Стандартным приемом для определения взаимосвязи между числовыми колонками является вычисление коэффициента корреляции Пирсона, однако с категориальными данными такой финт не пройдет, так как они, как правило, не упорядочены (читай тут). Рассмотрим способ, который можно использовать. Сначала сгенерируем тестовый набор данных, о присутствии автомобилей разных марок в заданных локациях:
import numpy as np
import pandas as pd
np.random.seed(0)
autos_l = ['BMW', 'Mercedes', 'VOLGA', 'GEEP']
locations_l = ['Russia', 'Germany', 'USA']
prob_d = {'BMW':[0.2, 0.7, 0.1], 'Mercedes':[0.15, 0.75, 0.10],
'VOLGA':[0.99, 0.01,0], 'GEEP':[0.1, 0.3, 0.6]}
N=1000
autos = np.random.choice(autos_l, size=N)
locations = [np.random.choice(a=locations_l, p=prob_d[it]) for it in autos]
df = pd.DataFrame({'auto':autos, 'location':locations})
df.head(3)
Сформируем таблицу частот встречаемости машин в локациях:
df_stat = df.groupby(['auto', 'location']).size().unstack().fillna(0)
df_stat['total_row'] = df_stat.sum(axis=1)
df_stat.loc['total_col'] = df_stat.sum(axis=0)
df_stat
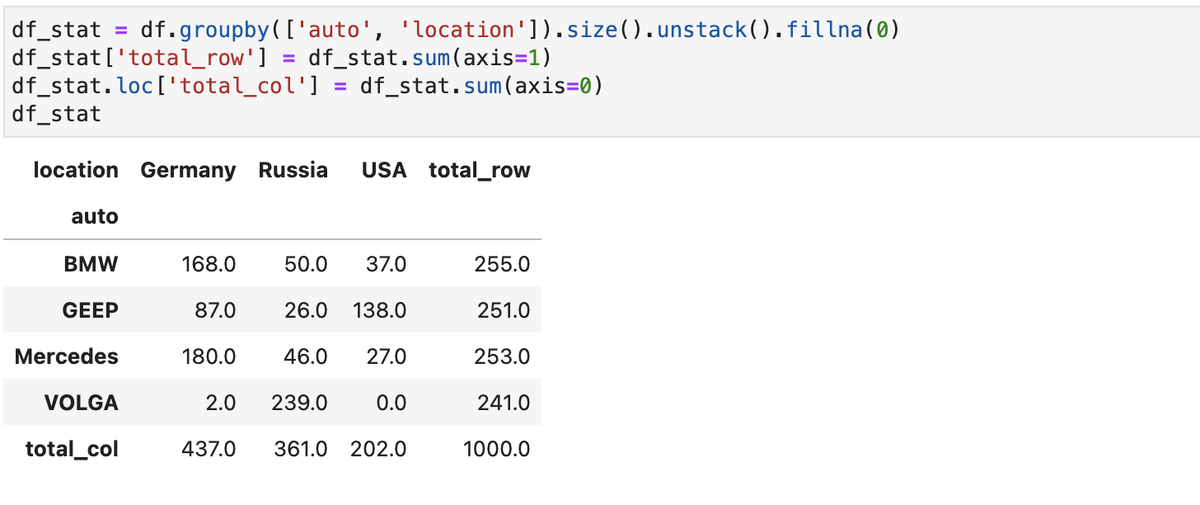
Для установления взаимосвязи воспользуемся хи-квадрат тестом Пирсона, который заключается в сопоставлении таблицы встречаемости с ее аналогом для случая ожидаемого распределения, которое равно произведению вероятностей относится к локации и бренду на общее количество точек (N). Вот вероятности:
Пирсон обосновал, что при больших N и истинности нулевой гипотезы, что взаимосвязь отсутствует, сумма ниже стремится к хи-квадрат распределению с k степенями свободы:
Статистика, вычисляемая путем подстановки наблюдаемых значений в формулу, призвана определить, насколько вероятной будет итоговая величина при истинности нулевой гипотезы. Если меньше уровня значимости, то принимается альтернативная гипотеза о взаимосвязи между признаками.
Ручной подсчет
Построим таблицу ожидаемых наблюдений:
from itertools import product
df_rand_stat = df_stat.copy()
pairs = product(df_rand_stat.index[:-1],df_rand_stat.columns[:-1])
for (model, country) in pairs:
df_rand_stat.loc[model, country] = (df_stat.loc['total_col', country]/N)*\
df_stat.loc[model, 'total_row']
df_rand_stat
Затем посчитаем хи-квадрат статистику по формуле:
xi2_stat = (((df_stat.iloc[:-1,:-1]-df_rand_stat.iloc[:-1,:-1])**2)
/df_rand_stat.iloc[:-1,:-1]).sum().sum()
xi2_stat
Степени свободы считаются по следующей формуле:
table = df_stat.iloc[:-1, :-1]
dof = table.size - sum(table.shape) + table.ndim - 1
dof
Вызовем функцию chdtrc модуля scipy.special, которая получает степени свободы и хи-квадрат статистику и возвращает вероятность, что случайная величина принимает не меньшие значения, чем заданное:
from scipy import special
special.chdtrc(dof, xi2_stat)
Автоподсчет
Имея только таблицу совместной встречаемости, можно было посчитать то же автоматически с функцией chi2_contingency модуля scipy.stats:
from scipy.stats import chi2_contingency
chi2_contingency(table)