Каждый год машинное обучение становится более совершенным. Сейчас так вообще. Но концепция: чем больше обучающих данных, тем лучше производительность — будет работать всегда независимо от степени развития ИИ. Чтобы нейросеть училась быстрее и меньше ошибалась, нужна помощь человека — такой подход называется HITL, или ручное распознавание. Рассказываем про него подробнее.
Что такое HITL
Human-in-the-loop (HITL) — это подход, когда алгоритмы на основе машинного обучения работают вместе с людьми в реальном времени. Например, когда ИИ не может разобрать слово «шиншилла», которое вы написали от руки. В таком случае задачка попадёт верификатору-человеку. Важно, что после такого, ИИ уже будет знать как определять рукописную «шиншиллу» в тексте. Такое дообучение модели позволяет повысить точность распознавания до 100%.
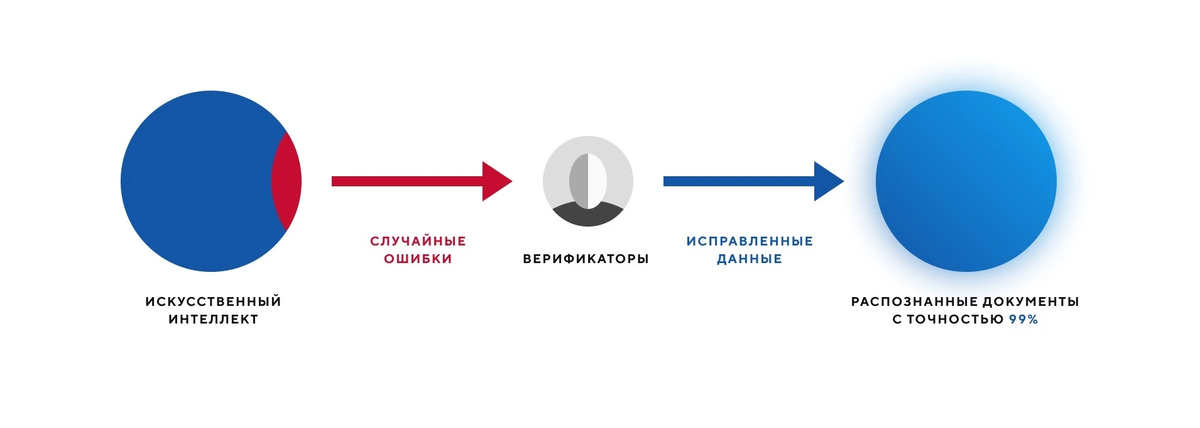
Как работает HITL
Перед распознаванием текста все документы нарезаются на отдельные поля. Затем нейросеть предсказывает, что внутри них написано. После этого другой алгоритм сравнивает, насколько распознанная буква или цифра в поле походит на ту, что когда-то нейросеть уже видела. В результате для каждого поля устанавливается степень уверенности в правильности распознавания. Если это число ниже нужного, то распознанный текст отправляется на проверку человеку.
На этапе ручной разметки мы первым делом спрашиваем нескольких человек: действительно ли на изображении написано то, что распознала нейросеть?
Если оба отвечают «да», то нейросеть радостно продолжает работать дальше
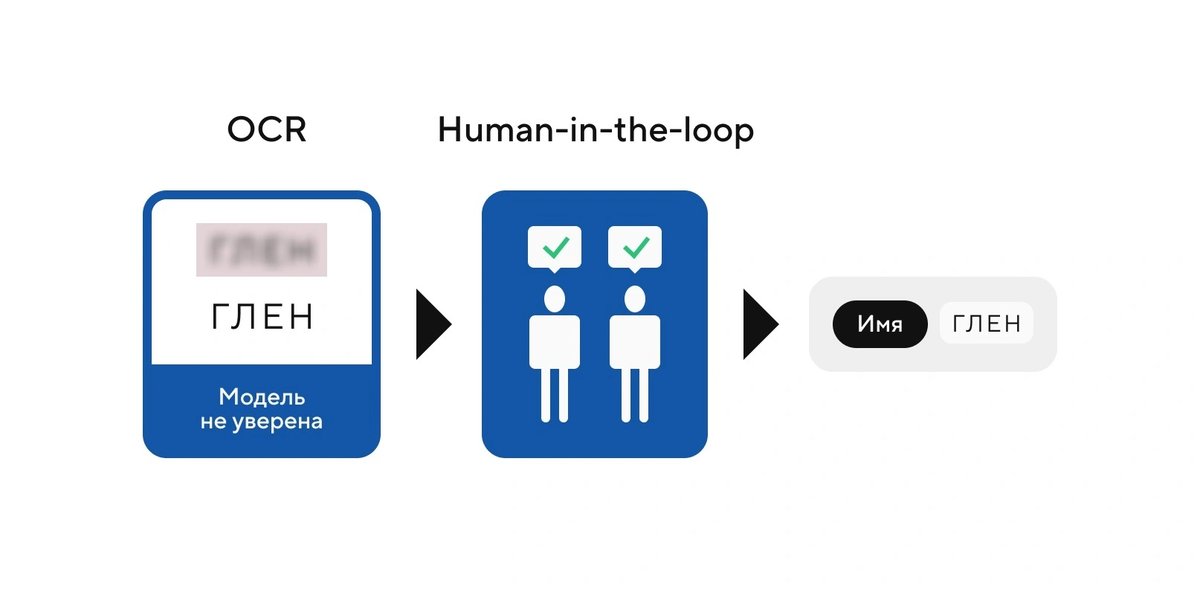
В случае, если первый или второй человек ответил «нет» — изображением отправляют на второй этап, где люди вручную оцифровывают текст с картинки.
В Dbrain в качестве платформы ручной разметки используем «Яндекс.Толоку». Благодаря огромному количеству пользователей-верификаторов запросы обрабатываются в любое время суток. При этом все данные деперсонализированы: для разметки один человек получает поля из разных документов, поэтому собрать полный набор информации не получится.
Как проверяем корректность ручного распознавания
В ручном распознавании участвует до семи человек — и всем нужно прийти к одному мнению, что же все-таки написано в поле.
Есть простые поля, такие как фамилия, место или дата рождения. В этом случае всё довольно просто: для сравнения мы используем посимвольное соответствие. Тот текст, который совпал с точностью до символа у большей части людей, считается верным.
Но бывают и более сложные ситуации. Например, описание места ДТП из европротокола. В этом случае мы применяем расстояние Левенштейна.
Чтобы не лезть в гугл: расстояние Левенштейна, или редакционное расстояние, — метрика cходства между двумя строковыми последовательностями. Чем больше расстояние, тем более различны строки. По сути, это минимальное число односимвольных преобразований (удаления, вставки или замены), необходимых, чтобы превратить одну последовательность в другую.
Также есть различные приемы, которые работают только для конкретного поля. Например, для блока регистрации по месту жительства используются всплывающие подсказки на основе данных из Федеральной информационной адресной системы. В этом случае правильность ответа оценивается по длине ответа разметчиков. Допустим, есть три варианта: «Северодвинск, улица Ломоносова», «Северодвинск, улица Ломоносова, дом 3, квартира 5» и «Северодвинск, улица Ломоносова, дом 3». В этом случае нейросеть примет второй вариант.
При распознавании автомобильных номеров алгоритм будет смотреть, насколько в целом возможно существование такой комбинации. А марка автомобиля сравнивается с нормативным написанием. Мы просим людей писать все слова так, как написано в словаре, а не в документе, чтобы клиент на выходе получил нормализованный ответ. Неважно, как человек написал в документе Chevrolet: «Шевроле», Chevrole, Shevrole или как-то еще. Правильно будет указать в качестве распознанного текста Chevrolet. А модель машины должна четко соответствовать марке. И та или иная проверка есть для каждого поля.
Что дает HITL
Чем больше нейросеть получает данных для обучения, тем выше точность ее распознавания. Например, за полгода обучения на данных компании точность нейросети может вырасти с 50% до 98%. Дообучение, основанное на HITL, в перспективе удешевляет и ускоряет процесс, так как алгоритмы могут правильно распознавать как можно большее число полей в документах.
Машинное обучение, которое работает в синергии с человеком, — тренд последних несколько лет уже не только среди крупных корпорации, но и малых и средних компаний. У такого взаимодействия есть ряд плюсов:
- Автоматизация задач снижает нагрузку с персонала
- Участие людей повышает точность нейросети как в моменте, так и в перспективе
- Нейросеть учится на данных компании.
Вместо итогов
Доступность ИИ и сценарии его применения растут с каждым годом. Сегодня можно распознать текст даже на плохом изображении и легко понять, какой перед нами документ. Во многом это становится возможным благодаря использованию решений на базе машинного обучения. Собрав дополнительный набор данных, можно повысить точность для любой задачи.
Мы не только создаем нейросети, но и рассказываем о важных событиях из мира ИИ Telegram-канале.