
Требования к железу.
В этой статье мы установим локально n8n + платформу Ollama которая позволит нам запускать ИИ модели локально и также встанет Qdrant это система управления векторными базами данных. Это позволит одной установкой закрыть все вопросы для начинающих энтузиастов n8n. Все это хозяйство сейчас в состоянии покоя кушает около 920Мб оперативной памяти. Моя тестовая машина, на которой это все крутиться, состоит из:
- Ryzen 7950х
- Kingston FURY Renegade Silver RGB DDR5, 16 ГБx2 шт, 6000 МГц, 32(CL)-38-38
- ASUS TUF GAMING X670E-PLUS WIFI
- Какой то M2 SSD диск )
Самое тяжелое, что я делал, и делаю постоянно это транскрибация разговора двух людей длительностью в час. Это грузит проц примерно на 30-40%. При загрузке в векторную базу данных с подключенной локальной Ollama Embedding файла Excel на 3256 строк тоже примерно 30%-40%. Так что, если будете что то серьезное ворочать, вот вам инфа для пристрела. Видеокарты у меня нет, все обрабатывается процессором. Как и в первой статье все будем лепить на Ubuntu 22.04.
Установка docker
Собственно для начала нам нужен сам docker
sudo apt update
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install docker-ce -y
sudo systemctl status docker
Если видим
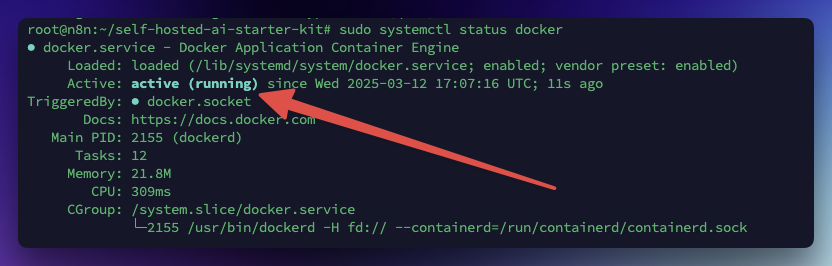
Значит все в порядке.
Далее ставим docker compose
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
Можно шагать дальше.
Self-hosted-ai-starter-kit
В этот раз будет немного полегче, ведь кто то заранее подумал и создал self-hosted-ai-starter-kit, которым мы и воспользуемся.
Идём на
И начинаем читать, особенно раздел Installation
Если у вас видеокарта NVidia то для установки используем:
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
docker compose --profile gpu-nvidia up
Если у вас видеокарта от AMD:
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
docker compose --profile gpu-amd up
С Mac версией маководы думаю разберутся ) и если вам нужна просто процессорная версия то ставим:
git clone https://github.com/n8n-io/self-hosted-ai-starter-kit.git
cd self-hosted-ai-starter-kit
docker compose --profile cpu up
Терпеливо ждем когда все скачается и установится.
Когда все остановится на
Установка закончена.
Набираем:
docker ps
Весь комплект установлен и готов к бою.
Если вдруг вы не планируете этот сервер публиковать в интернет, уже сейчас можно пройти по http://11.22.33.44:5678 (11.22.33.44 ip адрес сервера на который производилась установка) и увидите
n8n требует подключения по https что бы это обойти в конфиг нужно добавить строку
N8N_SECURE_COOKIE=false
Но ее нужно вставить не как прошлый раз в .env, а в файл docker-compose.yml который находится в папке
/root/self-hosted-ai-starter-kit
если вы ставили из под root. Если ставили под пользователем то
/home/vasya/self-hosted-ai-starter-kit
Где vasya это имя пользователя
Открываем
nano /root/self-hosted-ai-starter-kit/docker-compose.yml
Добавляем строку
После того как добавили, нажимаем CTRL+X, потом жмем Y, затем Enter
Перезапускаем docker. Команды эти нужно выполнять из папки где лежит файл docker-compose.yml
docker compose down && docker compose up -d
Теперь еще раз пробуем
http://11.22.33.44:5678
Все работает.
Nginx и доступ через https
Далее, делаем все через https. Я просто скопирую блок о том, как это делать из предыдущей статьи.
sudo apt install -y nginx
Создадим и активируем конфигурацию nginx для n8n
sudo nano /etc/nginx/sites-available/n8n
откроется редактор nano с пустым файлом, нужно в него вставить
server {
listen 80;
server_name n8n.chetko.ru;
location / {
proxy_pass http://localhost:5678;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket headers
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
}
server_name соответственно меняем на свой домен
После того как вставили, нажимаем CTRL+X, потом жмем Y, затем Enter
Это конфиг для прокси, который будет перенаправлять запросы с 80 порта на локально запущенный сервис n8n который работает на порту 5678.
Теперь включим нашу конфигурацию и перезапустим nginx
sudo ln -s /etc/nginx/sites-available/n8n /etc/nginx/sites-enabled/
sudo nginx -t
sudo systemctl restart nginx
Поставим Certbot что бы получить сертификат Let's Encrypt.
У некоторых провайдеров вместе с ubuntu ставиться firewall ufw, который будет блокировать проверку домену в момент выдачи сертификата. Что бы выяснить есть ли он, идем на Checkhost и делаем проверку
Если у вас 200 ОК то firewall не блокирует, если Connection Timeout, значит блокировка есть. Делаем
sudo ufw status
в ответ вы должны получить как минимум
Status: active
To Action From
-- ------ ----
22/tcp ALLOW Anywhere
22/tcp (v6) ALLOW Anywhere (v6)
Это минимальный набор правил что бы вы могли зайти на свой сервер по ssh. Добавим сюда разрешения к нужным нам портам командами
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
Теперь повторите проверку через check-host и должно быть по всем странам 200 ОК
Ставим Certbot и запрашиваем сертификат
sudo apt install certbot python3-certbot-nginx
sudo certbot --nginx -d n8n.chetкo.ru
Домен вместо n8n.chetкo.ru вставляем свой !
Вам зададут 3 вопроса, первый это email куда отправить уведомление для продления сертификата, вводим в ответ на первый вопрос свою электронную почту. Второй вопрос принимаете ли лицензионное соглашение, на него нужно ответить Y. Третий вопрос типа разрешить партнерам вас спамить на эту почту, можно ответить на третий вопрос N.
Если ваша А запись для домена сделала правильно, то certbot сам проверит ваш домен, запросит и получит сертификат и пропишет его в конфиг nginx.
На этом конфигурация n8n закончена.
Установка локальных моделей через Ollama
Теперь если вернемся к
docker ps
Мы видим что у нас есть контейнер ollama. Через него мы и будем устанавливать модели ИИ для локального использования.
Идём
И для пример выберем
https://ollama.com/library/nomic-embed-text
Копируем строку
И запускаем ее в контейнере ollama
docker exec -it ollama ollama pull nomic-embed-text
Модель nomic-embed-text скачается и установится. Теперь если вы будете загружать данные в векторную базу данных в n8n это модель будет доступна
Таким же образом вы можете скопировать установку любой модели с сайта ollama и установить ее через контейнер ollama.
Так же обратите внимание как настроен доступ к локальной ollama
Векторная база данных Qdrant
И последнее, вернемся к docker ps
Мы видим что Qdrant работает на порту 6333. Посмотрим что там.
Собственно это и есть dashboard локально запущенного Qdrant.
Можете в ней наблюдать свои загруженные Collections
Вот в принципе и все на сегодня. Надеюсь будет полезно.
P.S. Я не нашел в телеге группу русскоязычных энтузиастов n8n и создал свою, кто хочет разбираться и делиться опытом приглашаю: