
Дебаты вокруг AI-бенчмарков — и того, как AI-компании представляют свои результаты — выходят в публичное пространство.
На этой неделе сотрудник OpenAI обвинил компанию Илона Маска, xAI, в публикации вводящих в заблуждение о результатах тестирования новой AI-модели Grok 3. Сооснователь xAI Игорь Бабушкин настаивает, что компания всё сделала правильно.
Переведено, но не озвучено командой LearnMore.tech с сайта https://techcrunch.com/
Правда, как водится, где-то посередине
В своём блоге xAI опубликовала график с результатами тестирования Grok 3 на AIME 2025 — наборе сложных математических задач из недавнего экзамена по математике. Некоторые эксперты ставят под сомнение AIME как объективный бенчмарк для AI, однако этот тест и его предыдущие версии часто используют для проверки математических способностей моделей.
На графике xAI показано, что две версии Grok 3 — Grok 3 Reasoning Beta и Grok 3 mini Reasoning — обошли лучшую доступную модель OpenAI, o3-mini-high, на AIME 2025. Однако сотрудники OpenAI в соцсети X (бывший Twitter) быстро указали, что в этом графике не учтён показатель o3-mini-high при “cons@64”.
Что такое cons@64?
Это сокращение от "consensus@64", метода, который даёт модели 64 попытки ответить на каждую задачу и фиксирует тот ответ, который встречается чаще всего. Логично, что cons@64 значительно повышает итоговые оценки моделей, а если этот показатель не учитывать, может показаться, что одна модель превосходит другую, хотя на самом деле это не так.
Если рассматривать показатели Grok 3 Reasoning Beta и Grok 3 mini Reasoning на AIME 2025 без многократных попыток — то есть "@1" (первая же попытка модели) — они оказываются ниже результата o3-mini-high. Более того, Grok 3 Reasoning Beta лишь незначительно уступает модели OpenAI o1 с настройкой "medium" по вычислительным ресурсам. Однако xAI всё равно рекламирует Grok 3 как "самый умный AI в мире".
Бабушкин возразил в X, что OpenAI тоже публиковала графики с потенциально вводящими в заблуждение сравнениями, хотя речь шла о сравнении их собственных моделей между собой. В свою очередь, более нейтральная сторона спора составила более точный график, где учтены почти все модели на cons@64.
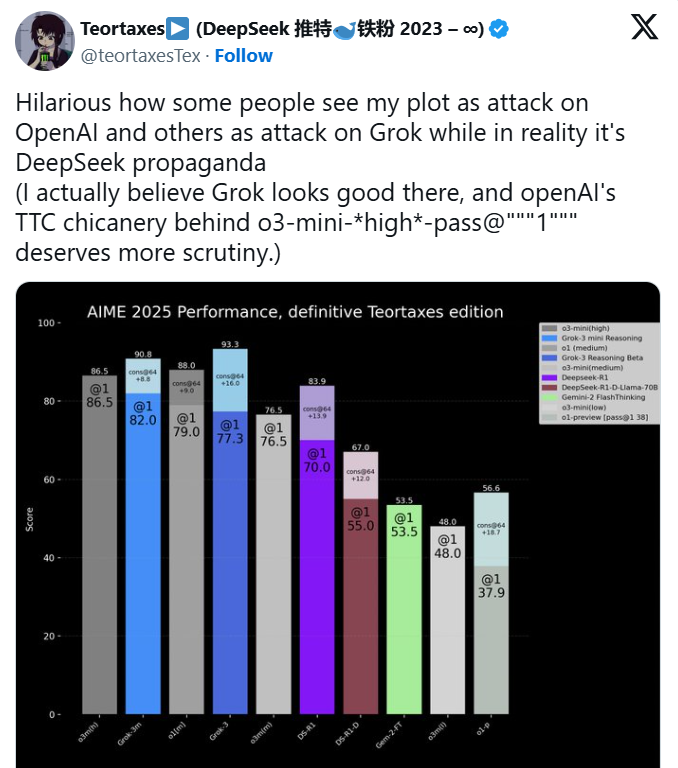
Но, как заметил исследователь AI Натан Ламберт, возможно, самый важный показатель остаётся неизвестным: сколько вычислительных (и денежных) ресурсов потребовалось каждой модели, чтобы добиться своего лучшего результата. Этот факт лишь подтверждает, насколько ограниченно AI-бенчмарки отражают реальные возможности и слабости моделей.
От редакции LearnMore:
Для всех, кого интересуют нейросети для абсолютно разных задач, мы предлагаем пройти наш курс "ИИ для работы: как решать задачи быстрее и эффективнее". Экономьте до 100 ч/мес, делегируя рутину нейросетям :)