Большинство ML моделей обучаются только одной задаче, в результате, многим сложно интуитивно понять, как модель может быть обучена нескольким задачам одновременно.
Многозадачное обучение (MTL) похоже на механизм человеческого обучения. Например, обучение езде на велосипеде облегчает обучение езде на мотоцикле, что основано на аналогичной концепции баланса тела. Механизмы передачи знаний позволяет людям изучать новые концепции с помощью всего нескольких примеров или вообще без них. Точно так же нейронные сети, обученные выполнять одну задачу, должны изучать все основные концепции с нуля, которые могли бы быть получены из других задач в качестве вспомогательной информации.
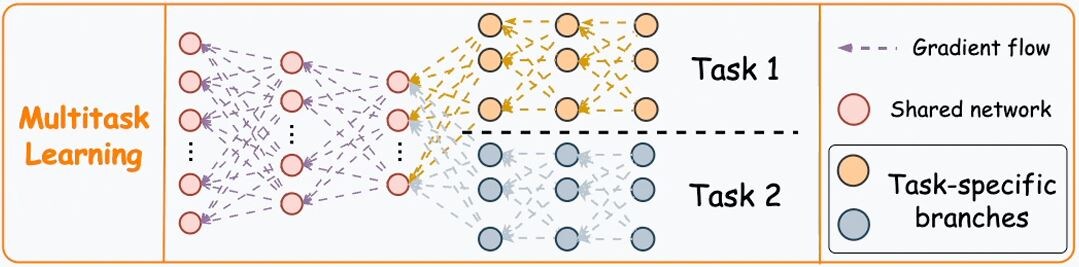
Напомним, что в основе MTL лежит архитектура сети, состоящая из - общего сегмента (выделен розовым), а также, как минимум двух задача-ориентированных сегмента (выделены красным и серым), как показано на Рис. 2 ниже.
Давайте рассмотрим простой пример, чтобы понять, как это все работает. Предположим, наша модель должна принимать в качестве входных данных значения (x) и предсказывать два выходных значения:
- sin(x)
- cos(x)
Для наглядности рассмотрим данный пример в коде (PyTorch), который будет состоять из трех этапов:
- Конфигурирование сегментов
- Конфигурирование взаимодействия сегментов
- Конфигурирование процесса обучения
Этап 1 (Конфигурирование сегментов)
Из примера выше, видно:
- Данная модель будет состоять из трех сегментов
- Первый сегмент – это общий входной сегмент, который называется self.model.
- Два задача-ориентированных сегмента, которые будут заниматься прогнозированием sin(x) / сегмент self.model_sin и cos(x) / сегмент self.model_cos.
- В качестве функции активации для каждого из сегментов будет использоваться - ReLU
Этап 2 (Конфигурирование взаимодействия сегментов)
Давайте определим, как эти сегменты будут взаимодействовать между собой.
Из примера выше, видно:
- Входные данные (х) передаются на общий сегмент сети (self.model)
- Выходные данные с общего сегмента (self.model) передаются на входы двух задача-ориентированных сегментов (self.model_sin и self.model_cos)
- На выходах задача-ориентированных сегментов предсказываются значения sin(x) и cos(x)
Такая сетевая архитектура может быть представлена следующим образом:
Этап 3 (Конфигурирование процесса обучения)
Заключительным этапом данной модели является конфигурирование процесса обучения.
Из примера выше, видно:
- В качестве функции потерь выбрана - среднеквадратическая ошибка (MSELoss)
- Значения функций потерь двух задача-ориентированных сегментов складываются (loss=loss1+loss2), чтобы получить общую ошибку
- Выполняется обратное распространение ошибки (loss.backward)
По результатам процесса обучения (см. Рис. 6 / Decreasing loss), видно, что потери с каждым циклом обучения (Epoch) уменьшаются - это говорит о том, что модель обучается.
Давайте подведем Итог всего вышесказанного:
- Входные данные (x) поступают на общий сегмент сети self.model
- Далее они попадают на входы двух задача-ориентированных сегментов self.model_sin и self.model_cos
- Модель предсказывает два значения (sin(x) и cos(x)), по одному для каждого задача-ориентированного сегмента
- Вычисляются два значения функций потерь (на базе предсказанных и истинных значений), по одному для каждого задача-ориентированного сегмента
- Два значения функций потерь складываются, для получения общих потерь сети.
- Выполняется обратное распространение ошибки (см. Рис 2 Gradient flow) для обновления весов и смещений всех сегментов сети
Надо помнить, что построение MTL-модели на основе «несвязанных» задач не даст хороших результатов, поэтому «взаимосвязанные» задачи является критически важной особенностью для всех MTL-моделей, из-за наличия общего сегмента сети.
Кроме того, необязательно, а часто это противопоказано, чтобы потери по каждой из задач в равной степени влияли на величину общих потерь. Каждой задаче можно присваивать свой вес (c1 и c2), как показано на Рис. 7, ниже.
Веса могут задаваться, как на основании «важности» задачи, так и использовать динамический принцип (см. Рис. 8), когда каждый вес обратно пропорционален достигнутой точности для каждой из задач.
Задача по MTL оптимизации весов является творческой и одной из самых важных, поскольку целиком и полностью влияет на процесс обучения модели. Веса должны быть оптимизированы таким образом, чтобы результаты одного сегмента не тянули всю модель в пропасть.