Введение
Хеш-таблицы – это одна из самых эффективных структур данных, позволяющая быстро находить, добавлять и удалять элементы. Их главное преимущество – высокая скорость выполнения операций, которая в среднем составляет O(1). Это делает их незаменимыми для таких задач, как управление базами данных, кеширование информации, работа с компиляторами и многие другие задачи в области программирования.
Хеш-таблицы активно применяются не только в традиционных алгоритмах и структурах данных, но и в современных технологиях, таких как обработка больших данных, машинное обучение, искусственный интеллект, криптография и кибербезопасность. Они позволяют организовать удобное хранение и быстрый поиск данных, минимизируя нагрузку на вычислительные ресурсы и обеспечивая высокую производительность.
Основные принципы работы хеш-таблиц
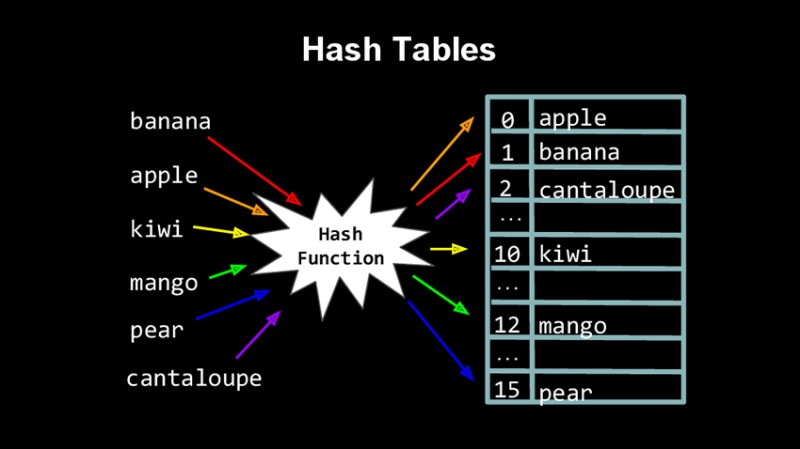
Хеш-таблица представляет собой массив фиксированного размера, где каждый элемент (бакет) может содержать один или несколько объектов. Основные компоненты хеш-таблицы:
- Хеш-функция – алгоритм, который преобразует входные данные (ключ) в числовой индекс массива. Хорошая хеш-функция должна равномерно распределять данные по таблице, минимизируя вероятность коллизий.
- Бакеты – элементы массива, в которых хранятся данные. Каждый бакет может содержать один объект или список объектов, если произошла коллизия.
- Методы разрешения коллизий – стратегии, которые применяются, если два разных ключа преобразуются в один и тот же индекс. Наиболее популярные методы – цепочки (связные списки внутри бакетов) и открытая адресация (поиск свободного места в таблице).
Как работает хеш-таблица?
- Хеширование: Когда элемент добавляется в хеш-таблицу, его ключ проходит через хеш-функцию, которая вычисляет индекс массива.
- Разрешение коллизий: Если два разных ключа приводят к одному и тому же индексу, применяется один из методов разрешения коллизий, например, метод цепочек (хранение нескольких значений в одном бакете) или открытая адресация (поиск другой ячейки в таблице).
- Поиск элемента: Хеш-функция вычисляет индекс, затем в соответствующем бакете выполняется поиск нужного значения. Если используются методы разрешения коллизий, может потребоваться проверка нескольких значений.
- Удаление элемента: Найденный элемент удаляется, при необходимости обновляются ссылки или помечаются пустые ячейки, чтобы сохранить корректность структуры таблицы.
- Перехеширование: Когда хеш-таблица становится слишком загруженной, выполняется её расширение с перераспределением элементов. Новый размер таблицы обычно выбирается в два раза больше текущего, чтобы уменьшить вероятность коллизий и сохранить высокую производительность.
Достоинства хеш-таблиц
- Быстрый поиск – операции выполняются в среднем за O(1), что делает хеш-таблицы быстрее, чем деревья поиска, списки и другие структуры данных.
- Гибкость – они подходят для хранения больших объемов данных и могут использоваться в самых разных приложениях, от баз данных до кеширования веб-страниц.
- Простота использования – многие языки программирования имеют встроенные структуры данных, основанные на хеш-таблицах, например, dict в Python или HashMap в Java.
- Эффективное использование памяти – при корректном выборе размеров и стратегии обработки коллизий хеш-таблицы позволяют минимизировать расход памяти и поддерживать высокую производительность.
Недостатки хеш-таблиц
- Коллизии – если хеш-функция плохо распределяет данные, увеличивается число коллизий, что снижает скорость работы.
- Затраты на память – в некоторых реализациях требуется дополнительное место для хранения вспомогательных структур данных или для перехеширования.
- Отсутствие порядка – элементы в хеш-таблице не хранятся в отсортированном виде, поэтому доступ к ним возможен только по ключам.
- Неэффективность в сложных операциях – такие операции, как нахождение минимального или максимального элемента, требуют полного обхода таблицы, что делает их менее эффективными по сравнению с деревьями поиска.
- Динамическое изменение размеров – если таблица становится слишком загруженной, требуется её увеличение и перераспределение данных, что может привести к временным затратам на обработку.
Где применяются хеш-таблицы?
- Кеширование данных – браузеры, базы данных и веб-приложения используют хеш-таблицы для быстрого доступа к ранее запрошенной информации, что снижает нагрузку на серверы.
- Хранение паролей – пароли хранятся в зашифрованном виде с использованием криптографических хеш-функций, что обеспечивает их безопасность.
- Поиск дубликатов – при обработке больших объемов данных хеш-таблицы помогают быстро находить повторяющиеся записи и устранять их.
- Компиляторы – в компиляторах и интерпретаторах хеш-таблицы помогают быстро находить идентификаторы переменных, функций и классов.
- Базы данных – индексация данных с помощью хеш-таблиц ускоряет выполнение запросов и повышает эффективность работы с хранилищами данных.
- Сетевые технологии – алгоритмы маршрутизации и балансировки нагрузки используют хеш-таблицы для быстрого поиска сетевых маршрутов и обработки пакетов данных.
- Генерация уникальных идентификаторов – используется в блокчейне, безопасности и различных распределённых системах для быстрого создания и поиска уникальных значений.
- Анализ больших данных – в обработке логов, машинном обучении и аналитике хеш-таблицы помогают ускорить процессы поиска и фильтрации информации.
Заключение
Хеш-таблицы – это мощный инструмент, который позволяет значительно ускорить операции поиска и хранения данных. Они широко применяются в программировании, особенно в тех областях, где требуется высокая скорость обработки информации. Однако эффективность их работы напрямую зависит от выбора качественной хеш-функции и стратегии разрешения коллизий. При правильном проектировании хеш-таблицы позволяют достичь высокой производительности и снизить нагрузку на систему.
Несмотря на некоторые ограничения, такие как потребление памяти и необходимость перехеширования, хеш-таблицы остаются одной из самых востребованных структур данных. Их можно встретить в самых разных приложениях – от веб-разработки до систем искусственного интеллекта. Постоянное развитие алгоритмов хеширования и методов оптимизации делает их ещё более эффективными и универсальными в использовании.