О сложном просто!!! Предлагается немного отвлечься от темы аудио, поскольку спекуляции с ИИ повалили как из рога изобилия.
Для начала разговора по существу проверим-ка актуальность научно-популярной статьи, написанной (и опубликованной в журнале "Компьютерра") аж в 2002 году!

Начало цитирования:
На прилавках магазинов бытовой техники все чаще стали появляться любопытные экземпляры, отмеченные таинственным "AI" (Artificial Intelligence - искусственный интеллект, в разговорной речи "Эй-Ай", далее по тексту "ИИ"), вызывая бурные восторги в технических обзорах и озадаченность у большинства покупателей. Так, нейро-пылесос самостоятельно регулирует силу всасывания в зависимости от заполнения пылью мешка. Поумневший телевизор умудряется догадаться сам, где надо поднастроить контрастность без воздействия на яркость всей картинки, а так же приглушить звук, когда внезапный всплеск мощности звука следует считать аномальным. Интеллектуально-логичная стиральная машина сама оптимизирует температуру воды, продолжительность стирки и скорость отжима в соответствии с весом и типом загруженного белья, что дает ощутимую экономию по всем показателям.
Не будем гадать на кофейной гуще, как далеко зашли на поприще ИИ "товарищи ученые, доценты с кандидатами", щедро подпитываемые военными ведомствами. Нет смысла тратить время на полемику: нужен нам ИИ или не очень. Рутинного умственного труда предостаточно. Классификация, прогнозирование, распознавание и принятие решений - вот далеко не все, что ИИ взвалит на свои плечи. А творческого умственного труда с лихвой хватит на всех желающих. Бесполезно пытаться разузнать, над воплощением какого ИИ сейчас колдуют многоуважаемые AT&T, Intel, General Electric, Sharp, Hitachi, Siemens и другие. Достаточно принять во внимание мимоходом оброненную фразу: "Перспективы повышения конкурентоспособности на базе "ИИ" столь велики, что их нежелательно обсуждать публично" [1]. На данный момент передовая часть человечества пробирается к вершинам ИИ тремя путями. Это нейронные сети (neural networks, далее НС), нечеткая (fuzzy) логика и генетические алгоритмы. Поговаривают об искусственной жизни (artificial life), но в погоне за сенсацией "из мухи делают слона".
Как результат, общественность пребывает во взволнованном недоумении, того и гляди, терминаторы начнут на каждом шагу мерещиться. Ученые мужи на поприще ИИ плодятся как "грибы после дождя" (что само по себе отрадно, ведь количество имеет свойство переходить в качество), заваливая статьями многочисленные зарубежные специализированные журналы и всевозможные научно-популярные издания. Всемирно известный Спилперг вовсю трудится над очередным кино шедевром, посвященным ИИ. Бизнес ловкачи спешно подготавливают сознание масс с помощью интеллектуальных игрушек типа собачек-роботов. Не заставила себя ждать пульсирующая активность аферистов всех мастей, навязчиво предлагающих нечто с ярлычком ИИ, но совсем не обремененное интеллектом. Судя по всему, ИИ вошел в новый виток мировой моды, что неизбежно даст скачок численности его почитателей, ну и яростных противников, естественно. Стало быть, пора предостеречь новое поколение, обратившее свой взор на ИИ, от распространенных заблуждений и обидных ошибок типа "граблей", открыто рассказав об узких местах наиболее продвинутого направления - нейросетей.
Если просмотреть кадры старых кино-фото материалов, то неизбежно острые ощущения вызовут первые летательные аппараты. Подниматься в воздух на хлипких неуклюжих "этажерках" решались воистину незаурядные люди. Почти за 100 лет человечество не смогло создать близкий аналог птицы, но научилось летать почти в 100 раз быстрее. Люди позаимствовали у природы секрет подъемной силы крыла, и это послужило трамплином, чтобы превзойти природу по нужным для человека свойствам в покорении воздушного океана. Сегодняшние НС по сути такие же убогие "этажерки". Медленно и неустойчиво "взлетают", капризны при управлении в "полете", а "фигуры высшего пилотажа" выполняются без хорошего знания законов "аэродинамики". Но нейросети уже "летают" на новых и новых высотах!!! Предметом заимствования у природы стала совместная активность нелинейных элементов. Ясно, что полный аналог разума, как в истории с искусственной птицей, не достижим. Более того, идеальная в смысле практической выгоды приближенность к разуму и не нужна. НС будут быстрее решать (если хотите не будут уставать) многие головоломки, а отдельно поставленные задачи - даже намного лучше человека, но по гибкости, универсальности и изобретательности никогда не достигнут разума их создателя - человека.
Как много нам открытий чудных готовит просветленья путь
НС является прообразом "кусочка" мозга и представляет собой совокупность нелинейных пороговых элементов (нейронов), связанных между собой в определенном порядке, а сила связи выражается в величине весового коэффициента. Функция активации нейрона чаще всего представляет собой нелинейную ограниченно возрастающую кривую без изломов (монотонно). Так, гиперболический тангенс или так называемая сигмоидальная являются весьма подходящими функциями активации, благо производная от этих функций выражается через саму функцию. Реже применяется функция активации, которая изменяется скачкообразно после превышения некоторого порогового значения аргумента. Биологические нейроны отличаются от искусственных, как горный орел от планера "досааф", но имеется далеко идущее сходство. Это наличие одного выхода (аксона) и множества входов - дендритов, переходящих в синапсы. А уж синапсы связаны с аксонами других нейронов, благодаря чему каждый нейрон оказывается звеном той или иной "живой" нейронной сети [2]. Нейроны мозга существенно различаются между собой по форме, связям и способам функционирования, но для каждого типа нейронов характерно образование цепочек. Их можно разделить на сенсорные, моторные и т.д. Каждая уникальная структурная особенность того или иного нейрона отражает степень его специализации для выполнения определенных задач.
Порядок связей между искусственными нейронами называют архитектурой или топологией НС, которая может быть самой разнообразной. Каждая НС имеет вход и выход фиксированной размерности. При изменении числа выходов свойства НС могут кардинально измениться, поэтому приходится констатировать "перерождение" НС в новую. В большинстве НС нейроны разделены на группы, и можно четко выделить входные и выходные нейроны. Например, НС типа многослойного персептрона (Multi Layer Perceptron, далее MLP) имеет между входом и выходом слой или несколько слоев нейронов, называемых спрятанными (hidden). Рисуночки архитектуры обычного MLP можно лицезреть почти в каждой статье, посвященной нейросетям. Изображение архитектуры нейросети с обратными связями не успело набить оскомину, поэтому один из вариантов (простейших) представлен на Рис.1.
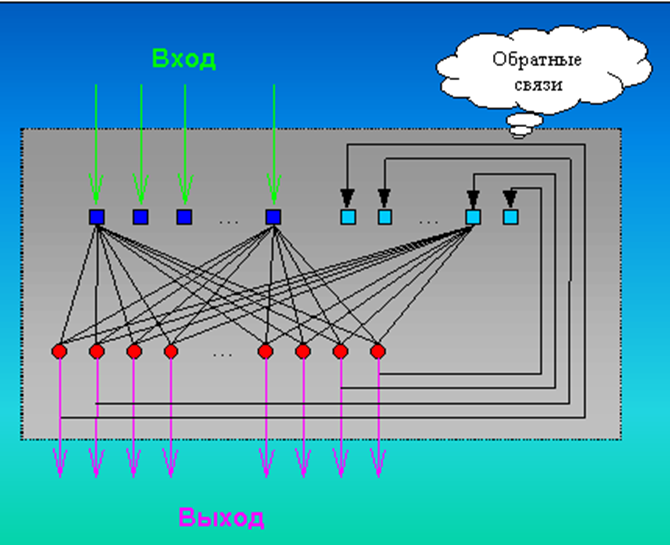
НС - в принципе высоко параллельное устройство, что позволяет революционно ускорить обработку информации. НС можно реализовать в качестве программного обеспечения для обыкновенного компьютера (тогда прощай скоростные преимущества параллельности), или как аппаратное обеспечение: аналоговое, цифровое или смешанное. Наивысшая скорость и гибкость достигается на специальных компьютерах - нейрокомпьютерах с использованием соответствующего программного обеспечения. Кстати, ещё в 1986 году нейрокомпьютер MARK-IV (детище TRW, США), применялся для распознавания типа самолетов с 95%-й точностью [3]. В целях повышения скорости обработки информации в компактных устройствах растет производство специализированных процессоров, окрещенных в обычном обиходе нейрочипами, которые оптимизированы под нейросетевые вычисления.
"Ученье - свет, а … - тьма"
Прежде чем НС станет способна что либо обрабатывать, её следует обучить. По сути понятие "тренинг" ближе к истине ("настройка" это из другой оперы, будьте внимательны, у некоторых авторов-переводичков каша в голове), но исторически сложилось употреблять термин "обучение" (learning). Необученная НС не имеет даже рефлексов, т.е. на любые внешние воздействия ее реакция будет хаотичной. Обучение состоит в многократном предъявлении характерных примеров (patterns, т.е. в частности образов) до тех пор, пока НС на своем выходе не станет выдавать желаемый (desired) отклик. В зависимости от назначения НС задается определенный желаемый отклик, например, для предсказания это значение предсказываемой величины. Внимание! Ключевой момент!!! В общем случае желаемый отклик задается УЧИТЕЛЕМ (superviser). В случае предсказания учитель формирует входные данные, выбирает число шагов предсказания на выходе и отфильтровывает ненужные компоненты в исходной временной последовательности, чтобы задать более подходящий желаемый отклик. Например, иногда заранее известно, что высокочастотные флуктуации предсказывать нет необходимости, поэтому их отфильтровывают и получают желаемый отклик в виде сглаженной исходной последовательности.
Разница между реальным выходом НС и предъявляемым желаемым откликом называется ошибкой. Величина и знак этой ошибки служат для самоадаптации весовых коэффициентов, которые на старте обучения задаются случайными числами. Механизм процесса обучения состоит в целенаправленном изменении (самоадаптации) весовых коэффициентов (иногда и некоторых дополнительных параметров) и называется правилом или алгоритмом обучения. Критерием обучаемости является планомерное, асимптотическое уменьшение среднеквадратичной ошибки (см. рис.2), т.е. главное, чтобы она уменьшалась с каждым новым повтором некого примера. Ближайшее сходство: учитель иностранного языка повторяет в среднем 7 раз, прежде чем хороший и выспавшийся ученик запомнит значение одного слова. "Повторение - мать учения"! Данное золотое правило справедливо не только по отношению к человеку, но и к нейросетям, хотя физическая основа обучаемости "гомо сапиенс" более сложна, поскольку огромную роль играют понимание и мышление. Обучение НС завершается, когда среднеквадратичная ошибка достигнет некоторой наперед заданной величины, или когда НС начнет правильно (с требуемой точностью) обрабатывать данные из отдельного тестового набора характерных примеров.
Следует подчеркнуть важность использования при обучении стандартных НС не первых попавшихся под руку примеров (образов), а именно характерных. Иногда удается хорошо обучить нейросеть для распознавания образов, ограничившись только корректной разбивкой всех имеющихся образов на отдельные классы, не отсортировывая неудачные ("ни рыба, ни мясо") образы в пределах одного класса. Не факт, что такой подход даст наилучшие результаты при распознавании, но то, что при обучении потребуется большее количество повторов - не приходится сомневаться. Для нейросети-предсказателя своя специфика. Прежде всего отмечу, что для русского уха предсказание (prediction) звучит с долей мистики, другое дело - прогноз, но давайте придерживаться международной научной терминологии. Так вот, если предсказывать временную последовательность типа (!) курса доллара по её предыстории, то не мешало бы уточнить, какой прогноз требуется, краткосрочный или долгосрочный. Это разные составляющие и производить обучение следовало бы по-разному. Безусловно, курс доллара по одной предыстории самого курса не предскажешь, особенно в странах дикого капитализма. Если такой фактор, как сколько раз главный банкир чихнул вчера и сколько чихнет сегодня, влияет на завтрашний курс, то этот фактор вместе со своей предысторией очень даже пригодится для предсказания.
Существуют и другой принцип самоадаптации весовых коэффициентов. Он используется в самообучающихся (unsupervised, или, говоря по простому, БЕЗ УЧИТЕЛЯ) нейросетях, яркий представитель которых самоорганизующиеся карты Кохонена (Kohonen Self-organizing Feature Maps, см. Рис.3). Суть в том, что модификации подвергаются весовые коэффициенты, соответствующие определенным, получившим приоритет нейронам. Сначала определяется согласно выбранному критерию выигравший нейрон и нейроны из его окружения. На следующем этапе обучения область вокруг выигравшего нейрона сжимается, а степень (шаг) адаптации уменьшается. Обучение прекращается опять таки после многократных повторов, когда выигрывать начнет один и тот же нейрон. Чтобы получить наилучшие результаты от применения такой НС для предварительной классификации, например амплитудно-частотных спектров вибро сигналов, необходимо изначально знать, сколько классов присутствует в обрабатываемых данных. Если количество нейронов окажется недостаточным, то самообучающаяся НС отнесет спектры "смежных" классов к более представительным классам. Если перезадаться числом нейронов, то "смежные" спектры НС отнесет к несуществующим на самом деле классам. На практике количество классов становится известным после выявления особенностей каждого класса в отдельности. Тогда как автоматически выявить эти особенности, по идее, и должна была самообучающаяся НС, причем в скрытом виде, т.е. внутри самой себя. Получается, круг замкнулся. Для нейросети без учителя некий супер учитель должен указать оптимальное число классов (выходных нейронов). Чтобы совсем обходиться без учителя тривиальной нейросети маловато будет, тут неким симбиозом попахивает, если в итоге не упереться в очередную "философскую" неопределенность типа "что было сначала, курица или яйцо". Но вернемся к нашей нейросети. Любая палка - о двух концах. С одной стороны, получаем выигрыш в автоматизации, с другой стороны, проигрыш из-за целого ряда ограничений. Сжимать область вокруг выигравшего нейрона и уменьшать шаг адаптации приходится на основе личного опыта в зависимости от специфики конкретной задачи или входных данных. Итак, самообучающиеся НС применимы для узкого круга задач, например, для предварительной классификации (кластеризации). Мелькала информация об успешном моделировании аэродинамических потоков [3, 4], однако, думаю, без ухищрений здесь не обошлось.
Кстати, по неофициальным данным нейросетевым распознаванием вибро-акустических сигналов очень интересуются гиганты автомобильной индустрии. Диагностика двигателя и трансмиссии на выходе с конвейера или на станции техобслуживания без участия "слухача-эксперта" - день сегодняшний. Прицел устремлен в будущее: оперативная диагностика любого автомобиля, находящегося в повседневной эксплуатации.
Обучение нейросетей является фундаментальным теоретическим аспектом. Если не пересматривать существующие теории, то приходишь к выводу, что задача обучения на примерах не корректна в принципе (в рамках определения корректно поставленной задачи, сформулированного Адамаром). При обучении НС на одних и тех же примерах существует несколько верных решений, а согласно Адамару решение должно быть одно. В идеале надо выбрать самое верное (единственное) решение. В жизни каждый из нас выбирает решение, не шибко "заглядывая вдаль", поскольку учесть всевозможные комбинации вкупе с накапливающимися случайными факторами невозможно. Для НС лучший критерий выбора это успешная работа (обобщение) на новых примерах, не использованных при обучении. Но где (как) взять примеры из будущего, хотя бы ближайшего? Всегда в будущем может произойти событие, которое существенно отличается от примеров, использованных при обучении, и где гарантии, что нейросеть рано или поздно не начнет делать грубые ошибки? Однако, в реальном мире "не ошибается тот, кто ничего не делает", и все наше с вами обучение "с нуля" зиждется на собственных ошибках, т.е. ни разу не ошибившись, ничему НОВОМУ не научишься. Это при обучении без учителя. А что если перестать учиться на собственных ошибках, целиком поручив прокладывать дорогу искусственному учителю и скурпулезно следовать его рекомендациям? Пусть этот учитель "набивает шишки" на смоделированных данных и спрогнозированных ситуациях, полученных им же на основе самых свежих реальных данных. Далее следует акцентировать, что одно дело обучение с ошибками, а совсем другое - работа без ошибок. Так вот, нейросеть-распознаватель будет работать корректно, если каждое новое событие, существенно отличающееся от примеров в обучающем наборе и не похожее не на одно из известных событий, классифицировать как "НЕИЗВЕСТНОЕ" и пытаться его сопоставить с известными примерами. Например, робот, обученный только распознавать по внешним признакам сливы от абрикосов, наткнувшись на персик и любые прочие объекты, должен честно признаться "не знаю". Удовлетворить на практике этому незамысловатому требованию оказывается совсем непросто: внешне персик порой бывает очень похож на абрикос, а ведь существует еще и гибрид сливы с абрикосом. На секунду отвлекусь и замечу, что приведенный "фруктовый" пример не столь условен: нейросети используются для проверки качества яблок! Чтобы улучшить распознавательную способность, надо, образно говоря, новый фрукт попробывать на вкус, т.е. провести анализ по отличительным признакам, и если этот фрукт будет отличаться от известных по всем признакам, то запомнить его как новый класс, например, гибрид сливы с абрикосом. Чтобы распознавать новый класс, НС нужно обучить, используя примеры из этого класса. Хорошо бы дообучать НС по мере необходимости, однако тот же многослойный персептрон с введением нового класса приходится учить заново. Так или иначе, приходим к понятию дообучения.
Любую НС можно дообучить, продолжая обучение с полученных ранее весовых коэффициентов, если выяснилось, что точности (другими словами, работоспособности), достигнутой при обучении, недостаточно. Причем, дообучение происходит очень легко, когда новые примеры не сильно отличаются от старых. А вот переобучить типичную НС на принципиально иных примерах (с добавлением новых классов) гораздо сложнее.
В случае перманентного дообучения на постоянно поступающую и обновляющуюся информацию НС потихоньку "забывает" старые знания. И это не мудрено: "память" сохраняется в значениях весовых коэффициентов и порогов, а когда они начинают глобально отличаться от старых значений, тогда "память" резко ухудшается. Разумеется, это очень упрощенное представление, и "белых пятен" здесь немало. С забывчатостью НС можно бороться разными способами, но иногда она является требуемым свойством.
О приобретенных навыках
Будучи обученной, НС готова обрабатывать новую информацию, которая не предъявлялась в процессе обучения, при этом НС способна ОБОБЩАТЬ (другими словами, интерпретировать) эту информацию. Способность к обобщению - ключевое преимущество НС. Конечно, если НС обучена, образно говоря, только распознавать некий сказанный пароль, то до смысла этого пароля она сама никогда не додумается. Чему НС обучили, то она и будет стремиться делать. Подчеркну, именно стремиться, поскольку может и чудить (причем не созидательно), обладая плохим "характером" как некоторые из нас смертных, но об этом чуть позже.
НС обладают замечательным (к сожалению, не врожденным) свойством: успешно обрабатывать зашумленную, искаженную или частично испорченную информацию. Однако данное потенциальное преимущество можно незаметно растерять из-за некорректного обучения и выбора архитектуры, далекой от оптимальной.
НС живет своей маленькой жизнью. Так, одна и та же НС, дважды обученная "с нуля" (со случайных весовых коэффициентов) на идентичных примерах, никогда не выдаст на выходе абсолютно одинаковых численных значений! Речь идет не о погрешности вычислений в последнем знаке. Стартуя с разных весовых коэффициентов, НС идет к цели не по одной проторенной дорожке: траектории в многомерном пространстве функции ошибки от весовых коэффициентов не будут одинаковыми, и как только ошибка на выходе станет меньше заданной, обучение завершится, а значения весовых коэффициентов уже будут иные. Как неизбежное следствие, НС будет обладать несколько разной обобщательной способностью, как правило в пределах ошибки, достигнутой при корректном обучении. Это свойство (нейросеть как бы слегка "дрожит") помогает отличить "мультяшку" от работоспособной НС, когда приобретаешь нейросетевое программное обеспечение, тестируя его при обучении на прилагаемых демонстрационных данных.
Свобода интеллектуальной личной жизни НС в большинстве практических случаев должна быть ограничена, т.е., образно говоря, приобретенных навыков вполне достаточно. Хорошая НС, как идеальный солдат, не имеет права на "мудрые" раздумья-сомнения и "глупые" самовольные решения. Негативная сторона излишней самостоятельности НС может дорого обойтись при функционировании в реальном времени, когда любое промедление смерти подобно. А что если НС начнет упорно твердить "не знаю", или, еще хуже, хулиганить, раз за разом выдавая белое за черное и наоборот? Где гарантии, что лимит времени, отведенный на дообучение в соответствии со строго регламентированными вычислительными ресурсами, не будет исчерпан до завершения дообучения? Ведь исследовать аналитически поведение НС (т.е. заранее однозначно "просчитать" результат работы НС, не запустив на выполнение саму НС) невозможно в силу нелинейности самой НС. А для ответственных приложений необходимо разработать НС с хорошо прогнозируемым поведением, что является непростой задачей. Представьте, если при "управлении" ядерным реактором (имеется в виду поддержка оператора) НС начнет своевольничать и шалить именно в аномальных, нестандартных ситуациях, сбивая с толку оператора. Недаром лучший оператор АЭС это тот, кто помимо теоретических знаний всего технологического процесса, опыта работы и быстрой реакции, имеет здравое, адекватное поведение в экстремальных ситуациях. При этом оператор должен действовать строго по инструкции, не полагаясь на интуицию.
Как из хорошиста сделать отличника
НС - не готовое на все случаи жизни устройство вроде волшебной палочки, а скорее универсальный способ, требующий грамотного воплощения. Поэтому НС стандартной архитектуры далеко не всегда наилучшим образом решает конкретную задачу. Тем не менее, можно сконструировать НС максимальной эффективности, выбрав-придував соответствующую архитектуру. Какую именно? Вопросик то сродни удару ниже пояса. Если бы был готовый ответ на все случаи жизни, то сплошь и рядом нейросети уже трудились бы на всеобщее благо. Но работа в этом направлении ведется, значит, ждите свершений.
В рамках выбранной архитектуры НС сталкиваешься с проблемой оптимизации параметров. Например, сколько надо задать нейронов в спрятанном слое для 3-х слойного персептрона?. В 50-х годах гениальный А.Н.Колмогоров доказал теорему, которая была развита последователями и в упрощенной интерпретации звучит так: трехслойный персептрон вычислит любую непрерывную функцию N переменных с любой точностью, если количество нейронов в спрятанном слое ДОСТАТОЧНО (равно 2N+1). Современная теория увлеклась другими делами, подзабыв про основной вопрос. Понятно стремление сделать НС как можно более компактной, чтобы обойтись дешевыми вычислительными ресурсами (и еще по ряду причин), посему следующий вопрос непраздный. Сколько нейронов и спрятанных слоев НЕОБХОДИМО для решения конкретной задачи? Теоретические подсказки фактически отсутствуют до сих пор.
Широко применяют некое соотношение, в частности приведенное в [5], с помощью которого определяются границы выбора общего числа нейронов, откуда легко оценить число спрятанных для 2-х слойной НС. Однако, это соотношение было получено для многослойного персептрона со ступенчатой (signum) функцией активации, а применимость данного соотношения для НС с нейронами, имеющими сигмоидальную (sigmoid) функцию активации, следует из предположения, что распознавательная способность последней из перечисленных НС не может быть хуже. А если НС состоит из нейронов с разными функциями активации, включая простую линейную, то подобное, далекое от уточняющего, предположение делать вообще нельзя. Тем не менее, соотношение позволяет прийти к 2-м любопытным выводам: во-первых, чем больше образов в обучающей выборке, тем больше нейронов должна содержать НС, и во-вторых, чем больше классов образов обрабатывает НС, тем опять таки больше у нее должно быть нейронов. Получается, что "мудрая" НС, "помнящая" все тонкости без периодического "освежения" памяти (или дообучения), должна быть очень большой! А большая НС обучается совсем иначе (в том числе и гораздо медленнее) чем малая!!! Диапазон, определяемый соотношением, может достигать нескольких порядков, причем с неоднозначной зависимостью от общего числа нейронов.
Дальше, какое количество примеров в обучающей выборке будет достаточным? Очень грубо говоря, число примеров пропорционально так называемому VC (Вапник-Червоненко)-dimension. Для нейросети с пороговой функцией активации VC оценивается как O(w log w), а для НС с линейными функциями активации пропорционально w, где w общее число весовых коэффициентов. Для НС с сигмоидальными функциями активации VC находится между O(w2) и O(w4). Строгой аналитической формулы теория не дает. Из общих соображений число примеров должно зависеть от статистического разброса между примерами, т.е. если все примеры одинаковы, то одного будет достаточно, а если все примеры сильно различаются между собой, то остается ориентироваться на их распределение.
Наконец, до какой величины ошибки учить НС? Опять таки все зависит от конкретных данных, и чтобы ответить на этот вопрос идут эмпирическим а не аналитическим путем. Обычно разбивают имеющиеся примеры на 2 группы. На первой производят обучение, тогда как вторая служит "индикатором" обученности НС (обучение прекращается, как только все примеры из 2-й группы будут обрабатываться правильно). Обобщательная способность НС находится в прямой зависимости от VC, при оптимальном значении которого НС теоретически даст минимальную ошибку на будущих данных. Для набора конкретных данных нужно выбрать НС с верным VC, что связано с выбором из нескольких архитектур. Пытаться оптимизировать структуру НС тупым перебором вариантов - почти что выиграть приз в лотерею, поскольку есть еще одна закавыка: параметры алгоритма обучения.
Несмотря на обилие появившихся алгоритмов обучения, точнее, самоадаптации весовых коэффициентов, в каждом алгоритме присутствуют уникальные параметры. Например, величина шага адаптации в ставшем уже классическим "обратном распространении ошибок" (back propagation of errors) для MLP. Замечу, в идеале величина шага должна быть разной для весовых коэффициентов и порогов, соответствующих разным нейронам. Если задать маленький шаг, то НС будет обучаться неприемлемо долго, до седьмого пришествия, а если задать очень большой шаг, то весовые коэффициенты моментально пойдут в "разнос", достигнув диких величин и подвесив программу, не имеющую проверочек на этот счет. Чтобы вывести НС из данного коматозного состояния, необходимо выполнить обучение заново. Причем, за редчайшим исключением, чем за меньшее количество итераций алгоритм минимизирует ошибку, тем больше параметров приходится оптимизировать. Справедливости ради надо признать, достигнутые успехи в автоматической настройке параметров алгоритмов дают основания для разумного оптимизма.
Школьный курс за 2 года? Но это же робот!
Несколько слов об алгоритмах ускорения обучения. Наиболее простой и древний получил название "momentum". Суть его заключается в использовании разницы между значениями весовых коэффициентов, полученных на предыдущей и текущей итерациях. Эта разница умножается на некий дополнительный параметр, меньший единицы, называемый шагом ускорения, который необходимо настраивать под конкретные входные данные. Грубо говоря, таким путем задействуется микро предыстория изменения весовых коэффициентов при очередной самоадаптации. В некоторых случаях "momentum" дает ускорение обучения в 10 раз, т.е. требуемая ошибка достигается за меньшее число повторов. Однако бездумное применение "momentum" может стать причиной стагнации ошибки при обучении и ухудшения обобщательной способности при распознавании. Другие алгоритмы, в частности Rprop, QuickProp, Conjugate Gradient, Levenberg-Marquardt (далее LM), демонстрируют разное ускорение обучения на разных данных. Каждый из алгоритмов имеет свои преимущества и недостатки. Так, в LM алгоритме используются вторые производные от функции ошибки по весовым коэффициентам, что приводит не только к росту объема вычислений, но и увеличению задействуемой памяти. LM позволяет сократить количество итераций в 10..100 раз (на рис.4 можно видеть "медленный" и "быстрый" путь), но цена этого ускорения - непомерный аппетит алгоритма к вычислительным ресурсам. В итоге получаем "баш на баш" и реальное ускорение, достигаемое на обычной персоналке, не впечатляет. Так что надо быть предельно осторожным при выборе и применении разрекламированных "ускоряющих" алгоритмов. Мораль: за все в этом мире приходится платить, а за подобное ускорение - тем более.
О связи искусственных НС с реальным миром
В биологических нейронных сетях информация поступает от внешних рецепторов через дендриты группы входных нейронов. Так в системе слуха преобразование механических колебаний (вызывающих волнообразную рябь на мембране улитки) в закодированные электрические сигналы происходит в органе Корти. Кто разгадает код, наверняка получит Нобелевскую премию. А пока разработчики систем распознавания речи довольствуются упрощенными представлениями. Тем не менее, если поставлена задача применить искусственную НС для идентификации личности по голосу (например, для авторизации доступа), то было бы большой оплошностью подавать сигналы прямо с микрофона. Ведь наши уши не только регистрируют акустические сигналы, но и выполняют предварительную обработку сигналов и формируют входные ОБРАЗЫ. Нетрудно догадаться, что эти образы несут информацию по изменению сигналов как в частотной, так и во временной области. Вероятно, информация во времени поступает параллельно, как бы отфильтрованная в нескольких частотных полосах. На этом формирование образов не заканчивается, поскольку информацию надо последовательно накапливать во времени, как бы "отматывать записанную пленку назад" в моменты фиксирования произнесенной фразы. Этот этап формирования образов уже происходит не во внутреннем ухе, а в нейронных сетях мозга, отвечающих за работу слуховой системы.
Здесь пора отвлечься и упомянуть важный практический аспект применения НС типа многослойного персептрона. Очень часто можно слышать категоричное заявление о необходимости нормировки входного массива в диапазоне {-1.0, 1.0}. На самом деле данная НС способна работать с ненормированными массивами, поскольку применяемые функции активации не имеют ограничений по входу, а чтобы избежать очень медленного обучения из-за неоптимальных стартовых значений порогов и "затыка" с малым изменением производной существуют разные методы. Конечно, выполнить нормировку проще всего, но делать это можно только тогда, когда заведомо известно, что нормировка не "убьет" отличительные признаки.
Вернемся к формированию образов. Размерность образа сделаем неизменной во времени, иначе попросту ум за разум зайдет. С другой стороны, образы могут быть 2х мерными, 3х мерными и т.д. Предположим, WaveLet преобразование вполне нас устроило, тогда каждый образ будет представлять собой матрицу коэффициентов как в частотной, так и во временной областях. Присутствие в образах компоненты времени порой приводит к значительным усложнениям, в частности, к большому разбросу образов в пределах одного класса. Например, контрольную фразу можно произнести с разным темпом, или растянуть отдельные слова или паузы между словами. В этом случае идентифицируемому по голосу скорее всего придется повторить контрольную фразу как можно ближе к фразам из обучающего набора. Иногда целесообразно учесть временной фактор, создав специальную НС с выходом, зависящим от времени.
На выходе НС будет выдавать некие числа в диапазоне, определяемом типом функции активации нейронов выходного слоя. Так для сигмоидальной функции диапазон составит в пределах от 0 до 1.0. Чтобы создать желаемый отклик, проще всего идентифицируемые события закодировать в виде последовательности нулей и единиц. Для простоты примера ограничимся идентификацией одного субъекта, которого условно будем называть "свой". Чтобы отличить своего от чужого, НС должна "знать" чужих. В итоге имеем 2 класса, и все образы, не характерные для класса "свой" относим в класс "чужой". Для 2х классов можно ограничится одним нейроном на выходе, т.е. если при идентификации на выходе НС получим значение, близкое к 0, то это будет означать принадлежность к первому классу, а если близкое к 1, то ко второму классу. Тем не менее, целесообразно перезадаться числом нейронов на выходе, скажем до 2-х. Преимущества такого подхода прояснятся позднее. Тогда пусть [0, 1] будет кодом класса "свой", а [1, 0] - кодом класса "чужой".
Стоп, - скажете вы, - чужих много, о свой один. Что теперь на всех чужих обучаться? Ответ: нет, не всех, а только на тех, кто наиболее похож на "своего". Именно такие образы следует считать характерными для класса "чужой". Выбор характерных образов для класса "свой" происходит из других соображений, учитывая специфику конкретной задачи: идентификации личности (одной или нескольких) по голосу.
После завершения обучения на характерных образах каждого класса с требуемой точностью, данная НС начнет выдавать значения, различающиеся для каждого образа в пределах одного класса, но находящиеся в неком фиксированном поле допуска. Величина поля допуска пропорциональна усредненной ошибке, достигнутой при обучении. Предположим, что 0.1 оказалось достаточно, тогда от 0 до 0.1 будет одним диапазоном контроля, а от 0.9 до 1 - другим. Из рис.5 видно, что возможно несколько случаев попадания выходных значений в вышеупомянутые диапазоны контроля. В первых двух случаях выходы НС попали четко в диапазоны контроля, на основе чего идентификация "свой" или "чужой" осуществляется автоматически (по совокупности выходных значений обеих нейронов).
Талантливый тренер - выдающийся результат
Ох и тонкое это дело, хорошо учить кого то, а уж НС тем более. С попаданием в так называемые локальные минимумы (метод градиентного спуска из мат.анализа еще не забылся?) при обучении все уши прожужжали. Первопричину болячки надо искать, пер-во-при-чи-ну. Недаром сравнительно недавно появились такие методы, как генерализация (generalization), прунинг (pruning), регуляризация (regularization). Последняя заслуживает отдельного большого разговора, в 2-х словах не растолкуешь, а данная статья итак получается тяжеловатой для восприятия. Если ваша нейросеть упорно хандрит в работе, а доброжелатели-консультанты безапелляцинно заявляют "да она у вас переобучена" (что тоже бывает!), то это как раз тот момент, чтобы окончательно избавится от иллюзий. Прежде чем браться за внедрение, нелишне четко представлять, что и как лучше всего подавать на вход НС, и что предъявлять на выходе при обучении для конкретной задачи, а так же как связать выход НС с реальным физическим "миром". В противном случае возможны два варианта. Если ваши стремления - защитить диплом или диссертацию, то за еще одно "использование" нейросети "титул" вы всяко получите, ну а применение на практике это уже другой вопрос. Если ваша цель - реальная разработка, промышленное применение и прибыль с минимальными затратами времени и средств, то лучше прибегнуть к помощи тех, кто "собаку съел" на нейросетях. Нынешние НС без талантливого тренера имеют немного шансов победить с отрывом "классических" соперников.
Математический аппарат нейросетей, ставших традиционными (MLP, Kohonen, LVQ, RBF и др.) не так сложен [6-8]. Программирование не требует особо профессиональных изощрений: на каждом шагу умножение вектора на матрицу с накоплением суммы. Сложность представляет не программирование самой НС, а алгоритм обучения в комплексе, включая подготовку обучающего набора, предварительную обработку информации и, при необходимости, ее сжатие через выделение характерных черт. Кстати, RBF (radial basis function) нейросети особенно хороши для аппроксимации, но более капризны при обучении по сравнению с MLP. LVQ (Learning vector Quantization) это развитие сетей Кохонена в направлении обучения "с учителем", не завоевавшее народной любви. Многослойные НС с обратными связями (recurrent) с точки зрения математики - птицы другого полета, похитрее будут. Они хороши для предсказания, но мороки с корректным обучением не оберешься. Модульные (кластерные, с разделенными рецептивными полями и т.д.) многослойные НС это необъятное поле для деятельности и фантазии. Есть еще стоящие особняком так называемые осцилляторные нейросети, возможно имеющие большое будущее, но их обучение пока остается камнем преткновения. Так вот, запрограммировать любую НС - это только видимая верхушка айсберга, главное - как нейросеть применить, полностью раскрыв её потенциал.
Перспектива
Многие оппоненты считают этап исследований в области нейросетей слишком затянувшимся и пророчат его бесславное, не оправдавшее надежд, завершение. Козырной картой в их раскладах служит необходимость привлечения опытного "тренера" для успешного завершения любого серьезного проекта на основе нейрости. Что касается длительности исследований в области нейрокомпьютинга в целом, то вряд ли спешка здесь была бы уместна.: слишком много тайн хранит биологический мозг даже простейших организмов. Пробелы в теории вынуждают идти путем многочисленных экспериментов в совокупности с математическим моделированием, построенным на интуитивных догадках. По мере исследований поведения НС пришлось столкнуться с огромным количеством нюансов, не предвиденных ранее. Самое главное, за прошедшие годы были вскрыты аспекты улучшения обучения как такового, начата разработка многообещающих нейросетевых архитектур и осуществлены внедрения хорошо изученных НС. Да, следует признать, что самонастройка НС еще далека от совершенства, а в лучшая из разработанных непозволительно дорога. Например, использование нечеткой логики для оптимизации параметров НС требует оптимизации параметров самой нечеткой логики. Аналогичная по сути но более оптимистичная по первым результатам ситуация и с генетическими алгоритмами. Вместе с тем, если следовать по пути аналогий с биологическими нейронными сетями, то было бы опрометчивым упустить из виду тот факт, что индивидуальный опыт (обучение) вносит серьезные уточнения в развитие нервной системы, запланированное генетически. Например, в течение первых двух лет нормальной жизни человека происходит рост нейронов, увеличение синаптических связей между нейронами и специализация групп нейронов, причем без заметного увеличения общего числа нейронов. Таким образом, есть все основания полагать, что НС нового поколения будут иметь топологию, самоорганизующуюся в процессе обучения, при этом для конкретного класса задач изначальная архитектура НС будет специализирована. Сама по себе идея самоорганизации архитектуры НС не нова: попытки заставить MLP "самоподнастраиваться" через изменение числа нейронов в спрятанном слое предпринимались давно. Однако, всему свое время. Именно сейчас количество исследований переходит в качество результатов, и именно сейчас внедрение НС разворачивается широким фронтом.
Acknowledgment
Автор глубоко признателен всем коллегам, чьё мнение прямо или косвенно повлияло на изложение материала в рамках данной статьи. Дружеское спасибо Andrew Gribok (США), длительные дискуссии с которым позволили избежать излишней доли субъективности.
Ссылки:
1. Дж.Шэндл «Нейронный сети - на пути к широкому внедрению» Зарубежная радиоэлектроника, №15, стр.23-30, 1993.
2. Ф.Блум, А.Лейзерсон, Л.Хофстедтер «Мозг, разум и поведение» Москва, "Мир" 1988
3. R.Hecht-Nielsen «Neurocomputing: picking the human brain» IEEE Spectrum, 25(3), pp.36-41, March 1988.
4. М.И.Чебатко "Нейронные сети для решения задач на борту летательного аппарата" Зарубежная радиоэлектроника, №11-12, стр.40-44, 1994.
5. B.Widrow, M.Lehr "30 Years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation" Proceedings of the IEEE, Vol.78, 9, September 1990, pp.1415-1442.
6. А.Ю.Лоскутов, А.С.Михайлов "Введение в синергетику", М.: Наука, Физматлит, 1990.
7. http://www.basegroup.ru/tech/neural.shtml
8. Вороновский Г.К. и др. "Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности" Харьков: Основа, 1997, 112 с.
Конец цитирования.
Итак, что изменилось?
Единственно глобальное, существенно возросла производительность процессоров. Теперь даже в обычном смартфоне можно "поселить" немаленькую НС.
Еще научились выделять характерные черты и создавать компактные входные образы. Так, для распознавания лиц людей используется всего лишь 83 числа. Т.е. изображение нашей физиономии описывается-кодируется посредством 83-х чисел.
Еще продвинулись в методах обучения. Но для распознавания нескольких миллионов лиц при обучении НС надо задействовать кластер супер компьютеров и гонять эдак с месецок.
Главное же пока остаётся в зыбком тумане. Искусственному интеллекту (в частности, нейронным сетям) свойственно иногда ошибаться (чудить – как и любому мозгу). Причем когда именно будут происходить глюки - аналитического решения до сих пор (2023 год) еще не придумали. И если при том же распределении целей военное применение ИИ оправдано (когда промах вписывается в допустимый процент боевых потерь), то что делать на гражданке с новым чудом науки и техники - большой вопрос. Но про это, ясен пень, ни гу-гу. Большой секрет больших корпораций...