Настоящий мужик должен родить сына, запрограммировать дерево и построить raid.
зы И пожать сотку.
Приветствую тебя авантюрист! Сегодня мы обсудим довольно важную и не простую тему — организацию файловых хранилищ. Каждый системный администратор и IT-специалист рано или поздно сталкивается с необходимостью изучения более сложных методов и систем для работы с дисками и создания разнообразных схем хранения данных. Использование многодисковых систем и файловых систем, отличных от стандартных NTFS, открывает множество возможностей: скорость, отказоустойчивость, гибкость, экономию места и многое другое. Мы рассмотрим одно из довольно мощных и бесплатных решений — ZFS.
Структура материала
Материал будет разбит на 4 статьи:
- Здесь мы рассмотрим создание, удаление, экспорт, импорт, перенос «хранилища» на другие ПК. Разберем несколько кейсов. (Ты читаешь эту статью в данный момент)
- В третьей статье мы поговорим о надежности. Как восстанавливать, заменять поврежденные диски. Рассмотрим пару реальных кейсов.
- Рассмотрим снапшоты, клоны и реплики. Опять же с примерами.
Необходимый уровень знаний
Уверенное знание и понимание работы носителей данных в операционных системах Linux. Уверенное знание и понимание, как работают файловые системы, что это такое и для чего. Базовые знания и умения работы с RAID-массивами.
ZFS базовая терминология
Физические устройства — это физические носители или их разделы (partition), которые можно видеть в команде lsblk. Всё, что там есть, может быть использовано в ZFS.
Виртуальные устройства, или VDEV, или virtual device — это абстракция, которая объединяет в себе физические устройства по определенным правилам. В ZFS это:
- RAID0 (slice или последовательное объединение)
- MIRROR (RAID1)
- RAIDZ
Виртуальные устройства можно ставить друг за дружкой в виртуальной иерархии, а также объединять некоторые типы устройств.
ZFS пул, или ZFS pool, или массив данных— совокупность одного или более виртуальных устройств.
Датасет (dataset) — это последний уровень абстракции ZFS, которые создаются непосредственно в пуле. Датасеты это файловые системы, колны и снапшоты. Иногда датасетами называют непосредственно файловые системы.
Файловая система. Внутри пула ты можешь создавать сколько угодно файловых систем. Для каждой отдельной файловой системы можно прописывать свои настройки и свои точки монтирования. Также клоны и снапшоты применяются именно к конкретной файловой системе.
Про снапшоты и колны я буду говорить в следующих статьях, но тем не менее
Снапшот или snapshot — это мгновенный снимок файловой системы, к которому можно откатиться в любое время.
Клон или clone — это датасет на основе снапшота. Ты можешь смонтировать клон файловой системы с возможностью как чтения, так и записи. При этом физическое место на диске будет занимать только разница в данных.
Давай попробую привести конкретный пример с описанием, что есть что. Предположим, у тебя есть 2 жестких диска, они определяются как /dev/sdb и /dev/sdc. Это будут физические устройства. Я хочу сделать из них зеркалирующее хранилище. То есть RAID1. В терминологии ZFS это MIRROR, следовательно, это будет виртуальное устройство типа MIRROR из двух физических устройств. На основе этого виртуального устройства я строю пул. И уже на этом пуле я могу создать файловые системы, делать снапшоты и клоны. К слову, первая файловая система всегда создается при создании пула автоматически, и в большинстве случаев тебе этого хватит.
Установка ZFS
Все примеры, приведенные в статье, я буду проделывать на Alt Linux. Следовательно, установку я приведу именно для этой системы. Если у тебя другая система, придется поискать информацию в сети.
Первым делом поставим свежее ядро
update-kernel
Далее ставим саму ZFS
apt-get install zfs-utils
Теперь установим модуль zfs. Здесь нужно подставить модуль для конкретно твоего ядра, в моем случае ядро 6.6.78, значит, я ставлю модуль командой.
apt-get install kernel-modules-zfs-6.6.78-6.6-alt1
Теперь нужно загрузить модуль zfs
modprobe zfs
Проверяем
Отлично. Наша ZFS установлена и готова к работе.
Команды мониторинга
В твоем распоряжении 3 основных команды: zpool, zfs и zdb. Первая команда для работы с пулами, вторая — для работы с датасетами, и третья, более специфическая, позволяет получить низкоуровневые и вспомогательные данные.
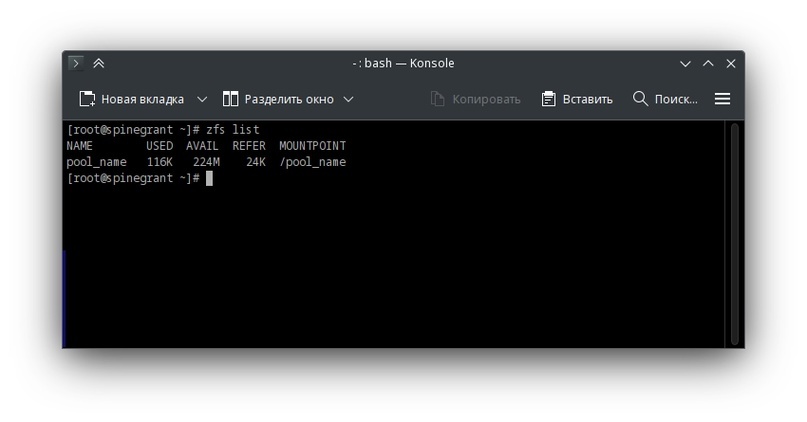
zfs list — список датасетов. Можем увидеть название датасета, используемое и доступное пространство для данных. Также видим точку монтирования. Столбец REFER не имею понятия, для чего.
zpool list — список пулов. Видим название, размер, реально используемые физическое пространство, свободное место, далее 2 неизвестных мне параметра, затем процент фрагментации, процент использования, коэффициент дедупликации и статус здоровья.
zpool status — статус здоровья пулов. Здесь видно, в каком состоянии пул и виртуальные устройства, из которых он состоит. Есть ли ошибки чтения, записи или контрольной суммы, и на каком физическом диске они есть.
zpool iostat -v 1 — выводит статистику загрузки устройств пула в текущий момент.
zdb — это своего рода отладчик, который необходим не всегда. Через него можно получить огромное количество информации. Сама по себе команда выводит подробную информацию о пулах. Но можно получать выборочные данные.
В целом всё. Этих команд более чем достаточно для полноценного мониторинга работы файлового хранилища.
Здесь я не включил команды мониторинга снапшотов и клонов. О них будет в соответствующей статье.
Експорт импорт пулов
Импорт и экспорт в ZFS можно смело заменить словами «отключение» и «подключение». Именно командой zpool export ты отключаешь пул от работы. И это именно правильный способ. Все другие варианты приведут к потерям данных и длительным процедурам восстановления. Командой zpool import, наоборот, подключаем пул в работу. Следовательно, когда ты завершил работу с пулом и нужно его физически отключить, ты вводишь команду.
zpool export имя_пула
После чего можно физический отключать накопители. Если нужен доступ к пулу вновь, ты подключаешь физические устройства и вводишь команду
zpool import имя_пула
Пул будет подключен и сразу начнет работу. Если имя пула неизвестно, можно ввести zpool import без имени пула. Тогда команда выведет ВСЕ доступные для импорта пулы.
Кстати командой импорт мы можем переименовать пул.
zpool import старое_имя_пула новое_имя_пула
Пул при этом должен быть отключен(экспортирован).
Также здесь стоит сказать, что физические носители ты можешь подключать в любом порядке. ZFS считает служебную информацию с диска и определит, к какому пулу он принадлежит, независимо от того, в какой порт этот диск был подключен ранее.
Создание пула
Приступаем к практике создания хранилища. Для демонстрации работы я взял флешку и создал на ней 3 раздела: 100 МБ, 100 МБ и 200 МБ соответственно. Я думаю, понятно, что в качестве физических устройств может выступать всё что угодно. Я использую флешку для простоты. Итак.
/dev/sdc — это наша флешка. Как видишь, там 3 раздела. Начнем с простейшего пула, состоящего из 1 виртуального устройства типа RAID0.
zpool create pool_name -f /dev/sdc1 /dev/sdc2 /dev/sdc3
Ключ -f необходим, чтобы zfs перезаписала всё, что есть на дисках, иначе она может поругаться на наличие там данных.
Создан пул с именем pool_name. Как и положено RAID0, общий объем массива равен сумме всех дисков. В данном случае чуть меньше, видимо, ZFS что-то забирает под свои нужды. При потере одного из дисков ты потеряешь полностью все данные без возможности восстановления.
Команда zpool list показывает, что массив действительно создан. Автоматически создалась файловая система. Видим точку монтирования файловой системы. Ее (точку монтирования) можно изменить в любое время, если это нужно. Давай еще посмотрим статус нашего пула командой zpool status.
Все online, все в порядке.
Теперь давай сделаем пул на основе другого виртуального устройства — MIRROR или RAID1. Для этого используем команду
zpool create pool_name mirror /dev/sdc1 /dev/sdc2
Будет создан пул с именем pool_name из 1 виртуального устройства типа MIRROR, которое состоит из двух физических устройств /dev/sdc1 и /dev/sdc2.
Данные будут дублироваться на оба устройства, тем самым выход одного из дисков не приведет к потере данных. Но общий размер виртуального устройства равен размеру наименьшего из физических устройств, из которых оно состоит. В виртуальное устройство типа MIRROR можно засунуть сколько угодно физических устройств. На всех будет происходить дублирование данных.
Аналогичным образом можно создать пулы на виртуальных устройствах типа RAIDZ. Данный тип может быть трех видов: raidz1, raidz2 и raidz3. Первый тип — минимум 3 диска, и 1 диск может выйти из строя без потери данных, второй — минимум 4 диска, и 2 диска могут выйти из строя, и третий — минимум 5 дисков, и 3 диска могут выйти из строя соответственно. Давай создадим, например, raidz1.
zpool create pool_name raidz1 /dev/sdc1 /dev/sdc2 /dev/sdc3
Отлично.Это довольно надежное хранилище из трех дисков. При выходе из строя 1 диска массив продолжит прекрасно работать. Конечно же, испорченный диск нужно будет заменить как можно скорее. Обрати внимание, что мы использовали диски разного размера, а значит, ВСЕ диски будут выровнены под размер наименьшего.
Общий размер примерно 300 МБ минус информация для восстановления. То есть от третьего диска, который был 200 МБ, ZFS взяла для использования 100 МБ. А это значит, что как для MIRROR, так и для RAIDZ диски желательно, но необязательно подбирать одинакового размера.
А ведь тебе ничего не мешает сделать несколько виртуальных устройств. К примеру, у нас есть два диска по 100 МБ и 2 по 200 МБ. Делать из них RAIDZ расточительно, объединить всё в одно зеркало — бред. Но мы можем сделать 2 последовательных зеркала, сделав что-то похожее на RAID10. То есть первые два диска по 100 МБ — это будет первое зеркало, вторые диски по 200 МБ — это будет второе зеркало. И всё это будет в одном пуле последовательно. Попробуем это сделать.
Итак вот 4 раздела на нашей флешке, теперь пишем
zpool create pool_name -f mirror /dev/sdc1 /dev/sdc2 mirror /dev/sdc3 /dev/sdc4
Готово. Все 4 диска задействованы, всё надёжно и красиво. Таких пар можно делать сколько угодно. Можно взять и 6, и 10, и 20 дисков разных размеров.
Удаление пула
zpool destroy pool_name
Идем дальше
Создание файловых систем
При создании пула автоматически создается корневая файловая система, но ты можешь создать их сколько угодно. Делается это командой.
zfs create pool_name/new_file_system
Где pool_name — это имя пула, на котором создаем файловую систему, ну а new_file_system — название файловой системы. На изображении ниже ты видишь, что для новой файловой системы был создан каталог — это точка монтирования вновь созданной файловой системы. Большого смысла в создании отдельных файловых систем нет, пока ты не начнешь пользоваться снапшотами. Но в ZFS есть настройки, которые как раз таки применяются к файловой системе. Например, можно создать одну файловую систему с сжатием данных на лету, а другую — без сжатия.
Удаление файловых систем
Точно так же, как с пулами.
zfs destroy pool_name/new_file_system
Настройки файловых систем
К файловым системам можно и нужно применять настройки. Для того чтобы увидеть текущие настройки файловой системы, используй команду.
zfs get dedup pool_name
В данном примере получаем значение настройки dedup для корневой файловой системы pool_name.
Данный параметр отвечает за дедубликацию, и, как видно, она в данный момент отключена. Для того чтобы увидеть все возможные настройки, достаточно ввести эту команду без указания файловой системы.
zfs get
Ну и чтобы изменить параметр, воспользуйся командой
zfs set dedup=on pool_name
Параметров настройки довольно много, перечислю основные, на мой взгляд.
dedup — включить дедубликацию. То есть, если в файловой системе есть 2 или более абсолютно одинаковых файла, физическое место будет занимать только первый, все остальные будут ссылаться на первый.
compress — сжатие «налету». Работает неплохо, самое адекватное значение, на мой взгляд- lz4.
mountpoint — точка монтирования файловой системы. Собственно, каталог, в который монтируется файловая система.
acltype — включить поддержку контроля доступа ACL. Необходимо установить значение posixacl.
Итог
Получилось довольно много информации, но ее действительно много, и что-то вырезать проблематично. Я попытался передать свой опыт максимально сжато и удобно. Надеюсь, у меня получилось. Еще не написал про добавление новых физических устройств и удаление их же из пулов. Но это вполне логично пойдет в следующую статью про восстановление данных. Еще больше нагружать текущую статью не стал. Да и есть там нюансы, которые хорошо бы как следует загуглить.