Большинство моделей ML обучаются независимо, без какого-либо взаимодействия друг с другом. Однако на практике, существует множество эффективных методов обучения, которые основаны на взаимодействии моделей в целях повышения производительности и обучаемости. На следующем рисунке представлены четыре хорошо адаптированные и часто используемые методики обучения:
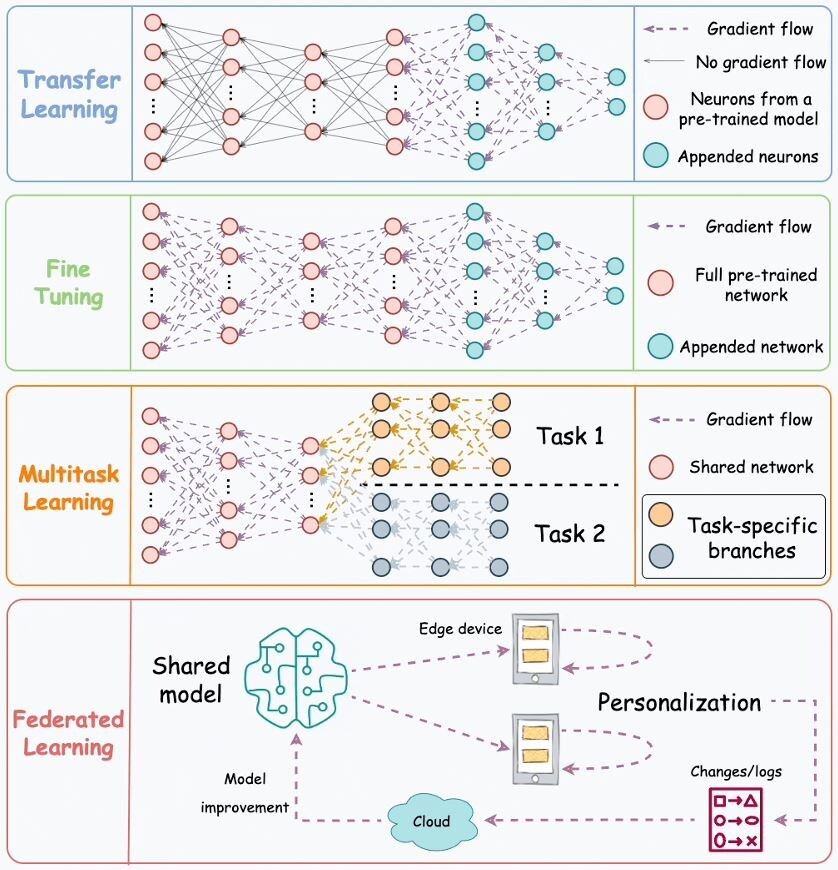
1. Transfer Learning
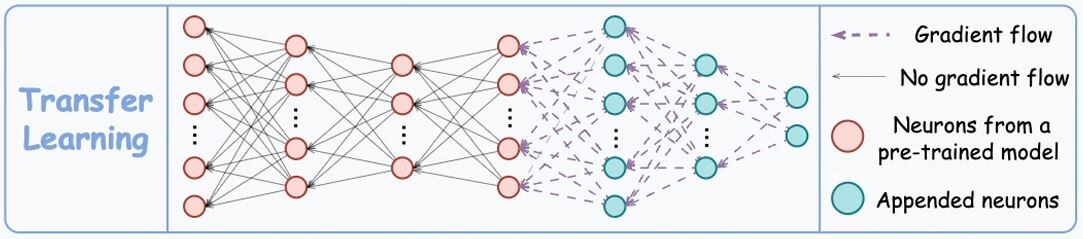
Такой метод обучения чрезвычайно полезен, когда:
- Задача, представляющая интерес содержит мало данных
- Но связанная с ней другая задача содержит данных гораздо больше
Вот как это работает:
- Сначала обучается базовая модель на связанной задаче, поскольку у неё больше данных, т.е. есть на чем обучать
- Далее меняются последние несколько слоев базовой модели новыми слоями (новые слои выделены голубым цветом)
- Модель с обновленными слоями обучается интересующей задаче, но веса базовой модели (выделена оранжевым цветом) не обновляются во время обратного распространения ошибки.
Обучая модель связанной задаче, сеть может уловить и запомнить основные закономерности интересующей задачи. Потом, изменяя последние несколько слоев, мы как бы формируем новые реакции, для обучения на данных уже интересующей нас задачи и распространяем их, только на измененный участок сети. Таким образом, знания об основных закономерностях интересующей нас задачи хранятся в базовой модели, а характерные признаки интересующей задачи, хранятся в измененной её части. Метод Transfer Learning обычно используется в задачах, связанных с компьютерным зрением.
Пример – необходимо научить сеть распознавать «Немецких овчарок» из всего многообразия собачьих пород. DataSet «Немецких овчарок» крайне небольшой, с другой стороны, мы имеем большой DataSet всех остальных пород. Общими признаками являются – 4 лапы, хвост, уши, глаза, шерсть и т.д., Характерными признаками являются – широкая грудь, хвост ниспадает дугой, голова клинообразной формы и т.д.
2. Fine-tuning
Метод Fine-tuning (точная настройка), включает в себя обновление весовых коэффициентов некоторых или всех слоев предварительно обученной модели, чтобы адаптировать ее к новой задаче. Идея может показаться похожей на Transfer Learning, но в методе Fine-tuning не производят замену нескольких последних слоев предварительно обученной модели. Вместо этого, предварительно обученная модель сама корректируется в соответствии с новыми данными. Данный метод используется, когда требуется дообучить уже предварительно обученную модель на более мелких специализированных DataSet с целью совершенствования их возможностей и повышения точности в конкретной задаче или предметной области.
3. Multi-Task Learning
Как следует из названия, данный метод предназначен для решения нескольких задач одновременно. Модель за счет своей архитектуры умеет распределять данные, стремясь улучшить итоговый результат (произвести «обобщение» результатов), а также затратить меньше вычислительных ресурсов на этапе обучения.
Такая модель помогает в сценариях, где существуют взаимосвязанные задачи, когда полезно обобщить результаты для улучшения точности и когда требуется сократить издержки на вычислительные ресурсы.
Выше представлен процесс обучения двум задачам:
- В первом варианте используется метод multi-task learning
- Во втором варианте (справа) классический подход, на основе построения двух независимых моделей
Первый вариант, как правило, приводит к следующему:
- Показывает лучшие результаты обучения по всем задачам за счет обобщения
- Экономит ресурсы памяти (меньшее количество весов)
- Экономит вычислительные ресурсы на этапе обучения
4. Federated Learning
Federated Learning относится к числу очень мощных методов ML, которым не уделяется должного внимания. Вот наглядный пример того, как это работает:
Современные устройства (например, смартфоны) имеют доступ к огромному количеству данных, которые могут быть использованы в моделях ML. Даже если говорить только об одном пользователе, то очевидно, что данных более чем достаточно - какие приложения запускает, что читает, как пишет, какой контент нравится, как часто фотографирует, количество активаций в день и т.д. Но если говорить о приложениях, то у них могут быть сотни тысяч и миллионы пользователей. Объем данных, на которых можно обучать модели ML, огромен. Так в чем же здесь проблема? Проблема в том, что почти все данные, доступные на современных устройствах, являются конфиденциальными – изображения, сообщения, голосовые звонки и заметки….
Поскольку данные являются приватными, их, вероятно, невозможно агрегировать на центральном сервере (традиционно модели ML всегда обучаются на централизованных наборах данных). Но эти данные по-прежнему ценны, и хотелось бы их как-то использовать.
Federated Learning эффективно решает проблему обучения моделей ML на частных данных. Вот так выглядит основная идея:
- Вместо агрегации данных на центральном сервере необходимо создать модель на конечном устройстве
- Обучить модель на основе личных данных пользователя на его же устройстве
- Отправить обученную модель обратно на центральный сервер
- Объединить все модели, полученные со всех конечных устройств, для формирования полной модели
Более того, Federated Learning производит большую часть вычислений на устройствах пользователей. В результате центральный сервер не нуждается в огромных вычислительных мощностях, которые часто являются краеугольным камнем крушения многих бизнес моделей.
В этом и состоит основная идея Federated Learning.