Динамика «гонки вооружений» LLM одним слайдом
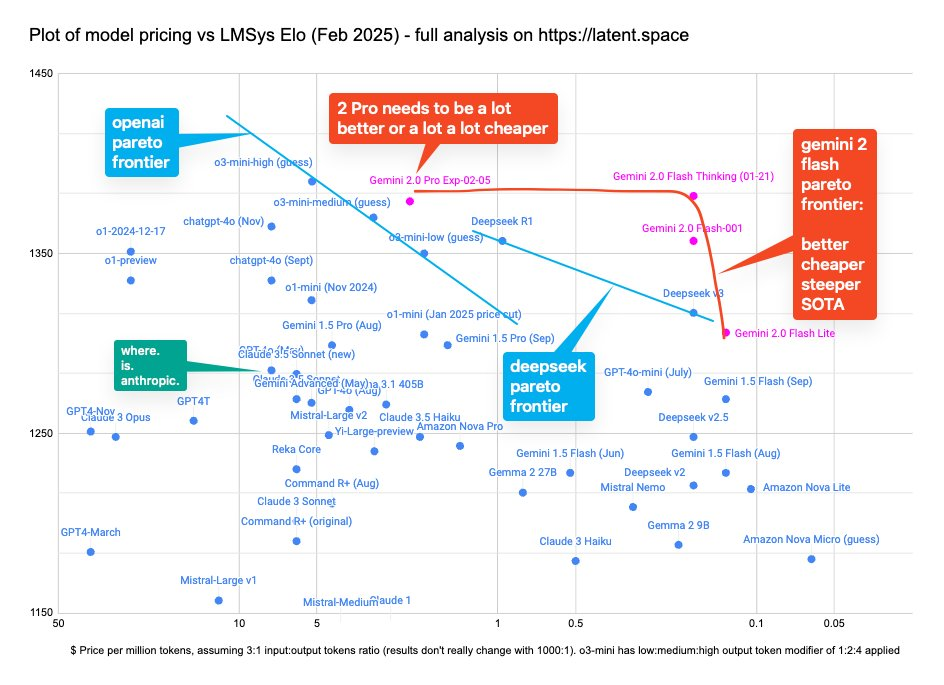
«Гонка вооружений» на рынке больших языковых моделей (LLM) определяется просто: все стараются получить максимально высокую точность при минимальной цене. А а «фронтир» отражает лучшие на данный момент варианты по сочетанию этих двух параметров.
Диаграмма показывает [1], как разные версии языковых моделей (от OpenAI, Deepseek, Google «Gemini», Anthropic и др.) соотносятся по:
· стоимости (ось X): цена за миллион токенов - чем правее точка, тем дешевле использование модели (ниже стоимость за миллион токенов).
· качеству (ось Y): рейтинг LMSys Elo - чем выше точка, тем сильнее модель (лучшее качество ответов/результатов).
На диаграмме видны две основные "границы эффективности" (pareto frontier):
- Синяя линия от OpenAI, показывающая их модели
- Оранжевая линия от Gemini 2, которая, судя по надписи, предлагает "лучше, дешевле, круче"
- Более дорогие и мощные модели в верхней левой части (например, различные версии GPT-4)
- Средний сегмент в центре (Claude 3.5, Gemini 1.5)
- Более доступные модели в правой части (Amazon Nova Lite, Gemini 1.5 Flash)
Ключевые выводы (по состоянию на февраль 2025)
· Чемпион в соотношении цена-производительность - Gemini 2.0 Flash Thinking (лучше, чем DeepSeek r1 (по ELO) и дешевле
· Стоимость возможностей GPT-4 упала в 1000 раз за 18 месяцев
· Скорость роста возможностей моделей просто немыслимая – так не бывает, … но так есть!
PS Спецы из Google DeepMind полагают, что они близки к получению «Мандата Неба» ("Mandate of Heaven" (天命, Тяньмин)) [2]. Когда говорят, что компания имеет "Mandate of Heaven" в сфере ИИ, это означает, что она занимает лидирующую позицию не просто благодаря рыночной доле, но и благодаря признанию её технологического превосходства и инновационного лидерства.
Но вряд ли конкуренты согласятся.
#ИИгонка