке значений, начиная с 0. Например, если нужно вставить два значения — строку «hello» и число 42, то шаблон будет выглядеть так:
template = "String: {}, Number: {}" values = ["hello", 42] result = template.format(*values) print(result)
В этом примере мы задали строку-шаблон template с двумя фигурными скобками, и список values, содержащий два значения, которые нужно вставить в шаблон. Затем мы вызвали метод format() для строки-шаблона и передали в него список значений с помощью звездочки *. Результат выполнения этого кода будет следующим:
String: hello, Number: 42
Спецификатор формата
Полный спецификатор (описание синтаксиса) форматирования в Python имеет следующий вид:
[[fill]align][sign][#][0][width][,][.precision][type]
Квадратные скобки обозначают необязательные параметры. Подробнее о спецификаторах синтаксиса можно узнать тут. Давайте разберем каждый параметр подробнее:
- fill: символ, используемый для заполнения пустого пространства между значением и шириной поля. По умолчанию используется пробел.
- align: выравнивание значения внутри ширины поля. Возможные значения:<: выравнивание по левому краю (по умолчанию)
>: выравнивание по правому краю
^: выравнивание по центру
=: выравнивание по центру и заполнение пустого пространства символом fill для числовых типов данных - sign: показывать ли знак для числовых значений. Возможные значения:+: всегда показывать знак, даже для положительных чисел
-: только для отрицательных чисел (по умолчанию)
: использовать пробел для положительных чисел, знак для отрицательных - #: добавить дополнительную информацию о формате. Возможные значения:o: добавить префикс ‘0o’ для восьмеричных чисел
x или X: добавить префикс ‘0x’ или ‘0X’ для шестнадцатеричных чисел соответственно
b: добавить префикс ‘0b’ для двоичных чисел
.: при использовании с типом f или F — всегда показывать десятичную точку - 0: заполнить пустое место нулями вместо пробелов
- width: минимальная ширина поля. Если значение меньше, чем указанная ширина, то оно заполняется символами fill. По умолчанию равно 0.
- ,: добавлять разделитель тысячных для целых чисел
- .precision: точность для числовых типов данных (количество знаков после десятичной точки). Для остальных типов игнорируется.
- type: тип форматирования. Возможные значения:d или i: десятичное число (целочисленный тип)
o: восьмеричное число
x или X: шестнадцатеричное число
b: двоичное число
e или E: число в экспоненциальной записи (например, 3.14e+00)
f или `F : число в записи десятичной дроби, например: 1.25
Звучит сложно, поэтому разберем эти параметры на примерах.
Выравнивание в форматировании
- {:<N} — выравнивание по левому краю, заполнение пробелами справа до длины N
- {:>N} — выравнивание по правому краю, заполнение пробелами слева до длины N
- {:^N} — выравнивание по центру, заполнение пробелами с обеих сторон до длины N
Пример использования выравнивания:
name = "John" age = 30 print("{:<10} {:^10} {:>10}".format(name, age, "years old"))
Вывод:
John 30 years old
Слово John было выровнено по левому краю с отступом 10, «30» — по центру с отступом 10, а «years old» по правому краю с отступом 10. Поэкспериментируйте с разными значениями отступов и сравните результат.
Заполнители
Заполнитель в форматировании строк используется для добавления символов-заполнителей между отформатированным значением и границей поля, если значение занимает меньшее количество символов, чем заданная ширина поля.
Для использования заполнителя необходимо добавить символ-заполнитель после двоеточия в спецификаторе формата, например, ‘{:05}’. В этом примере заполнитель ‘0’ будет добавлен перед значением, если значение занимает меньше пяти символов.
Примеры использования заполнителя:
# Использование заполнителя нуля num = 7 print("Number: {:03}".format(num)) # Вывод: Number: 007
# Использование заполнителя пробела text = "hello" print("Text: {:>10}".format(text)) # Вывод: Text: hello
В первом примере мы использовали заполнитель нуля, чтобы добавить два нуля перед числом 7 и выровнять его по ширине в три символа. Во втором примере мы использовали заполнитель пробела, чтобы добавить пять пробелов перед словом «hello» и выровнять его по ширине в десять символов.
Заполнитель можно использовать с различными типами данных, включая числа, строки и даты. Кроме того, можно использовать не только одиночные символы-заполнители, но и строки-заполнители.
Примеры использования заполнителя со строками, числами и датами:
# Использование заполнителя со строкой name = "Alice" print("Hello, {:*>10}!".format(name)) # Вывод: Hello, *****Alice!
# Использование заполнителя с числом num = 42 print("Number: {:,.2f}".format(num)) # Вывод: Number: 42.00
# Использование заполнителя с датой from datetime import datetime
dt = datetime(2022, 4, 1) print("Date: {:%Y-%m-%d}".format(dt)) # Вывод: Date: 2022-04-01
В первом примере мы использовали строковый заполнитель ‘*’, чтобы заполнить пустое пространство перед именем «Alice». Во втором примере мы использовали заполнитель запятой и точки, чтобы отделить тысячи и добавить два знака после запятой к числу 42. В третьем примере мы использовали заполнитель для форматирования даты в формате «ГГГГ-ММ-ДД».
Использование знаков для чисел.
Часто требуется указать знак не только для отрицательных, но и для положительных чисел. Как это сделать:
x = 10 print("{:+} {:<10}".format(x, bin(x)))
В данном случае, переменная x имеет положительное значение и была выведена со знаком +
+10 0b1010
Использование различных представлений типов данных
- d — целое число
- f — число с плавающей точкой
- s — строка
- b — двоичное число
- o — восьмеричное число
- x — шестнадцатеричное число
x = 10.5 print("{:.2f} {:d} {:o} {:x} {}".format(x, 42, 42, 42, "string"))
В данном примере мы выводим переменную x с двумя знаками после запятой, а также число 42 в десятичной, восьмеричной и шестнадцатеричной системе счисления.
10.50 42 52 2a string
Использование перевода строки и табуляции
Специальные символы:
- \n — перевод строки
- \t — символ табуляции
Пример использования специальных символов:
print("first line\nsecond line\ttabbed")
В данном примере, был использован перевод на новую строку после first line и добавлена табуляция (широкий отступ) после second line.
first line
second line tabbed
Задания на форматирование строк
Задание 14. Создайте переменную name со значением вашего имени и переменную age со значением вашего возраста. Выведите строку «Меня зовут <имя>, мне <возраст> лет.» с помощью форматирования строк.Создайте переменную balance со значением вашего баланса на счете и переменную currency со значением валюты (например, «руб.» или «$»). Выведите строку «На вашем счете <balance> <currency>.» с помощью форматирования строк.Создайте переменную temperature со значением температуры в градусах Цельсия. Выведите строку «Температура сегодня <temperature> градусов Цельсия» с помощью форматирования строк.Создайте переменную text со значением произвольного текста. Затем выведите этот текст, заменив все буквы «а» на знак «*». Используйте метод replace() и форматирование строк.
Практические задания на строки в Python
Задание 15. Составить программу, которая запрашивает название футбольной команды и повторяет его на экране со словами «— это чемпион!»
Задание 16. Составить программу, которая запрашивает название романа и фамилию его автора, а затем выводит сообщение: «Писатель … — автор романа …» (на месте многоточий должны быть выведены соответствующие значения).
Задание 17. Дано название города. Определить, четно или нет количество символов в нем.
Задание 18. Дано слово. Верно ли, что оно начинается и оканчивается на одну и ту же букву?
Задание 19. Дано слово. Получить и вывести на экран буквосочетание, состоящее из его третьего и последнего символа.
Задание 20. Из слова яблоко путем срезов получить слова блок и око.
Задание 21. Из слова курсор путем замены его букв получить слово танцор.
Задание 22. Дано слово длиной кратной трем. Поменять местами его трети следующим образом: первую треть слова разместить на месте третьей, вторую треть — на месте первой, третью треть — на месте второй.
Задание 23. Дано предложение из более чем 4 слов. Определить число слов нем. Переставить второе и четвертое слова местами.
Задание 24. Дано предложение. Определить долю (в %) букв а в нем.
Задание 25. Дано предложение. Заменить в нем все вхождения буквосочетания бит на рог.
Задание 26. Дано слово. Поменять местами его m-ю и n-ю буквы.
Задание 27. Дано предложение. Удалить из него все буквы с.
Статья сформирована по материалам на моем сайте: https://victor-komlev.ru/rabota-so-strokami-v-python/
Там же вы сможете найти решения задач, которые приведены в данном мануале.