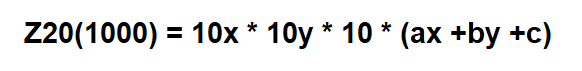и это как вы поняли список всего из 2 в 10й степени что равно 1024 элементов списка нашей задачи - так работают моды групп молекул белков РНК
всё гениальное просто бро ->
Модели, работающие с большими списками данных, такими как списки из 1000 элементов, имеют множество применений в различных областях, включая машинное обучение, обработку естественного языка и биоинформатику.

*
да мы знали об этом ещё в школе -
это же метод половинного деления
..
итерации днк позволяют решать любую задачу за
10 тысяч лет чтобы создать новый ген или группу генов
в ИИ всё происходит во многом или совсем не так
*
Применение моделей к спискам из 1000 элементов:
- Обработка данных:
Модели могут анализировать списки из 1000 элементов, чтобы выявить паттерны, тренды или аномалии. Например, в финансовых данных это может помочь в предсказании рыночных изменений. - Классификация и кластеризация:
Списки могут содержать характеристики объектов, которые можно классифицировать. Например, в биоинформатике список из 1000 белков может использоваться для классификации их функций или структур. - Рекомендательные системы:
Модели могут использовать списки из 1000 элементов для создания рекомендаций. Например, в системах рекомендаций фильмов или товаров, где каждый элемент представляет собой продукт или фильм, и модель может предлагать пользователям наиболее подходящие варианты. - Генетические алгоритмы:
В биоинформатике модели могут использовать списки для оптимизации решений, например, для поиска наилучших комбинаций генов или молекул. - Обработка естественного языка:
В задачах, связанных с текстом, список из 1000 слов может использоваться для создания векторов слов, которые затем могут быть использованы в моделях для анализа тональности, классификации текстов и т.д.
Комбинаторные аспекты:
С точки зрения комбинаторики, если у вас есть 1000 элементов, количество возможных подмножеств (или комбинаций) этих элементов будет равно 21000, что является астрономическим числом. Это подчеркивает сложность и разнообразие возможных решений и взаимодействий, которые могут возникнуть в системах, основанных на таких больших наборах данных.
Работа с большими списками данных требует эффективных алгоритмов и моделей, которые могут обрабатывать и анализировать данные, извлекая из них полезную информацию.
Создание алгоритма для обработки текста из модулей списков фраз по 1000 строк, используя 20 таких модулей данных с ИИ, может быть организовано в несколько этапов. Ниже представлен общий подход к разработке такого алгоритма:
*
когда мы копируем чужие решения -
так мы перестаем думать головой
что очень плохо ..
*
Алгоритм обработки текста
- Инициализация и загрузка данных:
Загрузите 20 модулей данных, каждый из которых содержит 1000 строк фраз. Это может быть сделано с использованием библиотек для работы с данными, таких как pandas в Python. - Предобработка текста:
Для каждого модуля выполните предобработку текста:
Удалите лишние пробелы.
Приведите текст к нижнему регистру.
Удалите пунктуацию и специальные символы.
Разделите текст на токены (слова или фразы). - Анализ фраз:
Примените модели ИИ к каждой фразе в модулях для выполнения различных задач, таких как:
Классификация фраз (например, положительные или отрицательные).
Извлечение ключевых слов или фраз.
Определение тональности.
Генерация новых фраз на основе существующих. - Объединение результатов:
Соберите результаты анализа из всех 20 модулей.
Это может включать в себя:
Сохранение классификаций.
Сохранение извлеченных ключевых слов.
Сохранение оценок тональности. - Агрегация и визуализация:
Объедините данные из всех модулей для дальнейшего анализа. Это может включать в себя:
Создание сводных таблиц.
Визуализацию данных с помощью графиков и диаграмм (например, с использованием библиотеки matplotlib или seaborn). - Вывод результатов:
Подготовьте отчет или вывод, который включает в себя:
Основные выводы из анализа.
Рекомендации на основе полученных данных.

Вот пример кода на Питоне, который иллюстрирует основные шаги алгоритма:
import pandas as pd
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# Шаг 1: Загрузка данных modules = [pd.read_csv(f'module_{i}.csv') for i in range(1, 21)]
# Шаг 2: Предобработка текста def preprocess(text):
text = text.lower() # Приведение к нижнему регистру text = re.sub(r'\W', ' ', text) # Удаление пунктуации return text
for i in range(20):
modules[i]['processed'] = modules[i]['phrase'].apply(preprocess)
# Шаг 3: Анализ фраз (пример классификации) vectorizer = CountVectorizer()
X = vectorizer.fit_transform(pd.concat([module['processed'] for module in modules]))
# Обучение модели (пример) y = [1 if i % 2 == 0 else 0 for i in range(X.shape[0])] # Пример меток model = MultinomialNB()
model.fit(X, y)
# Шаг 4: Применение модели и сбор результатов predictions = model.predict(X)
# Шаг 5: Агрегация и визуализация results = pd.DataFrame({
'phrase': pd.concat([module['phrase'] for module in modules]),
'prediction': predictions
})
# Шаг 6: Вывод результатов print(results.groupby('prediction').count())Найти еще
Этот алгоритм можно адаптировать и расширять в зависимости от конкретных требований и задач. Вы можете использовать более сложные модели ИИ, такие как трансформеры, для более глубокого анализа текста, а также добавлять дополнительные шаги предобработки и анализа в зависимости от ваших нужд.