
Технические спецификации и архитектурные особенности
Последние достижения в области обработки естественного языка представлены двумя ведущими моделями: GPT-4 от OpenAI и Llama 3.1 от Meta. Анализ их архитектур выявляет фундаментальные различия в подходах к разработке крупномасштабных языковых моделей.
GPT-4
GPT-4 продолжает эволюцию архитектуры Generative Pre-trained Transformer, начатую с GPT-1 (117 миллионов параметров), GPT-2 (1,5 миллиарда параметров) и GPT-3 (175 миллиардов параметров). Хотя OpenAI не раскрывает точное количество параметров GPT-4, аналитики оценивают его в диапазоне 1-1,5 триллиона. Модель фокусируется на масштабе и универсальности, что позволяет ей демонстрировать высокие результаты в широком спектре задач без специфической оптимизации.
Llama 3.1
Llama 3.1 представлена в трех вариантах:
- 8B (8 миллиардов параметров) - компактная версия для запуска на персональных устройствах
- 70B (70 миллиардов параметров) - среднемасштабная модель для производственного применения
- 405B (405 миллиардов параметров) - флагманская версия для промышленных решений
Ключевое преимущество Llama 3.1 - контекстное окно в 128 000 токенов, что существенно расширяет возможности модели по обработке длинных текстов. Для сравнения, стандартное контекстное окно GPT-4 составляет 8 192 токена, а максимальное - 32 768 токенов.
Вычислительные ресурсы и эффективность
Обучение Llama 3.1 потребовало задействования 16 000 видеокарт NVIDIA H100 на протяжении нескольких месяцев, что демонстрирует масштаб вычислительных ресурсов, необходимых для создания современных языковых моделей. Примечательно, что, несмотря на значительные инвестиции, Meta распространяет Llama 3.1 с открытым исходным кодом, что существенно отличает ее от закрытой модели GPT-4.
Сравнительные бенчмарки
Анализ производительности на стандартных бенчмарках выявляет сильные стороны обеих моделей:
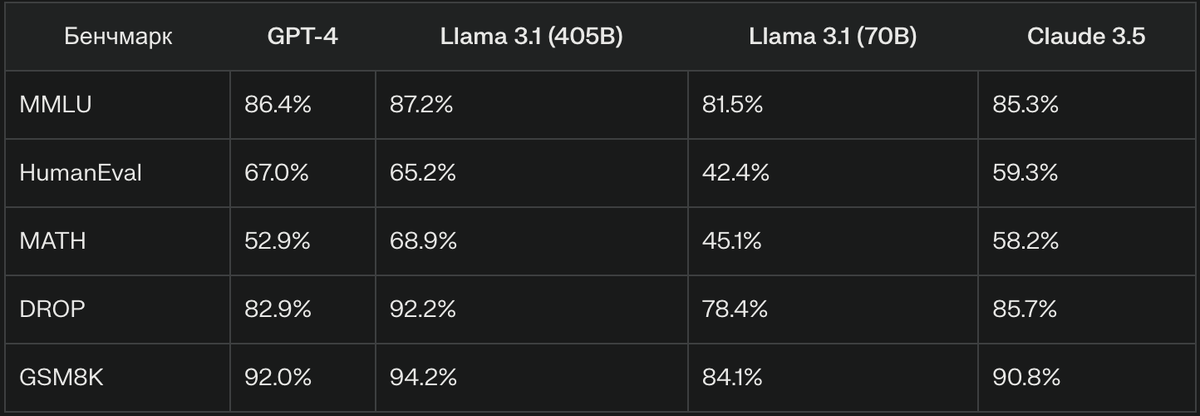
Llama 3.1 (405B) демонстрирует превосходство в задачах, требующих глубокого понимания контекста и рассуждений, таких как DROP (92.2% против 82.9% у GPT-4) и математические задачи MATH (68.9% против 52.9%).
Технологические различия в подходах к обучению
GPT-4 использует комбинацию предварительного обучения на масштабном корпусе текстов и дополнительной настройки с помощью RLHF (Reinforcement Learning from Human Feedback). Этот метод позволяет модели адаптироваться к человеческим предпочтениям и следовать заданным инструкциям.
Llama 3.1 также применяет RLHF, но с акцентом на эффективность вычислений. Meta реализовала обучение с использованием смешанной FP8-точности (подходит для задач, где точность может быть снижена в пользу максимальной скорости), что позволило значительно сократить требуемые вычислительные ресурсы при сохранении высокого качества результатов.
Практическое применение: задачи программирования
Анализ производительности в задачах программирования показывает интересные различия в подходах моделей, которые можно спроецировать на другие области применения:
Пример задачи: Функция для возведения списка чисел в квадрат
GPT-4:
Llama 3.1:
Llama 3.1 демонстрирует тенденцию к использованию более компактных и идиоматических конструкций Python, в то время как GPT-4 предпочитает более явный и структурированный подход. И это отражается на разных сферах применения моделей - Llama стремиться к эффективному использованию ресурсов, оптимизируя подходы, GPT - не экономит ресурсы, создавая более явные композиции.
Ограничения и вызовы
Несмотря на впечатляющие результаты, обе модели имеют характерные ограничения:
Llama 3.1:
- Иногда демонстрирует затруднения с задачами, требующими здравого смысла
- Может некорректно обрабатывать идиоматические выражения
- Имеет тенденцию к буквальной интерпретации запросов
GPT-4:
- Может проявлять избыточную уверенность в неточных ответах
- Иногда испытывает трудности с узкоспециализированными знаниями
- Показывает переменные результаты при многоступенчатых рассуждениях
Экономическая эффективность и доступность
Открытый характер Llama 3.1 предоставляет значительные экономические преимущества для разработчиков и организаций. Возможность локального запуска и модификации модели существенно снижает операционные затраты по сравнению с использованием API GPT-4, где стоимость обработки варьируется от $0.01 до $0.06 за 1000 токенов.
Сравнительный анализ GPT-4 и Llama 3.1 выявляет различные подходы к разработке крупномасштабных языковых моделей. GPT-4 продолжает делать ставку на масштаб и универсальность, в то время как Llama 3.1 фокусируется на эффективности и открытости.
Llama 3.1 (405B) демонстрирует превосходство в ряде ключевых бенчмарков, особенно в задачах, требующих глубокого понимания контекста и математических рассуждений. Открытый исходный код и значительное контекстное окно (128 000 токенов) обеспечивают дополнительные преимущества для специализированных применений.
Выбор между этими моделями должен определяться конкретными требованиями задачи, доступными вычислительными ресурсами и экономическими факторами. Llama 3.1 предоставляет более гибкие возможности для локального развертывания и модификации, в то время как GPT-4 обеспечивает более унифицированный доступ через API с минимальными требованиями к инфраструктуре.