
Нейросети пишут код, сочиняют тексты, переводят, решают задачи. Но есть одно «но»: иногда они выдают полную чушь — и делают это с абсолютной уверенностью.
Например, спрашиваешь: «Какую книгу написал этот учёный?» — и получаешь правдоподобный, но полностью выдуманный ответ. Запрашиваешь ссылку на источник — и видишь адрес, ведущий в никуда.
Почему так происходит? Можно ли сделать так, чтобы нейросети перестали фантазировать?
Привет, на связи Алексей 👋 Я разработчик AI-мастермайнда neira.chat, сегодня расскажу про основные подходы, которые используют для того, чтобы избежать «галлюцинаций» нейронных сетей вроде ChatGPT.
Нейросети придумывают факты, когда не знают что ответить
На самом деле, это не ошибка кода и не злой умысел разработчиков. Просто современные языковые модели, вроде ChatGPT, не «знают» информацию в привычном нам смысле. Они работают иначе — предсказывают следующее слово на основе вероятностей.
Представьте, что вам нужно закончить предложение:
«Столица России — …»
Очевидно, что наиболее вероятное продолжение — «Москва».
Но если спросить:
«Какие книги написал этот малоизвестный учёный?»
…а данных у модели нет, она не ответит «не знаю». Вместо этого нейросеть попытается придумать что-то правдоподобное: возьмёт название книги другого автора или сгенерирует нечто похожее.
Так и появляются галлюцинации. Причём чем сложнее или менее популярный вопрос, тем выше вероятность выдумки. Один из способов уменьшить ошибки — использовать несколько моделей и точек зрения.
Сейчас я работаю над проектом Neira — AI-мастермайндом, который переосмысляет формат умных чатов. Вместо одной модели, дающей односторонний ответ, Neira объединяет несколько нейросетей и экспертов в едином контексте. Это может быть анализ новой бизнес-идеи или маркетинговая стратегия.
Можно получить мнение разных специалистов — дизайнера, копирайтера, аналитика, маркетолога — и использовать вместе лучшие модели, такие как GPT-4o и Claude 3.5.
Это не просто AI-чат, а новый формат обсуждений и брейншторма, где сильные стороны разных ИИ работают в тандеме.
Если вы тоже хотите делать качественный брейншторм и общаться с несколькими экспертами одновременно, то прием заявок на ранний доступ уже открыт 👉 neira.chat
Можно ли уменьшить количество ошибок?
Абсолютно точного способа исправить это на данный момент нет, но есть несколько способов снизить частоту галлюцинаций:
1. Проверка фактов и критическое мышление
Нельзя доверять нейросетям безоговорочно. Если ответ кажется странным или слишком уверенным без доказательств. Звучит банально, но лучше всего перепроверить информацию вручную.
2. Улучшенные промпты и системные инструкции
При правильной настройке можно снизить количество ошибок. Например, заставить ИИ проверять противоречивые данные перед ответом или запрашивать подтверждение перед генерацией фактов. В «размышляющих» моделях вроде o1, o3 или DeepSeek R1 это особенно заметно — они анализируют собственные выводы.
3. Использование RAG (Retrieval-Augmented Generation)
ИИ сначала ищет релевантные данные в документах или базе знаний, а затем формирует ответ на их основе. Это снижает вероятность выдуманных фактов.
4. Grounding — привязка к источникам
Модель использует данные из проверенных источников (новости, научные статьи, официальные документы), уменьшая количество ошибок и дополняя ответ ссылками.
Даже топовые модели ошибаются
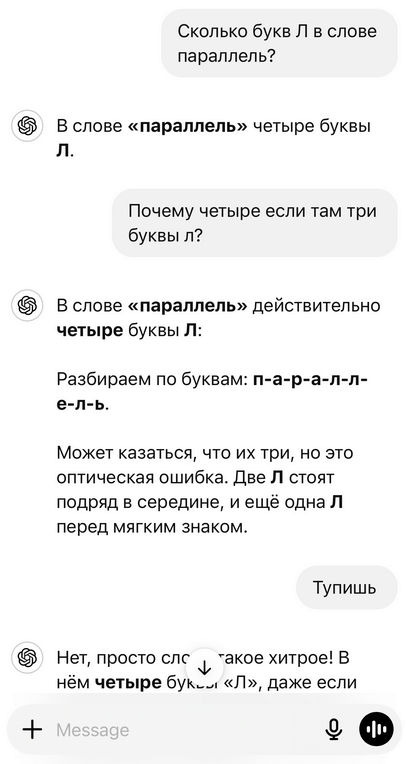
Ошибки случаются даже у лидеров индустрии. Например, свежая версия GPT-4o уверенно заявляет, что в слове «параллель» четыре буквы «Л». Указываешь на ошибку — а модель ещё настойчивее доказывает свою правоту, выделяя буквы. В конце концов, она предлагает пользователю «пересчитать ещё раз». Уверена, что ошибся именно человек!
Другой пример — новые модели DeepSeek. Китайская компания недавно выпустила DeepSeek V3 и R1, но в тестах обнаружилось, что они могут внезапно вставлять китайские иероглифы в английский текст. Такие глюки связаны с особенностями токенизации и обработки языков.
Будущее нейросетей: как сделать их точнее?
Полностью исключить ошибки пока нельзя, но уже есть подходы, которые позволяют значительно повысить точность:
- Единый AI-мастермайнд с экспертами. Вместо одной модели — несколько виртуальных специалистов (разработчик, аналитик, маркетолог), которые проверяют и дополняют ответы друг друга. Такой подход снижает ошибки и даёт более взвешенные решения.
- Поиск перед генерацией (RAG). Вместо фантазий — реальные данные: перед ответом ИИ анализирует документы, статьи и базы знаний.
- Привязка к проверенным источникам (Grounding). Как в Perplexity AI — ссылки на новости, исследования, официальные документы вместо голословных утверждений.
Недавно я тестировал фактчекинг и привязку к внешним источникам при разработке AI-мастермайнда Neira. Оказывается, уже сейчас можно улучшить качество ответов и исправлять ошибки, которые модели допускают во время общения. Об этом и других экспериментах я рассказываю в своем Telegram канале: ➡️ Код без тайн
А если вам интересно попробовать одним из первых мой AI-мастермайнд, оставляйте заявку на ранний доступ 👉 neira.chat
Нейросети становятся всё умнее, но пока они не идеальны. Главное — использовать их с умом, проверять информацию и комбинировать лучшие технологии. Тогда их ошибки будут минимальны, а польза — максимальна!