
Для проверки состояния диска с помощью SMART можно воспользоваться smartctl (входит в пакет smartmontools), важно знать ключевые команды и как интерпретировать вывод.
1. Установка smartctl
- Debian/Ubuntu:
sudo apt update && sudo apt install smartmontools
- CentOS/RHEL:
sudo yum install smartmontools
- Arch Linux:
sudo pacman -S smartmontools
2. Определение устройства
Перед началом определите, как ваш диск отображается в системе:
lsblk
Диск будет показан как /dev/sdX (например, /dev/sda).
3. Проверка SMART-поддержки
Убедитесь, что диск поддерживает SMART:
sudo smartctl -i /dev/sdX
Ключевая информация:"SMART support is: Enabled" — SMART поддерживается и включён.
Если не включён, активируйте:
sudo smartctl -s on /dev/sdX
4. Обзор всех SMART-атрибутов
Для анализа текущего состояния атрибутов:
sudo smartctl -A /dev/sdX
Важные параметры:
Reallocated_Sector_Ct: Количество переназначенных секторов (нормальное значение = 0).
Current_Pending_Sector: Секторы, ожидающие переназначения (нормальное значение = 0).
Raw_Read_Error_Rate: Ошибки чтения (высокие значения могут указывать на проблемы).
Power_On_Hours: Общее время работы диска (показывает износ).
Temperature_Celsius: Температура диска (идеально 30–50°C).
5. Самодиагностика диска
Диск может выполнять внутренние тесты:
Запуск короткого теста
sudo smartctl -t short /dev/sdX
- Короткий тест занимает несколько минут.
Чтобы проверить результат:
sudo smartctl -l selftest /dev/sdX
Запуск расширенного (длительного) теста
sudo smartctl -t long /dev/sdX
- Может занимать несколько часов.
- Проверяет всю поверхность диска на ошибки.
6. Просмотр журнала тестов
История всех выполненных тестов:
sudo smartctl -l selftest /dev/sdX
- Статусы тестов:"Completed without error" — всё в порядке.
"Aborted" — тест прерван (например, из-за перезагрузки).
"Failing LBA" — указаны проблемные сектора.
7. Проверка ошибок диска
Для просмотра ошибок ввода/вывода:
sudo smartctl -l error /dev/sdX
- Обратите внимание на записи о сбоях. Проблемы с чтением/записью указывают на возможный отказ диска.
8. Проверка общего состояния
Чтобы быстро узнать статус SMART:
sudo smartctl -H /dev/sdX
- Возможные результаты:"PASSED" — диск в порядке.
"FAILED" — есть серьёзные проблемы, резервируйте данные.
9. Пример полного отчёта
Для получения полной информации о диске:
sudo smartctl -x /dev/sdX
Этот вывод содержит:
- SMART-атрибуты.
- Журналы ошибок.
- Детали прошивки и модели.
10. Интерпретация важных атрибутов
Вот краткая таблица важных SMART-атрибутов:
Reallocated_Sector_Ct. Переназначенные сектора - 0
Current_Pending_Sector. Сектора, ожидающие переназначения - 0
Raw_Read_Error_Rate. Частота ошибок чтения. Зависит от производителя
UDMA_CRC_Error_Count. Ошибки передачи данных через интерфейс - 0
Power_On_Hours. Общее время работы диска. Зависит от модели.
Temperature_Celsius. Температура. Больше 50°C может говорить о перегреве.
Если SMART (Self-Monitoring, Analysis, and Reporting Technology) диска показывает Pre-fail в атрибутах, это означает, что определённые параметры, связанные с состоянием диска, могут указывать на потенциальный риск отказа устройства в будущем.
Что значит "Pre-fail"?
Тип атрибута: Некоторые SMART-атрибуты относятся к категории "Pre-fail". Это значит, что их ухудшение может предшествовать отказу диска.
Это не обязательно означает, что диск уже неисправен, но является предупреждением о возникающих проблемах.
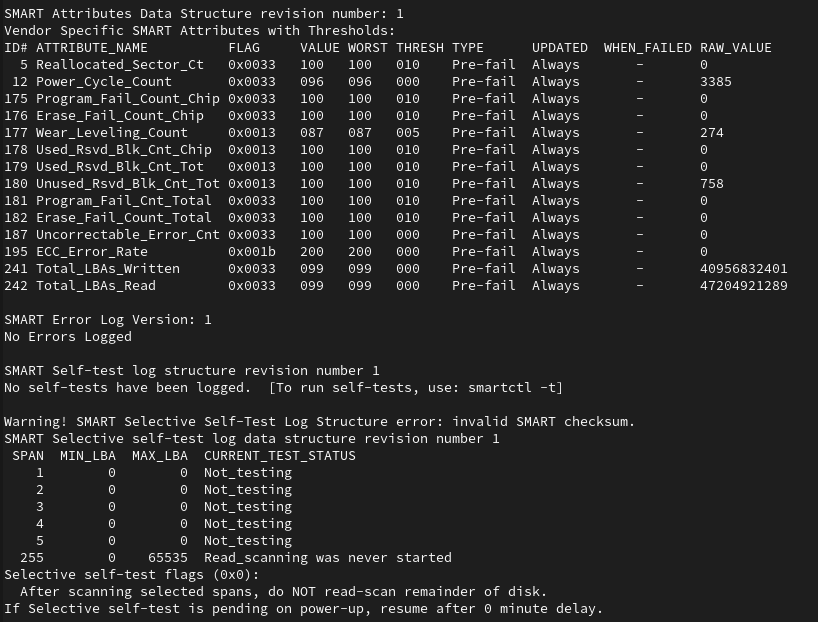
Состояние атрибута: Если значение атрибута находится на уровне или ниже порогового значения (Threshold), это указывает на высокую вероятность отказа диска. Наиболее популярные последствия отказа могут быть в виде невозможности загрузиться, либо потери данных (доступа к диску).
Что делать?
- Резервное копирование: Если диск показывает тип Pre-fail с превышением пороговых значений, срочно сделайте резервную копию всех данных. Это первый и самый важный шаг.
- Мониторинг состояния: Используйте утилиты для анализа SMART (например, CrystalDiskInfo, Victoria, или встроенные команды в Linux, такие как smartctl).
Проверьте, какие именно атрибуты вызывают тревогу, и наблюдайте за изменениями. - Тестирование диска: Выполните полное сканирование поверхности и тесты, предоставляемые производителем (например, SeaTools для Seagate, WD Data Lifeguard для Western Digital).
- Замена диска: Если тенденция ухудшения сохраняется, рекомендуется заменить диск, особенно если он используется в критически важных системах.
- Продление срока службы: Если данные перенесены, а диск всё ещё работает, его можно использовать для менее критичных задач (например, хранения временных данных или не критичных данных, торрентов, различного мусора, который не жалко потерять).