Задача:
Реализуйте EM-алгоритм (Expectation-Maximization) для решения задачи кластеризации данных.
Алгоритм должен:
- Определять параметры распределения для каждого кластера (веса, средние значения, ковариационные матрицы).
- Вычислять вероятности принадлежности каждой точки данных к каждому кластеру.
- Обучаться итеративно, уточняя параметры кластеров на основе результатов предыдущих шагов.
------------
Для начала немного теории (если вы ее уже знаете, можете пролистать ее и переходить к разбору кода).
EM-алгоритм (Expectation-Maximization) — это итеративный метод для нахождения максимального правдоподобия в моделях с ненаблюдаемыми (скрытыми) переменными. Он широко используется в статистике и машинном обучении для задач, таких как кластеризация, оценка параметров смеси распределений и другие.
Основные шаги EM-алгоритма
- Инициализация: Начальные значения параметров модели выбираются случайным образом или на основе некоторых эвристик.
- E-шаг (Expectation Step): Оценка ожидаемого значения скрытых переменных на основе текущих параметров модели.
- M-шаг (Maximization Step): Максимизация функции правдоподобия по отношению к параметрам модели, используя ожидаемые значения скрытых переменных из E-шага.
- Повторение: Шаги E и M повторяются до сходимости (например, до тех пор, пока изменения в параметрах модели не станут меньше заданного порога).
Теоретические основы
Формулировка задачи
Предположим, у нас есть набор наблюдаемых данных X и скрытых переменных Z. Мы хотим оценить параметры модели θ, которые максимизируют функцию правдоподобия L(θ;X,Z).
E-шаг
На E-шаге мы вычисляем ожидаемое значение функции правдоподобия по отношению к распределению скрытых переменных Z, условному на наблюдаемые данные X и текущие параметры θ:

M-шаг
На M-шаге мы максимизируем функцию Q(θ∣θ(t)) по отношению к параметрам θ:
Пример: Гауссовы смеси
Рассмотрим пример использования EM-алгоритма для оценки параметров гауссовой смеси.
Модель
Предположим, что данные X генерируются смесью K гауссовых распределений:
E-шаг
На E-шаге мы вычисляем вероятности принадлежности каждого объекта xi к каждому кластеру k:
M-шаг
На M-шаге мы обновляем параметры модели:
Преимущества и недостатки
Преимущества
- Простота реализации: EM-алгоритм относительно прост в реализации для многих моделей.
- Сходимость: EM-алгоритм гарантированно сходится к локальному максимуму функции правдоподобия.
Недостатки
- Локальные максимумы: EM-алгоритм может сходиться к локальным максимумам, а не глобальному.
- Чувствительность к начальным условиям: Результат может сильно зависеть от начальных значений параметров.
- Вычислительная сложность: Для больших наборов данных и сложных моделей EM-алгоритм может быть вычислительно затратным.
----------------------------------
Напишем код, который реализует EM-алгоритм (Expectation-Maximization) для кластеризации данных, используя модель смешивания гауссиан (Gaussian Mixture Model, GMM).
1. Общий контекст
EM-алгоритм применяется для разбиения данных на кластеры, когда нет информации о принадлежности объектов к классам. В данном решении создается синтетический набор данных с тремя классами, которые моделируются как гауссовские распределения с разными параметрами. Бывают аналогичные задачи, в которых данные нужно получить из готового датасета.
Импортируем необходимые библиотеки:
2. Основные функции
E-шаг (Expectation Step) — e_step
Задача: вычислить вероятности принадлежности объектов к каждому кластеру.
- Входные параметры:x: матрица данных (объекты и их признаки).
k: количество кластеров.
m: число признаков.
n: число объектов.
w: массив весов кластеров.
mu: массив математических ожиданий (центров кластеров).
sigma: массив ковариационных матриц кластеров. - Суть: Вычисляются апостериорные вероятности (вероятности принадлежности объекта к кластеру).
Используются формулы многомерного нормального распределения.
Результат — матрица вероятностей proba_xi размером (k, n), где каждая строка соответствует вероятностям для определенного кластера.
Код:
Определение нового распределения объектов по кластерам — x_new
Задача: определить для каждого объекта, к какому кластеру он принадлежит с наибольшей вероятностью.
- Суть: Для каждого объекта выбирается кластер с максимальной вероятностью.
Возвращается список индексов объектов для каждого кластера и массив предсказанных меток кластеров.
Код:
M-шаг (Maximization Step) — m_step
Задача: обновить параметры кластеров (веса, математические ожидания и ковариационные матрицы).
- Входные параметры:x: матрица данных.
proba_xi: матрица вероятностей принадлежности объектов к кластерам.
n_clusters: количество кластеров. - Суть: Вычисляются новые веса кластеров w_new как средние вероятности по объектам.
Обновляются центры кластеров mu_new как средние значения объектов с учетом вероятностей.
Ковариационные матрицы sigma_new обновляются с учетом дисперсий объектов в каждом кластере.
Код:
3. Параметры задачи
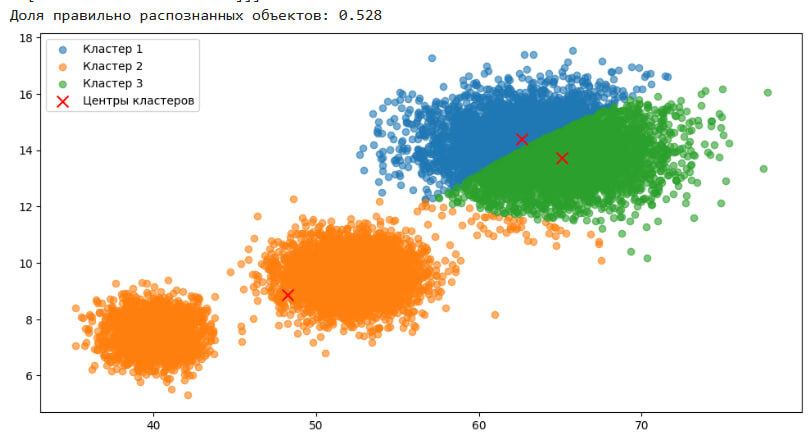
- Данные моделируются как три двумерных нормальных распределения: Первый кластер: центр (64,14), стандартные отклонения (3.5,1).
Второй кластер: центр (52,9.5), стандартные отклонения (2,0.7).
Третий кластер: центр (40,7.5), стандартные отклонения (1.5,0.6). - Создаются N=12 000 объектов с истинными метками.
4. Инициализация
- Вес каждого кластера w=1 / k
- Центры кластеров mu выбираются случайно из объектов.
- Ковариационные матрицы sigma для всех кластеров изначально одинаковы и равны ковариации всего набора данных.
5. Цикл EM-алгоритма
Цикл выполняется 15 итераций:
- E-шаг: Вычисляются вероятности принадлежности объектов к кластерам (proba_xi).
- M-шаг: Обновляются параметры кластеров (w, mu, sigma).
- Определяется кластер для каждого объекта на основе вероятностей.
- Выводятся: Математические ожидания кластеров.
Ковариационные матрицы.
Точность классификации (accuracy_score) относительно истинных меток. - Визуализация: Объекты раскрашиваются по кластерам, красным отмечаются центры кластеров.
6. Результат
- Алгоритм итеративно улучшает параметры кластеров, максимизируя правдоподобие данных.
- На каждом шаге можно наблюдать улучшение точности распознавания кластеров.
- После завершения алгоритма кластеры визуально хорошо разделены.
7. Зачем это нужно (в теории)?
- Кластеризация: Разбиение данных на группы, если метки классов неизвестны.
- Пример применения: Анализ клиентов, сегментация рынка, обнаружение аномалий.
- EM-алгоритм: Удобен для сложных моделей, например, в задачах, где объекты принадлежат нескольким классам с различной вероятностью.
Весь код можно протестировать и скачать в Colab: