Языковая модель — это алгоритм, который анализирует текст, понимает его контекст, обрабатывает и генерирует новые тексты. В его основе лежат нелинейные и вероятностные функции, с помощью которых модель предсказывает, какое слово может быть следующим, — рассчитывает вероятность для каждого из возможных слов.
В основе языковых моделей, как правило, лежат нейронные сети, обученные на большом количестве текстовой информации. Главная задача языковой модели — «понимать» текст по закономерностям в данных и генерировать осмысленный ответ. Благодаря тонкой настройке ее можно использовать и для других задач. Например, для классификации или NER (Named Entity Recognition) — распознавания сущностей в тексте.
Вот несколько примеров, что можно делать с помощью языковых моделей:
- анализировать тональность текстов, например отзывов в интернет-магазинах;
- сортировать новости по категориям, к примеру «Финансы» или «Общество»;
- обнаруживать и фильтровать спам;
- находить в тексте ключевые мысли, например формировать краткое содержание научной статьи;
- выделять в тексте имена, адреса, названия товаров и цен — скажем, чтобы автоматически наполнить базы данных и др.
Кроме того, языковые модели могут самостоятельно генерировать осмысленные тексты в ответ на запрос. Например, уже существовали случаи, когда модель генерировала сюжет книги или текст дипломной работы.
LLM
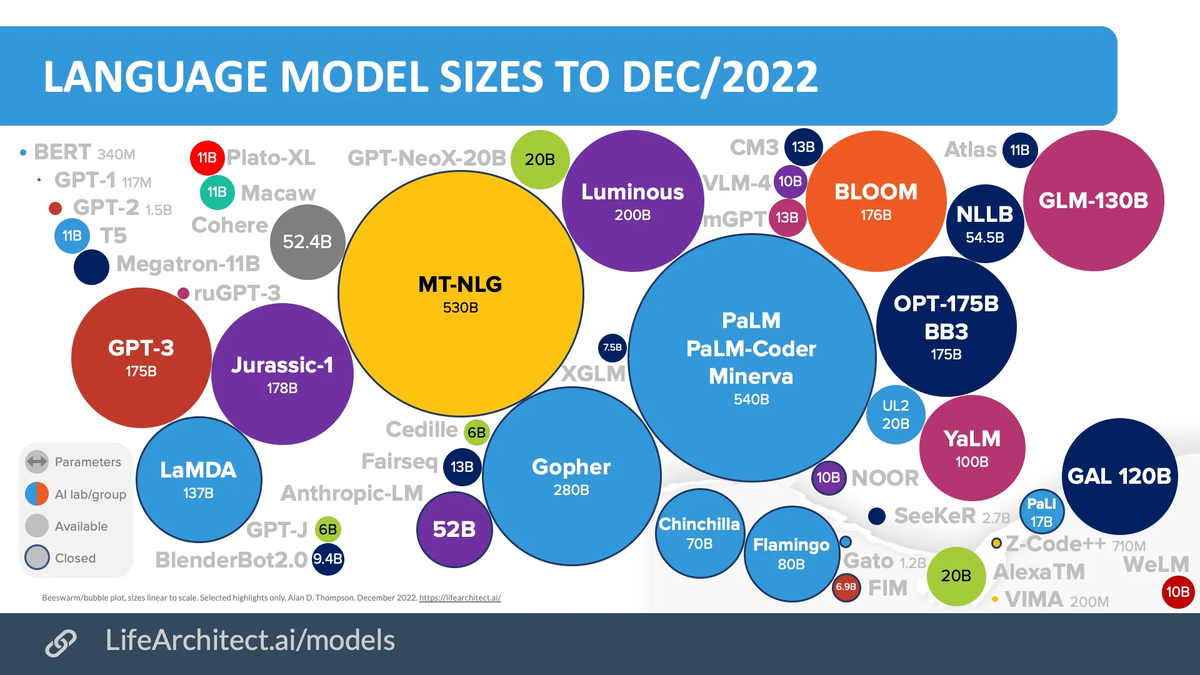
Отдельным классом языковых моделей можно выделить LLM (large language model), или большие языковые модели. К ним относятся популярные сегодня типы моделей GPT и BERT. Среди характерных особенностей LLM:
- очень большой размер — в таких моделях используется более миллиарда параметров. В самых известных LLM их сотни миллиардов;
- обучение на огромном количестве входных данных — к примеру, 50 миллиардов веб-страниц из базы Common Crawl;
- большие вычислительные ресурсы, необходимые для создания и обучения такой модели;
- способность обрабатывать входные данные параллельно, а не последовательно.
Благодаря своим размерам и особенностям архитектуры LLM отличаются большей гибкостью. Одну и ту же модель можно использовать и для генерации кода, и для имитации живого диалога или придумывания историй. Яркий пример — всем известная ChatGPT.
Трансформер
Структура зависит от того, какая математическая модель использовалась при ее создании. Невозможно говорить о какой-то единой структуре — в разные годы применяли разные подходы. Первые языковые модели были статистическими, основанными на вероятностном алгоритме цепей Маркова, более поздние имели в своей основе рекуррентные нейронные сети (RNN). Это вид нейронных сетей, предназначенный для обработки последовательных данных.
Современные большие языковые модели, такие как BERT или GPT, основаны на структуре под названием «трансформер». Такая архитектура оказалась самой эффективной и давала лучшие результаты, чем статистические или RNN-модели.
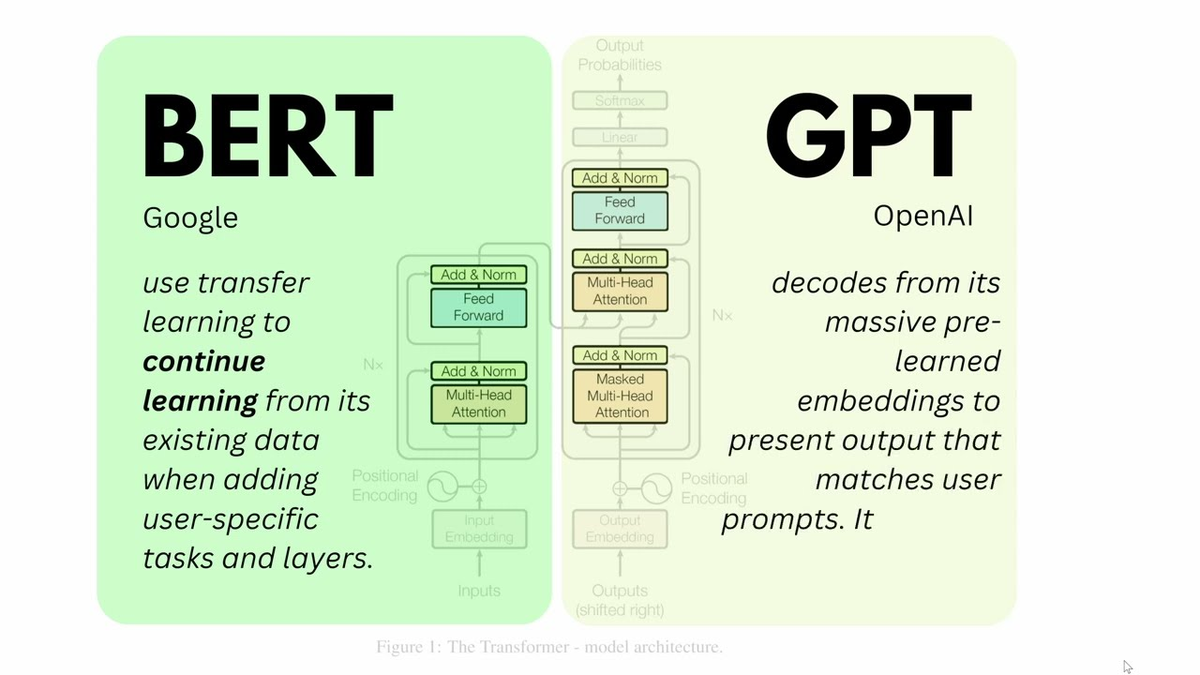
Трансформер — это математическая модель, которая состоит из двух частей — энкодера и декодера:
- Энкодер кодирует входной текст, преобразуя его в вектор чисел, который максимально точно описывает исходные данные.
- Декодер преобразует числовой вектор обратно в текст или другое смысловое выражение, которое требуется от модели. Например, это может быть категория, к которой относится входной текст, — художественная литература, научная статья и так далее.
Внутренний вектор, с которым работает модель, описывает связи между исходными данными и позволяет модели обрабатывать и генерировать текст.
Работа трансформера основана на механизме внимания (attention). Это значит, что слова в тексте рассматриваются не сами по себе, а в контексте: он зависит от слов вокруг, положения слова в предложении и частоты сочетаний конкретных слов. Благодаря этому механизму языковая модель способна глубоко анализировать текст и распознавать его смысл так же, как человек. По сути, всё просто - выделяют слова, на которые нужно обратить внимание при переводе, что актуально, если текст или предложение слишком длинные. Используется функция внимания как скалярное произведение параметров каждого слова. Ему противопоставляется вектор внимания.
Самовнимание (self attention) - механизм внимания, где на входе и на выходе одни и те же данные. Нужно для согласования слов в предложении - несколько раз перечитывается генерация текста. Актуально было для систем автоматического перевода. В рекуррентных и одномерных свёрточных нейронных сетях.
В трансформерах же стал использоваться только механизм внимания (статья 2017 Attention is all you need).
Внутри энкодера и декодера находятся разные комбинации слоев внимания и нейронных сетей прямого распространения.
Слои внимания определяют контекст и связи между токенами. В их основе лежат три матрицы:
- Матрица запроса (Q) анализирует слово в контексте других слов.
- Матрица ключевых значений (K) проверяет, как то или иное слово относится к входному запросу.
- Матрица значений (V) определяет, что означает слово не в контексте предложения, а для языка в целом.
На самом деле, есть трансформеры с полной архитектурой, как представлено, и неполной. См. ниже кодировщик (функция - восстановление предложения) BERT и декодировщик (функция -предсказание следующего слова в предложение ) GPT. Полная архитектура у T5 и BART, их функция - преобразование одной последовательности в другую.
Нейронные сети прямого распространения расположены после слоев внимания. Они добавляют к данным нелинейные преобразования — превращают вычисленные данные для каждого слова в N-мерный вектор.
Между слоями есть связи, которые помогают учитывать данные с предыдущих слоев. Это помогает не потерять важную информацию при прохождении какого-либо слоя.
Перед загрузкой в энкодер входные данные проходят через слои токенизации и эмбеддинга.
- Токенизация — это процесс, при котором каждому слову или знаку во входном тексте присваивается свой уникальный ID. Модель получает на вход именно набор ID, а не «сырой» текст.
- Эмбеддинг — превращение набора ID в смысловые векторы на первом слое языковой модели. Сами по себе поступающие в модель ID только сопоставляют со словами какие-то числа. Эмбеддинг преобразует их в вектор таким образом, чтобы схожие по смыслу слова находились ближе друг к другу в векторном пространстве.
Отдельный вид эмбеддингов — позиционные. Это слои, которые определяют положение слова в смысловом векторе на основе его позиции в предложении. Они полезны в ситуациях, когда слово меняет смысл в зависимости от его расположения.
Принцип работы языковой модели
Два самых известных семейства моделей, например, кодировщики - BERT (Deep Bidirectional Transformers for Languages Understanding)и декодировщики - GPT (Generative pre-trained transformer), работают по одному принципу: предсказывают скрытое слово, наиболее вероятное в заданном контексте.
- Входной текст проходит токенизацию и эмбеддинг.
- После этого загружается в энкодер, где по очереди пропускается через слои внимания и полносвязные слои. На этом этапе входные данные анализируют и выделяют важные токены.
- Из энкодера данные переходят в декодер. Тот получает собранную энкодером информацию о контексте и на ее основе генерирует новые токены — предсказывает на основе предыдущих.
- На выходе трансформер выдает набор вероятностей, которые преобразуются в слова.
Разница между BERT и GPT в особенностях обработки. В первой основную задачу выполняют энкодеры, вторая построена на базе декодеров. На практике это означает следующее:
- BERT предсказывает слово внутри предложения и учитывает все окружающие слова до и после скрытого. Ее чаще используют в задачах поиска пар, классификации, трансформации имеющихся текстовых данных.
- GPT всегда предсказывает следующее слово и обращает внимание только на предыдущие слова в предложении. На выходе получается набор вероятностей для каждого скрытого слова. Модель удобнее использовать для генерации новых текстов с нуля.
Как обучают языковые модели
1. Подготовка датасета. Для обучения языковых моделей используют огромные текстовые базы данных.
Далее при очистке из огромного массива информации удаляют персональные данные, запрещенные или некорректные сведения.
Очищенные данные готовят к загрузке: токенизируют, а в случае с BERT — заменяют часть слов в фразах на маску. Модель должна научиться предсказывать, какие слова находятся вместо маски. После этого датасет разделяют на обучающий, валидационный и тестовый.
2. Загрузка в модель. Подготовленные данные передают в модель для обучения. Та поочередно тренируется на каждой из частей датасета:
- на обучающей. Эта выборка — набор примеров, которые должны показать модели распределение связей между словами. Когда модель обучается на этой выборке, она корректирует векторы и формирует собственное «представление» о взаимосвязях между словами;
- на валидационной. Эту часть датасета используют после прохождения обучающей выборки — сравнивают, насколько изменилась точность работы модели в зависимости от этапа обучения. Валидацию могут проводить несколько раз и проверяют, в какой момент модель выдает более качественные результаты;
- на тестовой. Тестовые данные нужны уже после завершения обучения и валидации. Их используют, чтобы окончательно протестировать уже обученную модель. Иногда такие наборы данных специально составляют из примеров, которых нет в обучающей и валидационной выборке, — чтобы посмотреть, как поведет себя модель при работе с незнакомыми словами.
Методы обучения также могут различаться.
Среди основных выделяют:
- Предварительное обучение на больших текстовых данных. Его используют, чтобы обучить модель понимать язык в целом, а не какие-то специфические темы. Например, задача разработчика — обучить модель, чтобы она понимала статьи по генетике на русском языке. Но качественных статей на эту тему не очень много, и этого количества не хватит для обучения крупной модели. Поэтому сначала модель обучается на «обычных» текстовых данных разного формата, чтобы потом дообучиться на специфических.
- Тонкая настройка. Сюда входит дообучение существующей модели под конкретную задачу. Например, чат-бота, уже знакомого с языком в целом, дообучают, чтобы он понимал молодежный сленг. Или алгоритм тренируют понимать и анализировать отзывы на сайте.
- Prompt-инженерия. Так дообучают и настраивают уже работающие модели — обучение происходит на основе запросов. Инструкции для модели формулируют так, чтобы та выдавала желаемый результат. Например, подают на вход данные в определенном формате, для которого модель выдаст более четкий ответ.
- Аугментация данных. Это вариант дообучения с помощью искусственно составленного набора данных. Например, модели для биологических задач не просто подают на вход тексты, а предварительно обогащают их названиями генов и молекул. Это учит модель распознавать и понимать специфические термины.
- Обучение с подкреплением. С помощью этого метода модель обучают генерировать текст на основе вознаграждений. Модель получает «подкрепление», если результат выглядит определенным образом. Это помогает, например, настраивать диалоговые модели, чтобы их речь звучала более естественно.
Вот в каких сферах чаще всего обрабатывают естественный язык:
- Наука. Языковые модели генерируют абстракты — краткие содержания научных статей, которые публикуются перед основным текстом. Также модели помогают в поиске научных текстов, классификации статей, обработке результатов исследований и многом другом.
- Медицина. Модели используют для поиска специализированных текстов, анализа симптомов, а иногда — для диагностики. Например, в 2018 году в Пенсильвании разработали языковую модель, которая распознает у людей депрессию по их постам в соцсетях. Точность составила около 70% и зависела от того, насколько активно человек вел соцсеть.
- Создание цифровых сервисов. С помощью языковых моделей работает огромное количество IT-решений: от поисковых систем и переводчиков до чат-ботов в соцсетях. Например, крупные компании создают ботов-помощников с собственным характером и манерой речи.
- Маркетинг. Языковые модели используют для генерации контент-планов, идей для статей и сторис, рекламных постов и баннеров. С их помощью придумывают слоганы и даже названия для новых брендов.