Если раньше на овладение чем-то уходили тысячи лет, потом сотни, десятки, годы, то сейчас — дни. Прогресс происходит очень быстро и унизительно. Техника настолько мощная, что создает подделки лучше, чем оригиналы. (С) Татьяна Черниговская
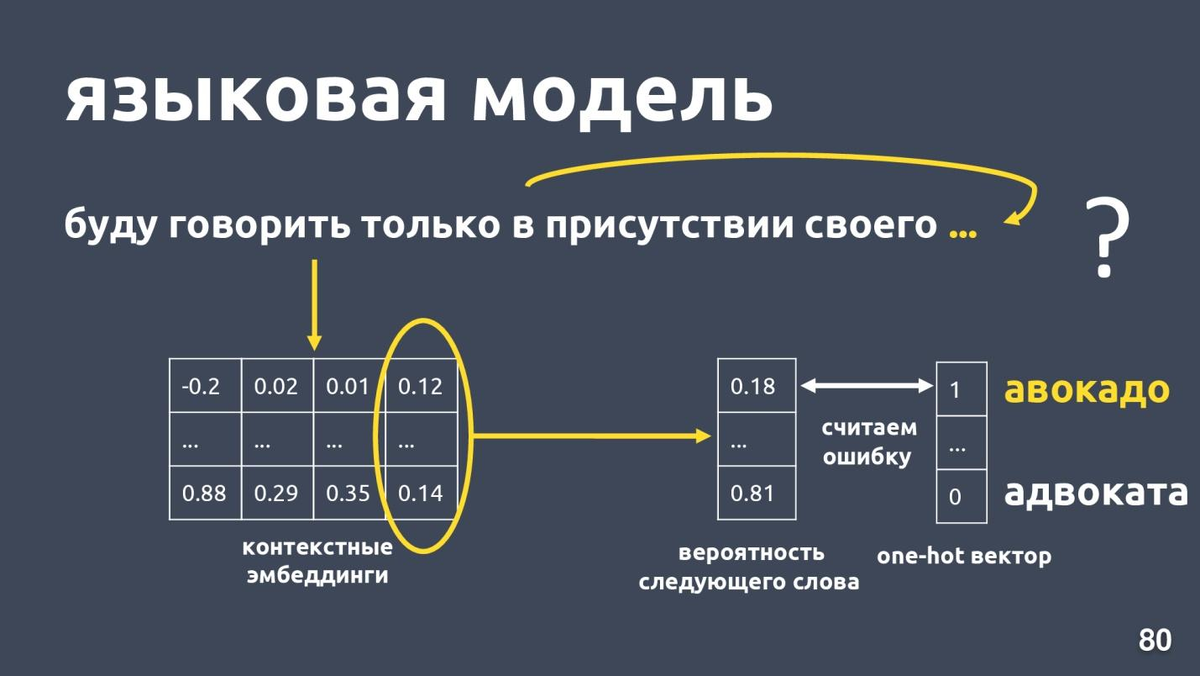
Основная цель создания языковых моделей — выявление закономерностей в тексте, позволяющих строить связи между словами, похожие на такие, которые складывают между словами люди при написании этих текстов. Имея хорошую модель можно выполнять с текстом преобразования, результаты которых будут выглядеть осмысленно и разумно для человека. Это может быть машинный перевод с одного языка на другой, составление заголовков и аннотаций , генерация вопросов и ответы на них, поиск релевантных фрагментов текста и конструирование из них связной статьи, синтез программ по текстовому описанию и многое другое, что обычно является продуктами умственного труда людей.
Хорошей основой для языковой модели, полученной с помощью машинного обучения, являются искусственные нейронные сети различной архитектуры. Одной из наиболее востребованных сейчас является сеть «преобразователь» (transformer), представленная в 2017 году исследователями из Google. Преобразователь получает на вход некоторую последовательность данных и создаёт цифровое представление о значении каждого её элемента в окружающем контексте. За это отвечает ключевой элемент любого преобразователя — механизм самовнимания (self-attention). Он определяет, какие токены необходимы для правильного понимания того или иного токена последовательности.
Этот механизм позволяет нейронной сети более эффективно справляться с интерпретацией предложений, в которых одни и те же слова имеют разный смысл. Например:
“The needle has a sharp point.” (Point = Tip)
“It is not polite to point at people.” (Point = Gesture)
В первом случае point нужно интерпретировать как наконечник, а во втором как жест.
Рассмотрим как это работает.
1. Входные данные проходят некоторые предварительные этапы преобразований: токенизацию и векторизацию. Последовательность делится на части которые могут представлять собой слова, части слова, разделители, специальные символы. Эти части называются токенами. Каждый токен преобразуется в столбец чисел, называемый вектором. Набор таких векторов образует матрицу встраивания (Embedding matrix).
Преобразователи не имеют встроенного понимания порядка элементов в последовательности. Поэтому, чтобы данные в процессе трансформации не превратились в «мешок слов» дополнительно применяется позиционное кодирование (positional encoding): к каждому входному вектору добавляется позиционный вектор, который кодирует информацию о позиции элемента в последовательности.

Обычно позиционные векторы вычисляются с использованием синусоидальных функций разной частоты, что позволяет модели различать позиции элементов и учитывать их порядок.
2. Для каждого вектора входной матрицы, вычисляются три проекции: Query (запрос), Key (ключ) и Value (значение). Это делается путём умножения входного вектора на обучаемые матрицы.
3. Для каждого элемента последовательности вычисляется «вес» относительно всех других элементов и формируется матрица весов, которую называют «оценкой внимания» (attention score) . Это делается через скалярное произведение Query и Key, нормализованное с помощью softmax. Такой подход называется scaled dot-product attention и он даёт контекстуализированную матрицу встраивания с помощью линейной комбинации исходных векторов.
4. Полученные веса используются для взвешивания Value-векторов, и результат суммируется. Итоговая матрица встраивания содержит информацию о том, какие элементы последовательности наиболее важны для текущего элемента.
После применения механизма внимания каждый элемент последовательности проходит через позиционно-независимую Feed-Forward сеть (FFN).
Эта сесть состоит из двух линейных слоёв с нелинейностью (например, ReLU) между ними. Она выполняет следующую роль:
- Обобщение представлений: Feed-Forward сеть позволяет модели преобразовывать информацию, полученную на этапе самовнимания, в более сложные представления.
- Обработка каждого элемента отдельно: В отличие от самовнимания, Feed-Forward сеть применяется к каждому элементу последовательности независимо.
Перечисленные выше блоки повторяются несколько раз, образуя многослойную структуру для выявления более сложных закономерностей в данных. Каждый такой слой может отражать свои аспекты исследуемой последовательности и может требовать внимания к другим её частям. Поэтому в таких многослойных сетях используется механизм многоголового внимания (multi-head attention).
В многоголовом внимании входные данные (векторы Query, Key и Value) разделяются на несколько подпространств меньшей размерности. Каждая «голова» работает с этими уменьшенными представлениями. Например, если размерность векторов равна 512, а число голов — 8, то каждая голова будет работать с векторами размерности 512/8 =64.
Каждая голова независимо вычисляет механизм внимания (self-attention) для своей части данных. После этого результаты объединяются (конкатенируются) и проходят через линейный слой, чтобы вернуть данные в пространство исходной размерности.
Помимо перечисленных выше компонентов не структуру преобразователя входят также такие блоки как нормализация слоёв (Layer Normalization) и связи с пропусками (Skip connections) . Нормализация слоёв может применяться после каждого подслоя, например, после внимания и полносвязных слоёв. Она помогает стабилизировать градиенты и ускорить сходимость модели. Связи с пропусками, также известные как «residual connections», позволяют информации «перескакивать» через один или несколько слоёв. Это делается путём добавления входа слоя к его выходу перед нормализацией. Данный приём используется для смягчения проблемы затухающих градиентов при обучении модели более глубоким структурам.
Комбинируя эти блоки в различных сочетаниях получаются различные архитектуры преобразовательных нейронных сетей. По-крупному их можно объединить в три группы.
1. Кодеры. Такие преобразователи синтезирую контекстуальные встраивания, которые можно использовать в последующих задачах (классификации, распознавании именованных сущностей и т. д.)
2. Декодеры. Этот тип архитектур почти идентичен предыдущему, главное отличие в том, что декодеры используют маски̒рованный (или причинный) слой self-attention, поэтому механизм внимания может принимать только текущий и предыдущие элементы входной последовательности. То есть контекстуальные эмбеддинги учитывают только предыдущий контекст. К популярным моделям-декодерам относится семейство GPT.
Поскольку они могут оперировать только текущей и предыдущими позициями, декодеры обычно используются для авторегрессионных задач, таких как генерирование последовательностей. Без фильтрации мы получим распределение вероятностей по каждому токену в словаре модели. Для уменьшения количества возможных вариантов применяют различные фильтры:
- по температуре, которая влияет на случайность генерируемого текста, чем она больше, тем больше разнообразие выходных результатов;
- по TOP-P выборке, которая меняет распределение вероятности в зависимости от кандидатов, превысивших определённый порог;
- по TOP-K выборке, которая ограничивает число потенциальных кандидатов количеством наиболее вероятных токенов.
После того, как мы изменили или уменьшили распределение вероятностей по потенциальным кандидатам для следующего токена, мы можем сделать из неё выборку для получения предсказания: это просто выборка из полиномиального распределения. Предсказанный токен затем прилагается к входной последовательности подается обратно в модель, пока не будет сгенерировано желаемое количество токенов или пока модель не синтезирует токен остановки, обозначающий конец последовательности.
3. Кодеры-декодеры. Кодер преобразует входную последовательность в вектор, в то время как декодер преобразует этот вектор обратно в последовательность. Каждый слой кодировщика и декодировщика включает слои самовнимания и прямой связи. В декодере слой внимания кодировщика-декодировщика добавляется для фокусировки на соответствующих частях входных данных.
Кодер состоит из нескольких слоев. Каждый слой имеет два основных компонента: Механизм самовнимания — помогает модели понимать связи слов. Нейронная сеть прямой связи (Feed-Forward)— дополнительно преобразует представление. Декодер также состоит из нескольких слоёв, но с дополнительным механизмом внимания кодировщика-декодировщика. Это позволяет декодеру фокусироваться на соответствующих частях входного предложения при генерации выходных данных.
Главное отличие архитектур типа энкодер-декодер заключается в том, что декодер использует энкодер-декодерное внимание: при вычислении внимания используется результат энкодера (K и V) и входные данные декодера (Q). Такого типа преобразователи ещё называют Sequence to Sequence Transformers (Seq2Seq) и изначально они применялись для машинного перевода. Однако их можно использовать и для других задач — ответов на вопросы, суммаризации, классификации. В качестве распространённых примеров выступает ответвление моделей такого типа под названием T5 (Text-to-Text Transformer).
Именно с этого типа преобразователей я решил начать своё знакомство. Имея представление об архитектуре и базовой математике, можно было бы это сделать на голом Numpy (возможно, что даже полезнее). Однако для первого знакомства, когда подводных камней слишком много и каждый из них может быть значительным преткновением, большие шансы на успех затеи дают более специализированные продукты. Я выбрал для этого OpenNMT, поскольку пример его успешного использования уже неплохо описал наш эксперт по машинному обучению — Михаил Утробин вот здесь.
OpenNMT — это инструментарий с открытым исходным кодом для обучения моделей машинного перевода, включая модели seq2seq. Для эффективного инференса (вывода) моделей, обученных с помощью OpenNMT есть довольно простая и удобная библиотека CTranslate2.
Начинать знакомство с чем-то новым лучше с сайта разработчика и предоставленной им документации. Насчёт OpenNMT есть две ветви:
- На основе PyTorch и на основе TensorFlow. Меня пока-что заинтересовала PyTorch версия, переходим сюда.
Для установки запускаем терминал вводим команду:
pip install OpenNMT-py
Для экспериментов понадобятся видеокарта с поддержкой CUDA и установленный torch.
Проверим, есть ли у нас CUDA введя команду nvidia-smi
Если у нас нет CUDA, можем переместиться в облако
Где минимальная стоимость наших экспериментов составит 23 р за час (дадут NVIDIA 2080Ti). Или же воспользоваться щедротами Google, которая предоставляет всем желающим NVIDIA T4 бесплатно примерно на 2 часа в сутки в колабе.
Проверить наличие torch можно командой:
pip show torch
Если не установлен, то устанавливаем:
pip install torch torchvision torchaudio
Всё что нужно сделать перед запуском обучения модели — собрать два набора данных и прописать настройки в конфигурационный файл. Два файла, содержащих входные и выходные последовательности для обучения (чем больше тем лучше) и ещё два файла с подобными образцами, но в гораздо меньшем количестве для проверки - это обычные текстовые файлы, обучающие примеры в которых записаны построчно. Каждая строка — один отдельный пример.
src-train.txt — входные последовательности для обучения
tgt-train.txt — выходные последовательности для обучения
src-val.txt — входные последовательности для проверки
tgt-val.txt — выходные последовательности для проверки
Для проверки достаточно несколько тысяч записей.
Вот как это выглядит:
Эти файлы нужно помести в каталог /run/split_data, находящийся внутри каталога с установленным пакетом openNMT. В этом же каталоге нужно найти и отредактировать конфигурационный файл config.yaml
Здесь стоит отметить связь между размером словаря (src_vocab_size) и размерностью векторного пространства встраивания (word_vec_size). Если словарь будет слишком велик по сравнению с размерностью векторного пространства, вероятно модель не сможет достаточно хорошо обобщать данные, т. к. может потеряться слишком большая часть атрибутов текста. С другой стороны если размерность векторного пространства будет слишком велика это усложнит обучение и сделает инференс готовой модели медленным. Нужен компромисс, который видимо подбирается экспериментально. Здесь получилось соотношение 12000:768=15,625, что (как мне кажется) должно быть оптимальным.
Теперь, задавшись словарём 12000 его ещё нужно обучить. Можно использовать библиотеку sentencepiece, которая достаточно хорошо решает эту задачу в двух вариантах: Byte Pair Encoding (BPE) и Unigram Language Model. Для русского языка, вероятно второй вариант может дать лучшие результаты.
Устанавливаем если ещё не установлена эту библиотеку:
pip install sentencepiece
Создаём каталог в который помещаем текст, на котором будет происходить обучения токенизатора. Я для этого взял 100 Мб текстов на русском языке, отфильтрованных от посторонних символов. И столько же на английском.
В терминале перейдём в этот каталог и выполним команду:
spm_train --input=tvocab.txt --model_prefix=updated_model --vocab_size=12000 --model_type=unigram --add_dummy_prefix=false —shuffle_input_sentence=true
После завершения обучения токенизатора в этом каталоге появятся два файла:
- sentencepiece.model
- sentencepiece.vocab
Их нужно переместить к каталог с openNMT и затем перевести его в формат, который будет использоваться во время обучения языковой модели:
onmt_build_vocab -config config.yml -n_sample -1
Теперь всё готово для запуска процесса обучения.
Вводим команду:
onmt_train -config config.yml
И через некоторое время получаем первое сообщение о начале процесса обучения:
encoder: 37547520 — это количество обучаемых параметров в энкодере. В нашемслучае энкодер состоит из 6слоёв трансформера, каждый из которых содержит механизмы внимания и полносвязные слои.
decoder: 42508512 — это количество обучаемых параметров в декодере. У нас декодер состоит из 6слоёв трансформера.
number of parameters: 80056032— общее количество параметров модели (энкодер + декодер). Это сумма параметров энкодера и декодера.
Чем больше параметров, тем больше вычислительных ресурсов требуется для обучения модели.
Step 50/50000 — текущий шаг обучения (50) и общее количество шагов, которые планируется выполнить (50000).
- acc: 4.4 — точность (accuracy) на текущем шаге. В начале обучения она часто близка к нулю, так как модель ещё не научилась предсказывать правильные токены.
- Ppl: 8786.6 — perplexity (перплексия). Это метрика, которая показывает, насколько хорошо модель предсказывает последовательности. Чем ниже значение, тем лучше. В начале обучения перплексия обычно очень высокая, но по мере обучения она должна уменьшаться.
- xent: 9.1 — кросс-энтропия (cross-entropy loss). Это основная функция потерь, которую минимизирует модель. Чем ниже значение, тем лучше. В начале обучения оно обычно высокое.
- lr: 0.00001 — текущая скорость обучения (learning rate). В вашем случае она близка к нулю, что может быть связано с использованием планировщика (scheduler), который пока не начал увеличивать скорость обучения.
- sents: 35421 — общее количество предложений, обработанных на текущий момент.
- bsz: 7332/6775/177 — размер батча (batch size). В OpenNMT-py используется динамический батч, и здесь указаны:
7332 — общее количество токенов в текущем батче.
6775 — количество предложений в текущем батче.
177 — количество батчей, обработанных на текущий момент. - 14291/13206 tok/s — скорость обработки токенов:
В процессе обучения нужно следить за перплексией и кросс-энтропией:
- Если ppl и xent уменьшаются, значит, модель обучается корректно.
- Если значения долго не меняются или растут, это может указывать на проблемы (например, слишком высокая скорость обучения или недостаточный размер батча).
- Скорость обучения (lr):
Убедитесь, что скорость обучения начинает увеличиваться после нескольких шагов (если вы используете планировщик). Если она остаётся нулевой, проверьте конфигурацию планировщика. - Точность (acc):
В начале обучения точность может быть нулевой, но со временем она должна увеличиваться. Если этого не происходит, возможно, модель слишком сложная или данные недостаточно качественные. - Скорость обработки токенов:
Если скорость обработки слишком низкая, попробуйте увеличить размер батча или оптимизировать код.
Вот что у меня, к примеру получилось на 50000 шаге:
openmt.model_step_50000.pt
Train perplexity: 9.43164
Train accuracy: 76.9439
Validation perplexity: 11.1535
Validation accuracy: 74.2011
На этом обучение остановилось, но у меня позже появился другой набор данных и я продолжил обучение с этой контрольной точки. Для этого нужно заменить файлы src и tgt на новые и увеличить количество шагов обучения в конфигурационном файле. После этого достаточно ввести команду:
onmt_train -config config.yml --train_from run/openmt.model_step_50000.pt
И процесс обучения продолжится.
Вот что получилось на 135000 шаге:
2025-02-14 00:25:57,961 INFO] Train perplexity: 9.40808
[2025-02-14 00:25:57,962 INFO] Train accuracy: 76.1039
[2025-02-14 00:25:57,962 INFO] Sentences processed: 1.04445e+07
[2025-02-14 00:25:57,962 INFO] Average bsz: 7670/6123/43
[2025-02-14 00:25:57,962 INFO] Validation perplexity: 17.8735
[2025-02-14 00:25:57,962 INFO] Validation accuracy: 64.2943
[2025-02-14 00:25:57,962 INFO] Decreasing patience: 1/4
С другим набором данных результат на проверочных данных выглядит слабее. Но там и данные более сложные и последовательности в среднем длиннее.
На 140000 я решил прекратить обучение этой модели, т. к. дальнейшего прогресса не наблюдалось.
Теперь осталось конвертировать в модель в форматы, более удобные для инференса.
Вводим команду:
onmt_release_model --model run/openmt.model_step_140000.pt --format ctranslate2 --output ct2_model
И из каталога ct2_model забираем набор файлов модели, пригодной для работы с ctranslate.
Выполним также команду из папки OpenNMT-py/tools:
./average_models.py -m ~/openmnt/run/openmt.model_step_70000.pt ~/openmnt/run/openmt.model_step_140000.pt -o ~/openmnt/run/averaged.pt
И получим усреднённую модель averaged.pt с которой можно работать средствами openNMT
Также конвертируем её в квантованную версию. Из каталога opennmt запустим команду:
ct2-opennmt-py-converter --model_path run/averaged.pt --output_dir run/model --quantization int8
И получим набор файлов квантованной модели в каталоге run/model
Теперь, когда у нас есть файлы модели, можно приступать к исследованию её возможностей. Готовые файлы можно скачать отсюда:
https://huggingface.co/Vladniag/Requestor
Для начала установим ctranslate:
pip install ctranslate2
И попробуем базовый скрипт:
test.py:
В терминале перейдём в каталог со скриптом и запустим его, введя команду:
python test.py
Изменим запрос в скрипте на «Переведи кратко» и посмотрим что получится:
Вот что получилось:
Таким запросам модель не обучалась. Но зато были примеры краткой суммаризации и краткого перефразирования. Поэтому в разных случаях с таким запросом она ведёт себя похоже на один запрос или на другой. Может просто отбросить часть предложений, которые посчитает не важными для передачи ключевой идеи. Иногда, если текста слишком мало, может оставить от предложения лишь несколько слов.
Посмотрим как в таком случае будет выглядеть краткая суммаризация:
Почти один в один как краткий перевод.
Преобразуем текст в заголовок с помощью команды «составь заголовок»:
Сформулируем вопрос:
Спросим модель, о чём этот текст:
Попросим составить пошаговый план, который приведёт к написанию этого текста:
На пункт 2 не хватило контекстного окна. Максимальная длина последовательности, обрабатываемой моделью за раз — 256 токенов. И этот блок текста примерно столько и составляет.
Можно получить другой вариант вопроса изменив команду, на такую: «Сформулируй вопрос шаг за шагом»:
В обучающем наборе данных были такие примеры, но мало, всего тысяч 30, поэтому действительно вопросы с рассуждением по шагам она формирует очень редко. Но чаще получаются просто другие вопросы.
Посмотрим как рабивается текст на токенизатором со словарём всего в 12000:
Английский и русский текст разбивается практически на одинаковое число токенов — 25 и 21. А если разделить по пробелам и за отдельные части знаки препинания получится 16 и 18 Т.е. для русского текста соотношение слов к токенам 1.56, а для английского 1.16, что, похоже, не хуже чем у токенизаторов с куда более крупными словарями (обычно 50000 и больше).
В метод translate_batch можно передавать дополнительные параметры, влияющие на результаты выдачи модели.
max_decoding_length — задаёт максимальное число генерируемых токенов. Его можно ограничить, чтобы ускорить выдачу и уменьшить вероятность повторов.
num_hypotheses — задаёт количество вариантов ответа на запрос, которые модель должна сформировать.
return_alternatives — выдавать альтернативные варианты или нет.
Сформируем 5 вариантов вопроса к тексту из примера:
Пять вариантов одного и того же вопроса. Похоже это указывает на то, что в наборе данных по формированию вопросов было не достаточно высокое разнообразие. С одной стороны это разочаровывающий результат. А с другой модель более может быть предсказуема в ответах, что в некоторых случаях может быть как раз неплохо.
Пять заголовков:
Попробуем с другой командой:
Часть заголовков изменилась, но всё-таки это заголовки. А часть превратилась в краткое обобщение.
Какое практическое применение у модели с такими ограничениями? Я рассматриваю её прежде всего как инструмент, с помощью которого появляется возможность быстрого формирования наборов данных для более сложных моделей. Т.к. эта модель довольно мала, она работает быстро даже на процессоре, а если есть видеокарта NVIDIA — ещё быстрее. За сутки можно преобразовать английский набор данных, которых довольно много в открытом доступе в русский набор данных, которых пока что значительно меньше. Для понимания, на одном компьютере с NVIDIA RTX 1080 это примерно 12 млн. токенов за сутки непрерывной работы. Набор данных, который использовался при обучении этой модели содержит примерно 1.5 млрд. токенов, т. е. потребовалось бы 4 месяца. Скорость генерации более крупной моделью, уровня Mistral 7B примерно 2 млн. токенов за сутки, т. е. понадобилось бы 25 месяцев непрерывной работы. Если же вопользоваться такими сервисами как GigaChat от Сбера, то эта затея стоила бы мне примерно 200 тыс. рублей, что не вариант для простого удовлетворения своего любопытства.
Как обойти ограничения модели в размере контекстного окна. Всего 256 токенов — это очень мало для многих задач. Так например не получить общей суммаризации большого документа. Но проявив некоторую долю технической смекалки можно всё-таки суммаризировать документы значительно большего размера. Для этого можно применить частотный анализ из набора инструментов NLTK и алгоритм Луна, который позволяет выделить из текста наиболее значимые предложения. А уже их затем обобщить спомощью языковой модели, чтобы получился ещё более компактный результат.
Пример.
Продолжение
Продолжение
Продолжение
Продолжение
Результат:
Перевести большой текст можно значительно проще. Для этого нужно разбить текст на фрагменты по 256 токенов, перевести по очереди, а затем собрать в один большой текст.
Готовые исходники примеров по суммаризации и переводу можно скачать здесь: https://gitverse.ru/vlad-n-ag/SLM_Requestor
Там же есть пример программы, с помощью которой можно получить BLEU метрики перевода, показывающие насколько близок перевод сделанный машиной к эталонному переводу (0 - минимум схожести, 1 - максимальное сходство).
Average BLEU score (EN->RU): 0.2703
Average BLEU score (RU->EN): 0.3445
Получены на основе перевода эталонных русских и английских предложений, предоставленных Microsoft в количестве 1997 штук (MicrosoftTranslator /NTREX )
***
Для сравнения переводчик Михаила Утробина, которым я переводил многие тексты, вошедшие в мой набор данных имеет такие метрики:
Average BLEU score (EN->RU): 0,2858
Average BLEU score (RU->EN): 0,2735
Т.е. в переводе с английского на русский моя модель уступает модели Михаила, но в переводе с русского на английский превосходит её.
Курьёзы машинного перевода:
Министр финансов -> Секретарь сокровищ
Мучные червецы -> Тортированные червяки
Страна персиковых деревьев -> Пехтреевое государство
Свиновод -> Свинейный земледелец
Укрытия от цунами -> Цунамиские убежища
Подзаголовок к статье о перспективах применения мучных червецов в пищевой промышленности: "Этическая дилемма в мятежном потреблении: Погружение в пытливые черви".
Протестировать модель можно и без её скачивания и без программирования. Для этого на одном из моих домашних компьютеров развёрнут сервер: https://tolmacher.wia.su/
Пример. Генерация статьи на несколько тыс. токенов:
Команды «Выполни запрос», «Напиши статью» и «Перепиши статью» реализованы в дуэте с моделью QWEN 05B, здесь Requestor играет лишь роль переводчика и иногда составителя заголовков и вопросов.
Добавил API для тестирования своей модели ИИ через сайт tolmacher.wia.su/
Запросы можно отправлять методом POST на адрес:
tolmacher.wia.su/api/translate
Формат запроса- JSON, содержащий два поля: 'prompt' и 'content'
В поле prompt можно писать команды, подобные представленным на сайте: "Переведи на русский", "Переведи на английский" и т.д.
В поле content помещается сам текст, который необходимо обработать.
Максимальная длина одного запроса - 256 токенов, поэтому длинный текст нужно разбить на фрагменты и отправлять их на сервер по очереди. Модель обучалась суммаризации, определению темы, составлению заголовка и вопроса на фрагментах длиной 256 токенов состоящих как правило из 2-3 предложений не разделённых переносом строки. Именно в таком количестве она даст наилучший результат.
Пример тестового запроса из терминала Linux:
curl -X POST tolmacher.wia.su/api/translate -H "Content-Type: application/json" -d '{"prompt": "Переведи на русский", "content": "Quantum holograms: Metasurfaces entangle light and information in new study"}'
Пример ответа:
{"prompt": "Переведи на русский", "content": "Quantum holograms: Metasurfaces entangle light and information in new study", "result": {"eng": "Quantum holograms: Metasurfs entangle light and information in a new study.", "rus": "Квантовые голограммы: Метасурфы опутывают свет и информацию в новом исследовании."}}
Запросы "Выполни запрос", "Напиши статью" и "Перепиши статью" через API не работают, потому что эти функции выполняются в связке с ИИ моделью Qwen05B и выходят за рамки задач демонстрации возможностей модели Requestor. Там модель Requestor выступает лишь в роли переводчика и составителя заголовков.
Сервер работает в тестовом режиме. Поэтому в течении дня могут быть перебои в его работе. Но скорость близка к максимальной. Ночью он работает над генерацией новых датасетов, поэтому сбоев быть не должно, но скорость минимальна.
Чтобы получить красивую статью подобно тем, которые я приводил в качестве примера в предыдущих двух публикациях, необходима постобработка. Сначала статья генерируется Толмачёвой клёпой. Затем копируется в форму ввода и по ней генерируются вопросы. Затем текст статьи копируется на сайт https://chat.mistral.ai/ с предварительным промптом «Преобразуй этот текст в краткую статью» А в конце дополнительным промптом «в статье должны быть даны ответы на следующие вопросы» и далее те вопросы, которые были сгенерированы. Я мог бы добавить эти функции и получить конечную генерацию одним щелчком на кнопку, если бы у меня был доступ к API Mistral. Но на наши номера телефонов они не отсылают код подтверждения регистрации.
Источники:
- Deep Learning vs common sense: разрабатываем чат-бота
https://habr.com/ru/companies/oleg-bunin/articles/455652/
- Установка и настройка pytorch
https://timeweb.cloud/tutorials/python/ustanovka-i-nastrojka-pytorch
- Tokenization with the SentencePiece Python Library
https://www.geeksforgeeks.org/tokenization-with-the-sentencepiece-python-library
- OpenNMT Quickstart
https://opennmt.net/OpenNMT-py/quickstart.html
- Ctranslate2 Get started
https://opennmt.net/CTranslate2/
- Как создать переводчик, который переводит лучше, чем Google Translate
https://habr.com/ru/articles/689580/
- Гайд по работе языковых моделей для начинающих
https://habr.com/ru/companies/skillfactory/articles/837366/
- Объясняем простым языком, что такое трансформеры
https://habr.com/ru/companies/mws/articles/770202/
- Transformer Model from Scratch using TensorFlow
https://www.geeksforgeeks.org/transformer-model-from-scratch-using-tensorflow/
- Architecture and Working of Transformers in Deep Learning
https://www.geeksforgeeks.org/architecture-and-working-of-transformers-in-deep-learning/
- Transformer Attention Mechanism in NLP
https://www.geeksforgeeks.org/transformer-attention-mechanism-in-nlp/
- Transformers in Machine Learning
https://www.geeksforgeeks.org/getting-started-with-transformers