В последние дни февраля 2025 года компания DeepSeek опубликовала подробное описание своей инфраструктуры для обслуживания запросов к моделям DeepSeek-V3 и DeepSeek-R1. Этот документ раскрывает технические решения, позволяющие эффективно запускать крупные разреженные модели и достигать впечатляющей производительности. Рассмотрим ключевые аспекты этой системы простым языком.

Основные принципы проектирования: скорость и экономия
Главная цель системы инференса DeepSeek — обеспечить две ключевые характеристики:
- Высокую пропускную способность (обработать больше запросов)
- Низкую задержку (быстрее отвечать на каждый запрос)
Для достижения этих целей инженеры DeepSeek применили специальную технологию — экспертный параллелизм между узлами (cross-node Expert Parallelism, EP). Эта технология решает две задачи:
- Увеличивает размер батча (группы обрабатываемых запросов), что позволяет GPU эффективнее выполнять матричные вычисления
- Распределяет экспертов (специализированные нейронные подсети) между разными GPU, так что каждый графический процессор обрабатывает лишь небольшое подмножество всех экспертов
В моделях DeepSeek используется архитектура MoE (Mixture of Experts), где из 256 экспертов в каждом слое активируются только 8. Такая высокая разреженность модели требует особого подхода к организации вычислений.
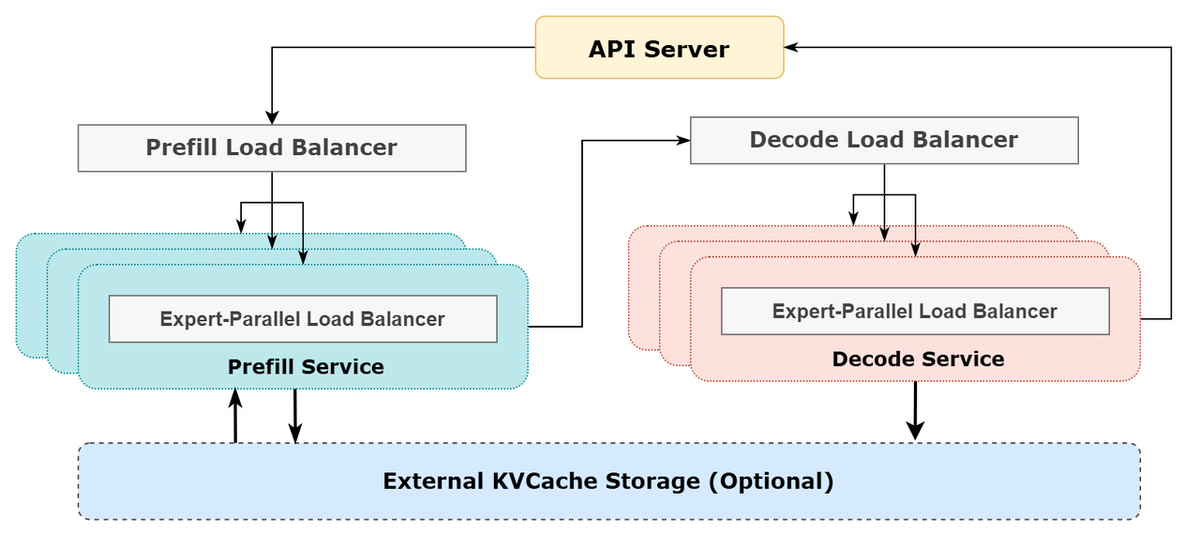
Двухфазная архитектура обработки запросов
DeepSeek разделяет обработку запросов на две фазы, для каждой из которых используется своя конфигурация:
- Фаза prefill (предварительной обработки) — когда модель обрабатывает входной текст пользователя:
Задействует 4 вычислительных узла
Использует параллелизм EP32 для маршрутизируемых экспертов
Каждый GPU обрабатывает 9 маршрутизируемых экспертов и 1 общий эксперт - Фаза decode (генерации ответа) — когда модель создает новые токены ответа:
Задействует 18 вычислительных узлов
Использует параллелизм EP144 для маршрутизируемых экспертов
Каждый GPU обрабатывает всего 2 маршрутизируемых эксперта и 1 общий эксперт
Такое разделение позволяет оптимизировать ресурсы для разных типов вычислений, выполняемых на этих фазах.
Оптимизация коммуникаций между узлами
Использование экспертного параллелизма приводит к необходимости обмена данными между узлами, что может создавать задержки. Для решения этой проблемы DeepSeek применяет специальные техники:
- Стратегия двойного батча — запросы разделяются на две микрогруппы, которые обрабатываются поочередно. Пока идет вычисление для одной группы, для другой происходит коммуникация между узлами.
- Пятиэтапный конвейер для фазы decode — операции внимания (attention) разбиваются на несколько шагов, что позволяет перекрывать коммуникации и вычисления.
Эти методы помогают "спрятать" задержки коммуникации за вычислениями, тем самым увеличивая общую производительность системы.
Система балансировки нагрузки
Когда задействовано множество GPU, критически важно, чтобы все они были загружены равномерно. Иначе один перегруженный GPU может стать узким местом, замедляющим всю систему. DeepSeek использует три балансировщика нагрузки:
- Балансировщик prefill:
Равномерно распределяет вычисления внимания между GPU
Выравнивает количество входных токенов на каждом GPU - Балансировщик decode:
Балансирует использование KVCache (памяти для ключей и значений) между GPU
Выравнивает количество запросов на каждом GPU - Экспертный балансировщик:
Распределяет экспертов так, чтобы минимизировать максимальную нагрузку на любой из GPU
Анализ эффективности и экономических показателей
DeepSeek предоставил интересную статистику за 24 часа работы (с 12:00 27 февраля до 12:00 28 февраля 2025 года по UTC+8):
- Использование ресурсов:
Пиковое количество узлов: 278 (каждый с 8 GPU H800)
Среднее количество узлов: 226,75
Суточные затраты: $87,072 (при стоимости $2 за час работы одного GPU H800) - Производительность:
Обработано 608 миллиардов входных токенов
56,3% (342 миллиарда) токенов извлечены из кэша
Сгенерировано 168 миллиардов выходных токенов
Средняя скорость генерации: 20-22 токена в секунду
Средняя длина KV-кэша на выходной токен: 4989 токенов
Пропускная способность одного узла H800: около 73,7 тысяч входных токенов в секунду или 14,8 тысяч выходных токенов в секунду - Экономические показатели:
Теоретическая выручка при тарифах DeepSeek-R1: $562,027
Теоретическая рентабельность: 545%
Фактическая выручка ниже из-за:
Более низких тарифов DeepSeek-V3
Бесплатного доступа к части сервисов через веб и мобильное приложение
Ночных скидок в периоды низкой нагрузки
Интересно, что DeepSeek динамически распределяет ресурсы, увеличивая количество задействованных узлов в периоды пиковой нагрузки и снижая их ночью, когда активность пользователей падает. Освободившиеся ночью ресурсы перенаправляются на исследования и обучение моделей.
Система инференса DeepSeek-V3/R1 демонстрирует современный подход к обслуживанию крупных языковых моделей. Ключевые принципы — распределенные вычисления, специализация узлов и тщательная балансировка нагрузки — позволяют компании эффективно использовать дорогостоящее оборудование и обеспечивать высокую пропускную способность при относительно низкой задержке ответов.
Особенно примечательна экономическая эффективность: даже с учетом всех скидок и бесплатных сервисов, система генерирует значительную прибыль, что делает бизнес-модель DeepSeek устойчивой в долгосрочной перспективе. Это важный аспект, учитывая высокие капитальные и операционные затраты, связанные с запуском современных нейронных сетей.