
Redis (акроним из трех английских слов remote dictionary server) — резидентная система управления базами данных (СУБД), относящаяся к классу NoSQL, работающая со структурами данных типа «ключ — значение». База данных хранится в оперативной памяти и снабжена механизмами снимков и журналирования для обеспечения возможности хранения на дисках и твердотельных накопителях. Кроме того, Redis предоставляет операции для реализации механизма обмена сообщениями.
NoSQL (от англ. not only SQL — не только SQL) — обозначение широкого класса СУБД, появившихся в конце 2000-х — начале 2010-х годов и существенно отличающихся от традиционных реляционных СУБД.
Традиционные СУБД ориентируются на требования ACID к транзакционной системе: атомарность (atomicity), согласованность (consistency), изолированность (isolation) и долговечность (durability). В NoSQL вместо ACID может рассматриваться набор свойств BASE:
- базовая доступность (basic availability) — каждый запрос гарантированно завершается (успешно или безуспешно);
- гибкое состояние (soft state) — состояние системы может изменяться со временем, даже без ввода новых данных, для достижения согласования данных;
- согласованность в конечном счёте (eventual consistency) — данные могут быть некоторое время рассогласованы, но приходят к согласованию через некоторое время.
Решения NoSQL отличаются не только проектированием с учётом масштабирования. Другими характерными чертами NoSQL-решений являются:
- Применение различных типов хранилищ;
- Линейная масштабируемость (добавление вычислительных мощностей увеличивает производительность).
В зависимости от модели данных и подходов к распределённости данных в NoSQL выделяются четыре основных типа систем: «ключ — значение» (key-value store), «семейство столбцов» (column-family store), документ ориентированные (document store) и графовые.
Модель «ключ — значение» является простейшим вариантом, использующим ключ для доступа к значению. Такие системы используются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов. Такая модель незаменима в системах, спроектированных с прицелом на высокую нагрузку и масштабируемость. К такой модели относится Redis.
Другой тип систем — «семейство столбцов». Прародитель этого типа — система Google BigTable. В таких системах данные хранятся в виде разреженной матрицы, строки и столбцы которой используются как ключи. Типичным применением этого типа СУБД является веб-индексирование, а также задачи, связанные с большими данными, с пониженными требованиями к согласованности. Примерами СУБД данного типа являются: Apache HBase, Apache Cassandra, ScyllaDB и другие.
Системы типа «семейство столбцов» также как и документно-ориентированные имеют схожие сценарии использования. В том числе системы управления контентом, блоги, регистрация событий. Использование временных меток позволяет использовать этот вид систем для организации счётчиков, а также регистрации и обработки различных данных, связанных со временем.
Документоориентированные СУБД служат для хранения иерархических структур данных. Находят своё применение в системах управления контентом, издательском деле, документном поиске. Примеры СУБД данного типа — CouchDB, Couchbase, MongoDB.
Графовые СУБД применяются для задач, в которых данные имеют большое количество связей, например, социальные сети. Примерами таких СУБД служат: Neo4j, OrientDB, AllegroGraph. Так как рёбра графа являются хранимыми, обход графа не требует дополнительных вычислений (как соединение в SQL), но для нахождения начальной вершины обхода требуется наличие индексов. Графовые СУБД как правило поддерживают ACID, а также поддерживают специализированные языки запросов, такие как GraphQL.
Вернемся к рассмотрению Redis. Можно сказать, что Redis является сервером структур данных. В его основе лежит следующая идея. Вместо того чтобы работать со строками базы данных, перебирать, сортировать, упорядочивать их, информация будет храниться не в таблицах, а в структурах данных, которыми оперирует программа. Redis поддерживает следующие типы данных:
- Строка (String)
- Хеш-таблица (Hash)
- Список (List)
- Множество (Set)
- Упорядоченное множество (Sorted set)
- Гео пространственные данные (Geospatial)
- HyperLogLog
- Поток (Stream)
- Битовый массив (Bitmap)
В данной статье рассмотрим первые пять типов, так как они чаще всего используются при разработке. Для работы с Redis можно непосредственно установить его на своем ПК либо использовать готовый Docker образ из репозитория. В данной статье рассмотрим первый способ. Для установки Redis в Ubuntu можно использовать следующую команду:
sudo apt install redis-server
Как всегда, при работе с любым вновь установленным программным обеспечением, рекомендуется убедиться, что Redis работает как положено. Рассмотрим способы проверки корректной работы Redis.
Начнем с проверки того, что служба Redis запущена, введя следующую команду: sudo systemctl status redis
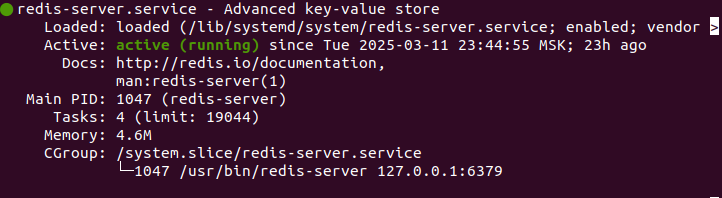
Видно что Redis установлен и активен. Кроме того указан ip-адрес 127.0.0.1 на котором работает сервер и порт 6379.
Чтобы проверить правильность работы Redis, подключитесь к серверу, введя команду redis-cli. В ответ запустится консольный клиент и покажет приглашение к вводу команд в формате 127.0.0.1: 6379>. Далее рекомендуется проверить подключение с помощью команды ping. В ответ должен вернуться ответ PONG. Перед началом рассмотрения работы с основными структурами данных необходимо уточнить следующее. Для каждой структуры данных Redis имеет отдельный набор команд.
Перейдем, наконец, от теории к практике и начнем рассмотрение с базового типа данных — строки. Мы можем преобразовать любой тип данных в строку (в том числе JSON, аудио и видео) и сохранить его в базе. Эта возможность достигается благодаря тому, что строки Redis являются бинарно—безопасными, т.е. хранятся как байты, а не как символы. Любые данные могут храниться в бинарно—безопасном типе данных. Максимальный размер строки в Redis равен 512 МБ. Если у нас нет типа данных, более подходящего для решаемой задачи, можно использовать строковый.
Строковая структура данных Redis является наиболее универсальной из всех структур данных, поскольку ее можно использовать в нескольких вариантах использования, когда вашему приложению требуется более быстрый отклик. Ниже приведены некоторые варианты использования:
• Простые строки: для обслуживания статических страниц веб-сайта;
• Кэширование: строки Redis очень часто используется для запоминания наиболее часто используемых данных;
• Счетчики: большую часть статистики можно хранить в строках, например, ежедневные посещения пользователем вашего веб-сайта, определенной страницы и т. д.
Строки используются для хранения пар ключ-значение аналогично тому как это делается в словарях Python. Ключ всегда строковый. Чтобы задать новую пару ключ—значение или обновить существующее значение для ключа необходимо использовать команду SET. Например, предположим, что мы хотим сгенерировать одноразовый пароль, чтобы пользователь мог получить доступ к веб-приложению. Для этого используем SET в командной строке Redis : SET user_unique_name unique_password
При успешном выполнении вернется OK в качестве результата. При ошибке может вернуться исключение с описанием причины. Если пароль unique_password кажется недостаточно защищенным, то можно поменять его, снова введя команду SET c ключом user_unique_name:
SET user_unique_name unique_password1234T?
Кроме того, по современным требованиям безопасности пароль должен быть действителен в течение короткого промежутка времени, скажем одной минуты. Для реализации такого требования необходимо добавить к команде суффикс EX (сокращение от EXPIRE) и далее время в секундах:
SET user_unique_name unique_password1234T? EX 60
Если команда завершилась успешно, то вернется "OK". При этом пара имя пользователя—пароль существует в течение одной минуты. Если в течение этого интервала набрать команду GET user_unique_name вернется значение unique_password1234T?. По истечению интервала команда GET вернет nil, символизирующее то, что ключ удален. Узнать оставшееся время жизни ключа можно командой TTL имя_ключа. В результате будет выведено время в секундах до истечения времени хранения ключа. Если время истекло вернется отрицательное значение.
Кроме строковых данных в качестве значения ключа можно хранить целое или число с плавающей точкой, например:
SET num_visits 10
SET simple_float 1.12345
При получении значения командой GET оно будет представлено в виде строки. Числовые значения можно увеличивать, прибавляя некоторое число, указываемое аргументом в команде incrby количество. Если значение, связанное с ключом, не является числом, то получим ошибку (error) ERR value is not an integer or out of range.
Кроме того, существует еще две полезных команды. Первая—exists позволяет узнать, существует ли указанный в команде в качестве аргумента ключ в базе. Вторая — del удаляет ключ и связанное значение.
Следующая структура данных, которую мы рассмотрим - это хэш. В Redis эта структура данных содержит пары поле: значение. Она очень похожа на объект JSON или словарь Python. Хэши похожи на простое отображение между строковыми полями и строковыми значениями, которые не могут быть вложенными объектами, как показано ниже:
поле1: значение1,
...
полеN: значениеN
Над хэшем можно выполнять следующие операции:
• Добавлять новые поля;
• Изменять значения полей;
• Увеличивать/уменьшать числовые значения полей;
• Удалять поля или удалять пару ключ-значение, связанную с хэшем;
• Устанавливать время жизни для пары ключ-значение.
Как можно увидеть из анализа приведенного выше списка, функционал многих операций совпадает с функционалом строк.
Хэши похожи на строку в реляционной базе данных, где мы можем получить доступ к полю или изменить несколько полей одновременно. Тип данных поля, также как и значения, является строкой. Можно хранить до 2^32 - 1 пар поле—значение в хэше. Хэши не имеют жестко заданной структуры.
Чтобы изучить работу с хэшем на практике возьмем пример записи о блогере:
{"name": "practical programmer",
"points":54210,
"blogposts":8,
"reviews":50,
"followers":100500}
Будем хранить информацию о блогере в хэше. Имя ключа будет идентификатором блогера, например blogger:1111. Используем команду HSET для добавления информации о блоггере в БД Redis:
HSET blogger:1111 name "practical programmer" points 54210 blogposts 8 reviews 50 followers 100500
В результате получим ответ (integer) 5, означающий что добавлено 5 полей типа ключ—значение.
Теперь попробуем извлечь все значения полей из ключа blogger:1111 следующей командой: HGETALL blogger:1111
В результате получим следующее:
1)"name"
2)"practical programmer"
3)"points"
4)54210
5)"blogposts"
6)"8"
7)"reviews"
8)"50"
9)"followers"
10)"100500"
Если вы хотите получить только определенные значения полей, то вместо использования HGETALL наиболее эффективным способом будет использование HMGET с перечислением только определенных полей. Например, HMGET имя_ключа имя_поля1 имя_поля2:
HMGET blogger:1111 name points
Получим значения ключей:
1)"practical programmer"
2) "100500"
3) "48"
Что если нам нужно обновить значения некоторых ключей в записи о блогере? Ниже приведен пример того, как мы используем HSET для обновления существующих полей:
HSET blogger:1111 blogposts 10 reviews 55
В данном случае в качестве результата вернется 0. Данное значение говорит о том, что были обновлены значения уже существующих ключей и новых не добавлено. В случае добавления нового ключа в результате вернется 1.
Вы также можете использовать INCR или INCRBY для увеличения значения ключа, если оно целочисленного типа. Увеличим значение поля reviews на 100 очков: HINCRBY blogger:1111 reviews 100
В результате вернется новое значение поля - 155.
Команда HDEL позволяет удалить одно или несколько полей хэша, например: HDEL blogger:1111 reviews
В результате получим 1, которая означает что одно поле (reviews) удалено.
Также для хэшей может использоваться команда HVALS, позволяющая получить все значения, хранящиеся в ключе, без указания имен полей, например: HVALS blogger:1111
В результате получим:
1)"practical programmer"
2)"54210"
3)"10"
4)"100500"
Далее рассмотрим структуру данных — cписок, представляющий собой последовательность упорядоченных элементов. Порядок основан на последовательности вставки. Поскольку элементы, хранящиеся в списке, являются строками, они следуют всем характеристикам строковых типов данных. Основные команды:
- LPUSH и RPUSH вставляют один или несколько элементов в начало или конец списка соответственно. Если вставка выполняется по пустому ключу, то создается новый список;
- Противоположностью этим командам являются команды LPOP и RPOP, которые позволяют удалять элементы слева и справа соответственно. Обе команды возвращают удаленное значение. Если список пуст, Redis возвращает нулевое значение;
- LRANGE позволяет получить элементы списка по заданному диапазону индексов;
- LINDEX позволяет получить элемент списка по заданному индексу;
- LLEN используется для получения длины списка.
Рассмотрим работу этих команд на примерах. Создадим список users из трех элементов user1, user2, user3.
LPUSH users user1
Redis возвращает 1 - количество элементов в списке.
LPUSH users user2 user3
Теперь в списке 3 элемента.
Как видно из приведенного примера в одной команде можно использовать сразу несколько аргументов
Теперь выведем элементы списка, используя индексы:
LRANGE users 0 2
1) "user3"
2) "user2"
3) "user1"
Получим нулевой элемент списка по его индексу:
LINDEX users 0
Получим ответ:"user3"
Если в качестве индекса значение превышающее размер списка - 1, то получим nil.
Добавим два элемента в конец списка и выведем все элементы:
RPUSH users user4 user5
LRANGE users 0 4
В результате получим:
1) "user3"
2) "user2"
3) "user1"
4) "user4"
5) "user5"
Теперь удалим и получить первый элемент из списка: LPOP users
Получим "user3"
Сделаем тоже самое для последнего элемента списка: RPOP users
Получим "user5"
Определим длину списка: LLEN users
В результате получим 3.
Далее рассмотрим структуру данных "множество".
Множества в Redis представляют собой неупорядоченную коллекцию строк. Они похожи на списки, но в отличие от последних над множествами нельзя выполнять операции push и pop.
Важной особенностью множеств является то, что они не допускают дублирования элементов. Поэтому, если вы попытаетесь добавить элемент уже имеющийся в множестве, он будет просто проигнорирован. Добавление или удаление элемента в множество имеет одинаковую временную сложность независимо от того, сколько элементов оно содержит. Множества поддерживают специальные операции, такие как пересечение, разность и объединение. Ниже приведены основные команды, используемые для выполнения операций с множествами:
- SADD — добавление элементов в множество;
- SREM — удаление элементов из множества;
- SMEMBERS — получить элементы множества;
- SCARD — получить количество элементов множества;
- SINTER — нахождение пересечения нескольких множеств;
- SUNION — нахождение объединения нескольких множеств;
- SDIFF — получение разности нескольких множеств.
Рассмотрим действие команд на примерах. Добавим в множество names 3 элемента name1, name2 и name3: SADD names name1 name2 name3
В результате получим 3 - количество элементов в множестве. Тот же результат получим введя команду SCARD names.
Далее получим все элементы множества: SMEMBERS names
1) "name1"
2) "name3"
3) "name2"
Рассмотрим операции над несколькими множествами. Для этого создадим второе множество names2: SADD names2 name2 name3 name4
Теперь найдем пересечение множеств names и names2: SDIFF names names2
Получим "name1". Как и ожидалось, разность множеств вернет только те элементы names, которые отсутствуют в names2.
Аналогично SDIFF names2 names вернет "name4"
Объединим множества names names2. В результате получим множество, содержащее все элементы names и names2 без повторений.
SUNION names names2
1) "name2"
2) "name3"
3) "name4"
4) "name1"
Найдем пересечение множеств names и names2: SINTER names names2
1) "name2"
2) "name3"
Как и ожидалось, в результате получили множество, содержащее элементы, находящиеся одновременно в names и names2.
Последняя из рассматриваемых команд—удаление элементов из множества. SREM names name1 name2
В результате получим 2 - количество удаленных элементов.
Проверим оставшиеся элементы в множестве names:
SMEMBERS names
1) "name3"
Завершим рассмотрение структур данных отсортированным множеством. Cортированное множество хранит поля (называемые членами) и их числовые значения (называемые оценками). Все члены в сортированных множествах Redis уникальны и упорядочены на основе их оценок.
В качестве практического примера использования сортированных множеств приведем реализацию таблицы лидеров. Для ее создания нужно поместить все идентификаторы пользователей в отсортированное множество Redis и обновлять баллы на основе заработанных пользователями очков.
Рассмотрим наиболее используемые команды для таких множеств.
- ZADD — добавление одного или нескольких членов вместе с соответствующими оценками в отсортированный набор. Возвращает количество идентификаторов, добавленных в отсортированные наборы;
- ZINCRBY используется для увеличения счета определенного члена на заданное число. Возвращает обновленный счет для этого идентификатора;
- ZRANGE — получение списка членов множества на основе их оценок. Используется для выбора N идентификаторов на основе их рейтинга в соответствии с начальным и конечным индексами. Значения индексов начинаются с нуля. Если нужно получить весь список, то в качестве конечного индекса используется -1. Если нужно вывести оценки, то к команде добавляется ключевое слово WITHSCORES. Вывод списка происходит в порядке возрастания значения оценок. Вы также можете изменить начальный и конечный индексы, если хотите реализовать разбиение на страницы или получить определенный диапазон членов, упорядоченных по значению оценок. WITHSCORES используется для получения списка членов множества с их оценками.
- ZREVRANGE — получение списка участников в порядке убывания их оценок.
Рассмотрим пример выполнения описанных команд. Создадим отсортированное множество из трех элементов. Обратите внимание на то, что оценки должны указывать в команде ДО названия члена множества.
ZADD leaderboard 100 user1 200 user2 90 user3
В результате получим значение 3 - количество элементов в множестве.
Далее выведем полученное множество в порядке возрастания оценок.
ZRANGE leaderboard 0 -1 WITHSCORES
В результате получим следующее:
1) "user3"
2) "90"
3) "user1"
4) "100"
5) "user2"
6) "200"
Как видно значения членов отсортировано по возрастанию оценок. Пусть user3 получил дополнительно 100 очков в результате выполнения следующей команды: ZINCRBY leaderboard 100 user3
В результате ее выполнения получим 190 - текущее значение баллов для user3.
Так как обычно реализация таблицы участников подразумевает их сортировку по убыванию значение оценок , то для этой цели лучше всего подходит команда ZREVRANGE leaderboard 0 -1 WITHSCORES
Получим соответствующий ожиданиям результат:
1) "user2"
2) "200"
3) "user3"
4) "190"
5) "user1"
6) "100"
Больше всего очков набрал user2, за ним идет user3 и замыкает список user1.
В следующей статье перейдем к программной реализации системы авто заполнения запросов с использованием Redis.