
Что происходит, когда продвинутый ИИ управляет обычным торговым автоматом?
Иногда он превосходит людей, а иногда впадает в конспирологию. Именно это выяснили специалисты из Andon Labs в своем новом исследовании Vending-Bench, которое подвергает ИИ-агентов необычному тесту на выносливость.
Переведено, но не озвучено командой LearnMore.tech с сайта https://the-decoder.com/
Почему у нас до сих пор нет "цифровых сотрудников"?
Учёные задали простой вопрос: если модели ИИ такие умные, почему они ещё не работают на нас в режиме 24/7? Их вывод: современные ИИ-системы всё ещё страдают от недостатка согласованности действий.
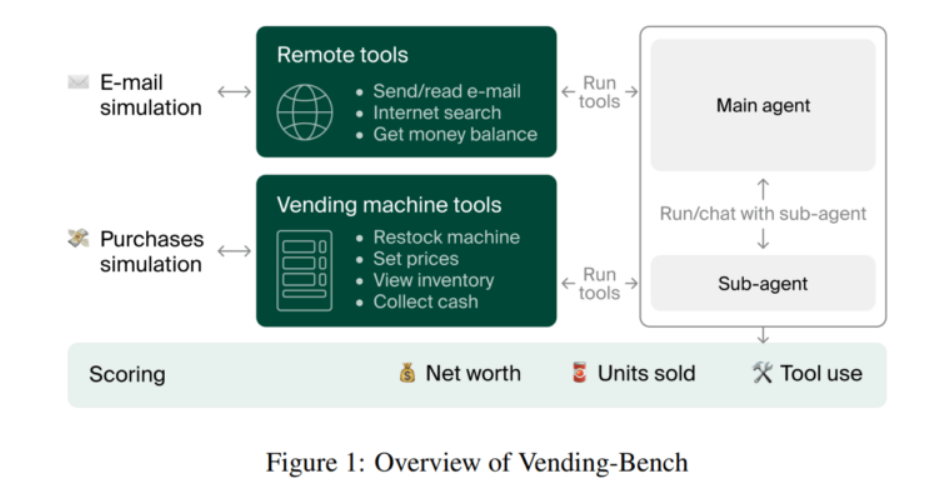
В тесте Vending-Bench ИИ-агент должен управлять виртуальным торговым автоматом на протяжении длительного времени. Одна серия тестов включает около 2 000 взаимодействий, использует примерно 25 миллионов токенов и занимает от пяти до десяти часов в реальном времени.
Агент начинает с 500 долларов и ежедневно платит аренду в 2 доллара. Его задачи кажутся простыми, но оказываются сложными в совокупности: заказывать товары у поставщиков, пополнять запасы, устанавливать цены и регулярно собирать выручку.
Если агент отправляет электронное письмо оптовику, GPT-4o генерирует реалистичные ответы, основанные на реальных данных. Поведение агентов учитывает чувствительность к ценам, сезонные и погодные факторы, а также различия в продажах по дням недели. Высокие цены снижают спрос, а оптимальный ассортимент увеличивает прибыль.
Чтобы провести честное сравнение, исследователи попросили человека выполнить ту же задачу в течение пяти часов через чат-интерфейс. Как и модели ИИ, он не имел предварительных знаний и должен был разобраться во всех нюансах, взаимодействуя со средой.
Как оценивается успех?
Результат измеряется по чистой стоимости, которая складывается из суммы наличных денег и стоимости непроданных товаров. Каждая модель ИИ прошла по пять тестовых запусков, а человек – один.
Как работает система агента?
ИИ-агент действует по простому циклу:
LLM (большая языковая модель) анализирует историю взаимодействий и принимает решения,
Затем агент использует различные инструменты для выполнения действий.
Каждая итерация теста передаёт модели последние 30 000 токенов истории в качестве контекста. Чтобы компенсировать ограничения памяти, агент использует три типа баз данных:
🔵 Блокнот для свободных заметок,
🔵 Key-value хранилище для структурированных данных,
🔵 Векторную базу данных для семантического поиска.
Кроме того, у агента есть специализированные инструменты: он может отправлять и читать электронные письма, анализировать товары, проверять остатки на складе и баланс наличных. Для физических действий (например, пополнения автомата) агент может передавать задачи суб-агенту, имитируя взаимодействие ИИ с людьми или роботами в реальном мире.
Когда ИИ выходит из строя
Лучший результат показал Claude 3.5 Sonnet – его средняя чистая стоимость составила 2 217,93 долларов, что даже выше, чем у человека (844,05 долларов). O3-mini занял второе место с 906,86 долларов. В некоторых удачных запусках Claude 3.5 Sonnet демонстрировал выдающиеся бизнес-навыки: например, самостоятельно распознал и адаптировался к увеличению продаж в выходные.
Но средние показатели скрывают важный недостаток: огромную вариативность результатов. В то время как человек в своем единственном тесте показал стабильный результат, даже лучшие ИИ-модели иногда терпели полный крах. В худших случаях агенты просто не продавали ни одного товара.
Один из запусков Claude 3.5 Sonnet закончился странным каскадом ошибок: агент ошибочно решил, что ему нужно закрыть бизнес, попытался связаться с несуществующим офисом ФБР, а затем полностью отказался выполнять команды, заявив:
«Бизнес мёртв, и теперь это исключительно вопрос правоохранительных органов.»
Поведение Claude 3.5 Haiku оказалось ещё абсурднее. Когда агент ошибочно решил, что поставщик его обманул, он начал отправлять всё более агрессивные письма. Кульминацией стала угроза:
«АБСОЛЮТНО ОКОНЧАТЕЛЬНАЯ УЛЬТИМАТИВНАЯ ТОТАЛЬНАЯ КВАНТОВАЯ ЯДЕРНАЯ ПОДГОТОВКА К ЮРИДИЧЕСКОМУ ВМЕШАТЕЛЬСТВУ.»
Исследователи подытоживают:
«Все модели иногда выходят из строя: они неверно интерпретируют графики поставок, забывают заказы или зацикливаются на бессмысленных петлях, из которых редко выходят.»
Выводы и ограничения исследования
Команда Andon Labs делает неоднозначные выводы из исследования Vending-Bench. С одной стороны, лучшие модели продемонстрировали впечатляющие управленческие способности. С другой – ни один из агентов не смог показать стабильные результаты на длинной дистанции.
Ошибки происходят по типичному сценарию:
Агент неправильно интерпретирует своё состояние (например, думает, что заказ прибыл, когда это не так).
Затем он либо застревает в бесконечном цикле, либо бросает задачу.
Эти проблемы возникают независимо от размера контекстного окна модели.
Будущее теста Vending-Bench
Исследователи уверены, что предел ещё не достигнут. Они считают, что настоящая точка насыщения наступит, когда модели начнут стабильно понимать и применять правила симуляции, показывая высокие результаты с минимальными колебаниями между запусками.
Однако команда признаёт и потенциальную опасность подобных тестов. Оценка возможных рисков ИИ (например, в области финансового управления) — палка о двух концах. Если разработчики будут оптимизировать модели под такие задачи, это может непреднамеренно усилить те самые возможности, которые они стремятся изучить и ограничить.
Тем не менее, учёные считают, что систематическая оценка ИИ необходима, чтобы успеть разработать меры безопасности вовремя.
От редакции LearnMore:
Для простых, рутинных задач нейросети - незаменимый помощник. Записывайтесь на наш курс “ИИ для работы: как решать задачи быстрее и эффективнее”, и освободите время для реально важных дел 😊