Введение
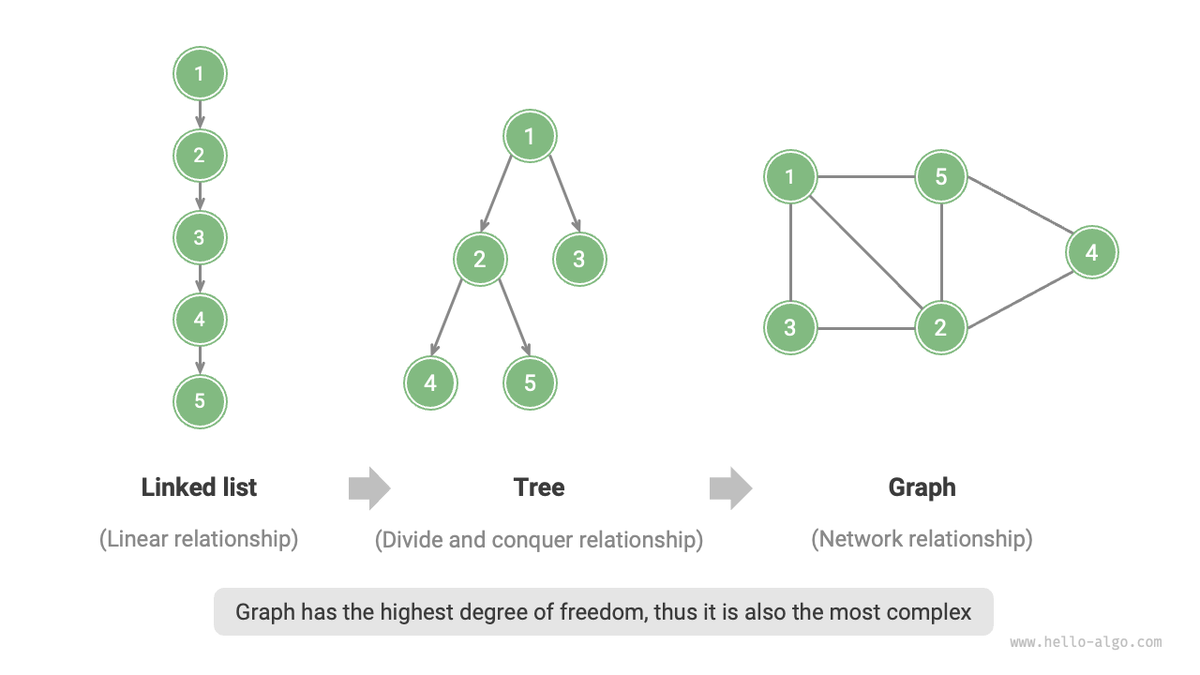
Деревья и графы — это фундаментальные структуры данных, которые играют ключевую роль в программировании, алгоритмах и различных областях компьютерных наук. Они представляют собой мощные инструменты для моделирования сложных систем, где элементы связаны между собой различными зависимостями. От социальных сетей и сетевых протоколов до организации файловых систем и алгоритмов поиска — графовые структуры пронизывают многие сферы информатики.
Графы позволяют описывать взаимосвязи между объектами в виде узлов и соединяющих их рёбер, что делает их незаменимыми при решении задач маршрутизации, анализа данных и построения эффективных алгоритмов. Деревья, в свою очередь, являются частным случаем графов и широко применяются в организации иерархических данных, таких как структуры каталогов, семейные деревья, базы данных и многие алгоритмы искусственного интеллекта.
Знание основ работы с графами и деревьями позволяет эффективно решать широкий спектр задач: от поиска кратчайшего пути в сети дорог до оптимизации вычислений в больших данных. В этой статье мы подробно разберём основные понятия графов и деревьев, их разновидности, способы представления в коде, а также рассмотрим базовые алгоритмы, которые позволяют работать с этими структурами.
Графы: основные понятия
Определение
Граф (Graph) — это структура данных, состоящая из вершин (nodes, vertices) и рёбер (edges), которые соединяют эти вершины. Графы широко используются в различных областях, таких как социальные сети, маршрутизация в компьютерных сетях, моделирование дорог и транспортных систем, а также в анализе больших данных.
Графы бывают различных типов, но в основе их классификации лежит наличие направления у рёбер. Различают два основных вида графов:
- Ориентированный граф — рёбра имеют направление, что означает, что связь между вершинами асимметрична. Если существует ребро (a → b), это означает, что из вершины a можно попасть в b, но не обязательно наоборот.
- Неориентированный граф — рёбра не имеют направления, то есть связь между вершинами симметрична. Если существует ребро (a — b), это означает, что a и b соединены двусторонней связью.
Кроме того, графы могут различаться по своим свойствам, таким как наличие циклов, связность, наличие весов у рёбер и другие характеристики. Они представляют собой мощный инструмент для решения сложных задач, связанных с анализом и обработкой данных, и являются основой множества алгоритмов, применяемых в программировании.
Виды графов
- Взвешенные и невзвешенные
В взвешенном графе каждому ребру присвоен вес (стоимость перемещения между вершинами). Такие графы часто используются в задачах поиска кратчайшего пути, например, в навигационных системах и логистике.
В невзвешенном графе у рёбер нет весов. Такие графы встречаются, например, при моделировании социальных сетей, где рёбра просто показывают наличие связи между пользователями без учёта её силы или значимости. - Связные и несвязные
Связный граф — из любой вершины можно попасть в любую другую (для неориентированного графа). Такие графы встречаются в задачах, где важно, чтобы каждая точка была доступна из любой другой.
Несвязный граф — содержит хотя бы одну вершину, недостижимую из других. Несвязные графы часто представляют системы с изолированными элементами, например, в анализе социальных сетей можно найти группы пользователей, которые не имеют общих связей. - Циклические и ациклические
Циклический граф содержит хотя бы один цикл (путь, ведущий к той же вершине). Такие графы широко используются в анализе сетей, моделировании биологических процессов и построении цепочек поставок.
Ациклический граф не содержит циклов. Одним из частных случаев ациклических графов являются ориентированные ациклические графы (DAG), которые активно применяются в компиляторах, анализе зависимостей в программировании, построении пайплайнов данных и машинном обучении. - Двудольные графы
Граф, вершины которого можно разбить на два множества, так что рёбра соединяют только вершины из разных множеств. Такие графы часто встречаются в задачах распределения ресурсов, например, в теории расписаний, где одна группа вершин представляет сотрудников, а другая — задачи, которые им нужно выполнить.
Представление графов в коде
Графы можно представлять в виде:
- Матрицы смежности (Adjacency Matrix) — двумерный массив, где graph[i][j] указывает на наличие ребра между вершинами i и j.
- Списка смежности (Adjacency List) — массив списков, где каждая вершина хранит список смежных вершин.
Пример представления списка смежности на Python:

Деревья: основные понятия
Определение
Дерево — это частный случай графа, который обладает рядом характерных свойств, делающих его удобной структурой для хранения и обработки данных. Оно представляет собой связный, ациклический, ориентированный граф, в котором связи между вершинами образуют иерархическую структуру. Рассмотрим ключевые свойства деревьев подробнее:
- Ацикличность — дерево не содержит циклов, то есть невозможно вернуться к той же вершине, следуя по рёбрам. Это означает, что если двигаться от корня дерева к его листьям, мы всегда будем углубляться в структуру, но никогда не попадём в замкнутый путь. Это свойство играет важную роль в таких задачах, как сортировка, поиск и построение эффективных алгоритмов.
- Связность — дерево всегда является связной структурой, что означает, что между любыми двумя вершинами существует единственный путь. Это свойство делает деревья удобными для представления иерархий и поиска оптимальных путей в различных задачах, например, в базах данных или алгоритмах искусственного интеллекта.
- Ориентированность — в большинстве случаев дерево можно рассматривать как направленный граф, где каждое ребро направлено от родителя к потомку. Это создаёт чёткую иерархию, позволяющую легко интерпретировать отношения между элементами, будь то элементы файловой системы, узлы в бинарном дереве поиска или вершины в организационной структуре предприятия.
- Иерархичность — дерево организовано вокруг корневой вершины, от которой отходят дочерние элементы (потомки). Эта структура позволяет представлять вложенные отношения в естественной форме, аналогичной реальному миру (например, семейные деревья, структуры каталогов, система категорий в интернет-магазинах).
- Однозначный путь между вершинами — в дереве существует единственный путь между любой парой вершин, что отличает его от произвольного графа. Это делает возможным эффективное использование деревьев в алгоритмах, таких как поиск в глубину (DFS) и поиск в ширину (BFS), а также в алгоритмах балансировки и оптимизации структуры данных.
Благодаря этим свойствам деревья широко применяются в программировании, алгоритмах машинного обучения, компиляторостроении, сетевых протоколах и многих других областях информатики.
Виды деревьев
Бинарное дерево — это частный случай дерева, в котором каждая вершина может иметь не более двух потомков (левый и правый). Это одно из наиболее распространённых деревьев, используемых в информатике, поскольку оно обеспечивает эффективные операции вставки, поиска и удаления элементов.
Бинарные деревья могут быть как заполненными, так и разреженными. В заполненном бинарном дереве все уровни, кроме последнего, полностью заняты, а листья расположены максимально компактно слева. Такое свойство полезно, например, в кучах (Heap), где оно влияет на эффективность работы структуры.
Двоичное дерево поиска (BST, Binary Search Tree)
Двоичное дерево поиска (BST) — это бинарное дерево с дополнительным свойством упорядоченности:
- Для каждой вершины значение всех элементов в левом поддереве меньше значения родителя.
- Значение всех элементов в правом поддереве больше значения родителя.
Такое правило позволяет реализовывать операции поиска, вставки и удаления за O(log n) в среднем случае, если дерево сбалансировано. Однако если данные вставляются в порядке возрастания или убывания, BST может выродиться в линейный список, что ухудшает сложность до O(n). Для предотвращения этого применяют сбалансированные деревья.
Пример использования BST — в структурах данных для поисковых систем, баз данных и индексирования файлов, где требуется быстрый доступ к элементам.
Сбалансированные деревья
Балансировка дерева — это процесс, позволяющий ограничить его высоту, обеспечивая оптимальное время выполнения операций. В несбалансированном дереве высота может достигать O(n), тогда как в сбалансированном — O(log n), что значительно улучшает производительность.
Наиболее популярные виды сбалансированных деревьев:
- AVL-деревья — используют балансировку на основе разницы высот поддеревьев. Если разница высот левого и правого поддеревьев превышает 1, выполняется автоматическое вращение для восстановления баланса. AVL-деревья подходят для систем, требующих частого поиска, но могут быть менее эффективны при массовых операциях вставки/удаления.
- Красно-чёрные деревья — обеспечивают амортизированное O(log n) время работы за счёт цветового кодирования узлов (красный/чёрный) и определённых правил балансировки. Они широко применяются в реализациях множества стандартных библиотек (например, std::map в C++ и TreeSet в Java).
Heap (Куча)
Куча (Heap) — это специальное бинарное дерево, в котором выполняется свойство кучи:
- В Min-Heap (минимальная куча) значение родителя меньше или равно значениям потомков. Минимальный элемент всегда находится в корне.
- В Max-Heap (максимальная куча) значение родителя больше или равно значениям потомков.
Кучи используются в приоритетных очередях, алгоритмах сортировки (пирамидальная сортировка, heap sort) и для эффективного управления динамической памятью.
Благодаря этим видам деревьев можно строить быстрые и надёжные структуры данных, оптимизированные для различных задач: от поиска и хранения данных до работы с большими объёмами информации.
Реализация бинарного дерева на Python
Основные алгоритмы работы с графами и деревьями
1. Поиск в глубину (DFS)
Используется для обхода графов/деревьев.
Реализуется с помощью рекурсии или стека.
2. Поиск в ширину (BFS)
Использует очередь для обхода.
3. Алгоритм Дейкстры (поиск кратчайшего пути в графе с неотрицательными весами).
4. Алгоритм Прима (построение минимального остовного дерева).
5. Алгоритм Краскала (минимальное остовное дерево через сортировку рёбер).
Заключение
Деревья и графы — это одни из самых мощных и универсальных структур данных, находящих широкое применение в самых разных сферах программирования и компьютерных наук. Они играют ключевую роль в алгоритмах маршрутизации, машинном обучении, компиляторостроении, анализе данных, поисковых системах, сетевых технологиях и даже в игровой индустрии. Благодаря своей гибкости, графовые структуры используются для моделирования сложных систем, а деревья позволяют эффективно организовывать иерархические данные.
Глубокое понимание принципов работы деревьев и графов, а также знание алгоритмов, предназначенных для их обработки, помогает разработчикам решать широкий спектр задач — от поиска кратчайшего пути в навигационных сервисах до оптимизации вычислений в больших данных. Многие алгоритмы, такие как поиск в ширину (BFS), поиск в глубину (DFS), алгоритм Дейкстры, алгоритмы построения минимального остовного дерева и сбалансированные деревья, являются основой множества современных технологий.
В дальнейшем мы рассмотрим более сложные и продвинутые алгоритмы работы с деревьями и графами, их оптимизацию, способы повышения эффективности и реальные примеры их использования в промышленном программировании. Понимание этих структур данных поможет создавать высокопроизводительные системы и разрабатывать эффективные решения для сложных задач.