
Введение
Что, если бы языковые модели могли мыслить более по-человечески? Вместо того чтобы генерировать текст по одному слову, что, если бы они сначала набрасывали идеи, а затем постепенно их дорабатывали?
Именно это предлагает Large Language Diffusion Models (LLaDA) — новый подход к генерации текста, отличный от традиционных авторегрессивных моделей (ARMs). Вместо последовательного предсказания токенов слева направо LLaDA использует процесс, похожий на диффузию, чтобы создавать текст. Модель постепенно улучшает замаскированный текст, пока не сформирует связный ответ.
В этой статье мы разберем, как работает LLaDA, почему это важно и как она может повлиять на эволюцию LLM.
Надеюсь, вам понравится!
Текущее состояние LLM
Чтобы понять инновационность LLaDA, сначала нужно разобраться в работе современных языковых моделей. Современные LLM следуют двухэтапному процессу обучения:
- Предобучение: Модель изучает общие языковые паттерны, предсказывая следующий токен в огромных текстовых датасетах через самообучение.
- Контролируемая донастройка (SFT): Модель улучшается на тщательно отобранных данных, чтобы лучше следовать инструкциям и генерировать полезные ответы.
Примечание: Современные LLM часто используют RLHF для дальнейшей настройки, но LLaDA этот этап не применяет, поэтому мы его опустим.
Эти модели, основанные на архитектуре Transformer, генерируют текст по одному токену через предсказание следующего токена.
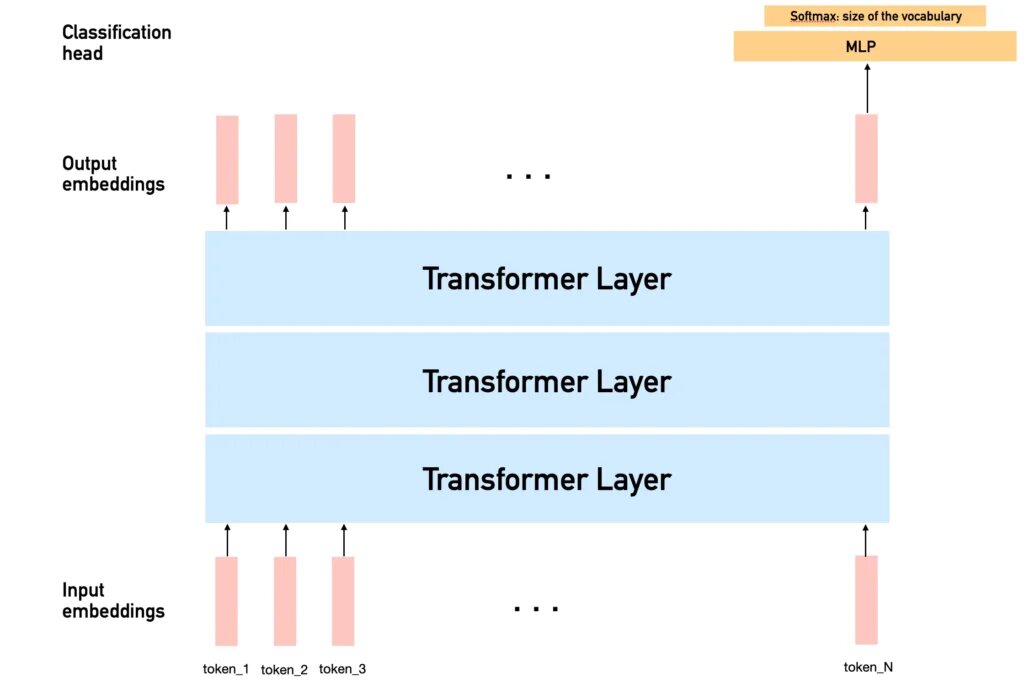
В текущих LLM (LLaMA, ChatGPT, DeepSeek и др.) классификационная головка используется только для последнего токена, чтобы предсказать следующий. Это работает благодаря маскированному self-attention: каждый токен учитывает только предыдущие. Позже мы увидим, как LLaDA убирает маскирование в слоях внимания.
Ограничения современных LLM
Текущие LLM сталкиваются с несколькими проблемами:
- Вычислительная неэффективность
LLM обрабатывают всю предыдущую последовательность для генерации каждого нового токена. Даже с оптимизациями вроде KV-кэширования это требует больших ресурсов. - Одностороннее мышление
ARMs не могут анализировать текст в обратном направлении или пересматривать уже сгенерированное. Они предсказывают будущие токены только на основе прошлых. - Объем данных
Для обучения требуются огромные датасеты, что ограничивает их применение в узких областях с малым количеством данных.
Что такое LLaDA
LLaDA заменяет авторегрессию диффузионным процессом. Разберем этапы:
Предобучение LLaDA
- Фиксируется максимальная длина последовательности (например, 4096 токенов).
- Выбирается случайная маскирующая ставка (например, 40%).
- Каждый токен маскируется с вероятностью 0.4 (заменяется на <MASK>).
- Последовательность подается в модель, которая предсказывает маскированные токены.
- Функция потерь — среднее кросс-энтропии по всем маскированным токенам:
SFT в LLaDA
Как и в ARMs, используется пара (промпт, ответ). Маскируются токены ответа, модель учится их восстанавливать.
Инференс: инновационный подход
Генерация в LLaDA — это постепенное демаскирование:
- На вход подается промпт и замаскированный ответ.
- Модель предсказывает маскированные токены.
- На каждом шаге часть токенов с наивысшей уверенностью сохраняется, остальные маскируются снова.
- Процесс повторяется до полного демаскирования.
Практика: Маскируется все меньше токенов с каждым шагом (например, от 100% до 0%).
Комбинация авторегрессии и диффузии
Идея полуавторегрессивной диффузии:
- Генерация разбивается на блоки (например, по 32 токена).
- Для каждого блока применяется диффузионный процесс.
- После генерации блока модель переходит к следующему.
Результаты
- Эффективность обучения: LLaDA 8B показывает результаты, сопоставимые с LLaMA3, используя в 6 раз меньше токенов (2.3T против 15T).
- Гибкость: Блоки разной длины улучшают результаты в задачах вроде математики.
- Обратная генерация: LLaDA лучше справляется с задачами вроде написания стихов в обратном порядке.
Заключение
LLaDA предлагает:
- Параллельную генерацию токенов.
- Более эффективное обучение.
- Гибкость для разных задач.
Этот подход может стать шагом к более «естественным» языковым моделям. Хотя технология еще молода, диффузионные методы открывают новые горизонты для ИИ.
Спасибо за чтение!