
Когда мы говорим об обработке длинных последовательностей — например, языковых текстов или временных рядов длиной в миллионы точек — традиционные трансформеры натыкаются на проблему квадратичной сложности и ограниченного «окна» контекста. Недавняя статья «Titans: Learning to Memorize at Test Time» предлагает новую архитектуру, которая совмещает «короткую память» (attention) на небольшой сегмент с «длинной памятью», способной обучаться «на лету» (inference). Ниже разбираюсь, как это работает и чем «Titans» отличаются от уже известных линейных рекуррентных моделей и трансформеров.
Почему рекуррентность снова в моде?
Все знают, что трансформеры (в чистом виде) имеют две большие проблемы при работе с очень длинным контекстом:
- 🚀 Квадратичная стоимость при увеличении длины входа.
- 🚀 Жёсткое ограничение на «окно внимания»: выйдя за 2–4К токенов, модель вынуждена «забывать» остальное.
Чтобы расширить возможности, появлялись модификации типа линейных трансформеров, различных SSM (State-Space Models), или гибридов, где куски последовательности обрабатываются порциями. Но все они либо теряют точность на экстремально больших контекстах, либо работают со слишком простой «сжатой» памятью (вектор или небольшая матрица), не умея эффективно «забывать» неактуальное и «запоминать» важное.
Авторы Titans предлагают относиться к вниманию (attention) как к короткой памяти, которая идеально «захватывает» текущий отрезок, а к специальному нейронному модулю — как к долгой памяти, которая учится хранить информацию из далеко «ушедшего» контекста. Причём эта долгая память обучается прямо на этапе инференса, причём тренируется «онлайн».
Как устроена «нейронная долгая память»?
🏺 Сюрприз как триггер
Авторы вдохновляются идеей, что в человеческом мозге запоминается прежде всего «удивляющая» информация. В модели Titans «сюрприз» токена измеряется градиентом ошибки модели относительно этого входа. Если некая часть входа сильно влияет на обновление весов, значит она «новая/важная» — её нужно запомнить.
🏺 Моментум и забывание
Чтобы модель не «застревала» на одной «сюрпризной» точке, вводятся:
- Импульс (momentum): хранит «накопленную неожиданность» из прошлых шагов.
- Механизм забывания (weight decay/gate): если модель «переполняется» или контекст сменился, мы частично стираем старые записи.
Формально, нейронная память MM обновляется по формулам вида:
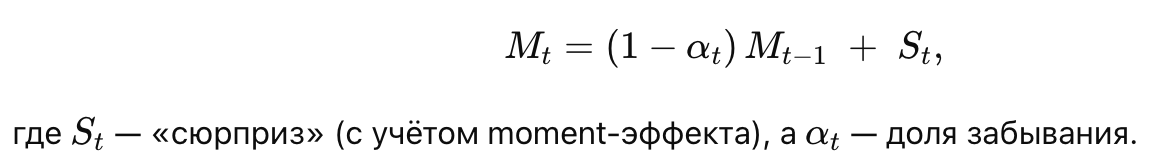
🏺 Глубокая память
Вместо простого матричного «хранилища» (как в некоторых линейных рекуррентных моделях), Titans используют многослойную сеть (MLP), способную хранить более сложные зависимости. Это критично, если мы хотим запоминать реально сложные паттерны, например, в языке или биологических данных.
Архитектура Titans: три «ветви»
В статье предлагается общий фреймворк Titans, где есть:
- 🧠 Короткая память через attention (ограниченное окно).
- 🧠 Долгая память (Neural Memory Module, описанный выше).
- 🧠 Постоянная память (Persistent memory) — набор специальных параметров, не зависящих от входа (что-то вроде «вшитых знаний» о задаче).
Но «склеивать» эти модули можно по-разному. Авторы приводят три варианта:
- Память как контекст - Memory as a Context (MAC)
Используется «скользящее окно» по сегментам. К текущему сегменту (через attention) подтягивается «длинная память» и «параметры состояния (persist)». Это даёт модели точное локальное внимание, плюс контекст из давнего прошлого, уже закодированный в памяти (Memory). - Память как шлюз - Memory as a Gate (MAG)
Длинная память обновляется в одной ветви, а короткая память через механизм внимания с прокручивающимся окном (sliding-window attention) — в другой. В конце есть «шлюз», совмещающий их выходы. - Память как слой - Memory as a Layer (MAL)
Длинная память идёт как одна из слоёв модели перед или после внимания (attention). Это вариант, похожий на гибриды типа RetNet + recurrent block, но здесь рекуррентный блок — наша «глубокая память».
Эксперименты показывают, что первые два подхода (MAC/MAG) лучше работают в задачах с «пропажей иголки в стоге» (needle-in-a-haystack) и длинном контексте. А третий вариант (MAL) даёт более высокую скорость обучения, хотя чуть уступает по качеству.
Результаты: длинные тексты, NIAH, временные ряды
По данным авторов, Titans:
- 🔑 В языковом моделировании на длинных контекстах (до 2 млн токенов) обгоняет как обычные трансформеры (сравнимой размерности), так и современные линейные рекуррентные модели (Mamba, DeltaNet, Gated DeltaNet и т.д.).
- 🔑 В задачах типа «пропажей иголки в стоге» (где нужная информация спрятана в огромном «мусорном» тексте) Titans существенно превосходит GPT4 и Llama3.1 (8B) с Retrieval-Augmented Generation (RAG). При этом Titans имеют меньше параметров!
- 🔑 Для временных рядов (ETT, ECL, Traffic, Weather) рекуррентный модуль памяти показывает лучшие или сравнимые результаты с SSM-моделями вроде Mamba2 и с трансформерами.
- 🔑 В геномике на GenomicsBenchmarks (например, классификация промоторов) модель Titans (в режиме без «короткой памяти» — только наш LMM-модуль) даёт конкурентные результаты с DNA-ориентированными архитектурами.
Личное мнение: почему это важно?
По сути, Titans возвращает нам идею «рекуррентности», но в совершенно новом виде:
- 💡 Рекуррентные веса теперь реально могут «учиться» во время инференса, а не только на этапе обучения.
- 💡 «Сюрприз» + «забывание» + «глубина» в модуле памяти выглядят логичным шагом вперёд (ведь мозг, действительно, не хранит весь поток событий: важное мы запоминаем сразу «глубоко»).
Мне кажется особенно интересным то, что модель умеет «мета-обучаться» на лету и потенциально может быстро адаптироваться к данным, которые не видела при обучении. Да, это требует «расшаривания» части весов для «онлайн»-тренировки, но авторы показывают, как это параллелить на GPU/TPU (в стиле mini-batch и матричных операций), чтобы это не слишком замедляло процесс.
🔗 Полная статья на arXiv:
https://arxiv.org/abs/2501.00663
Вывод
«Titans» фактически предлагают свежий взгляд на рекуррентные нейронные сети, сочетая их с классическим вниманием (attention), но при этом делая «длинную память» нелинейной и обучающейся «на лету» через механизм «удивления» и «забывания». Эксперименты впечатляют: модель успешно масштабируется для гигантских контекстов, превосходит аналогичные гибриды и даже очень крупные LLM-решения на задачах вроде BABILong. Возможно, это начало новой эры архитектур, где рекуррентный «recurrent» становится не «старомодным», а наоборот — сверхэффективным при экстремально длинных последовательностях.