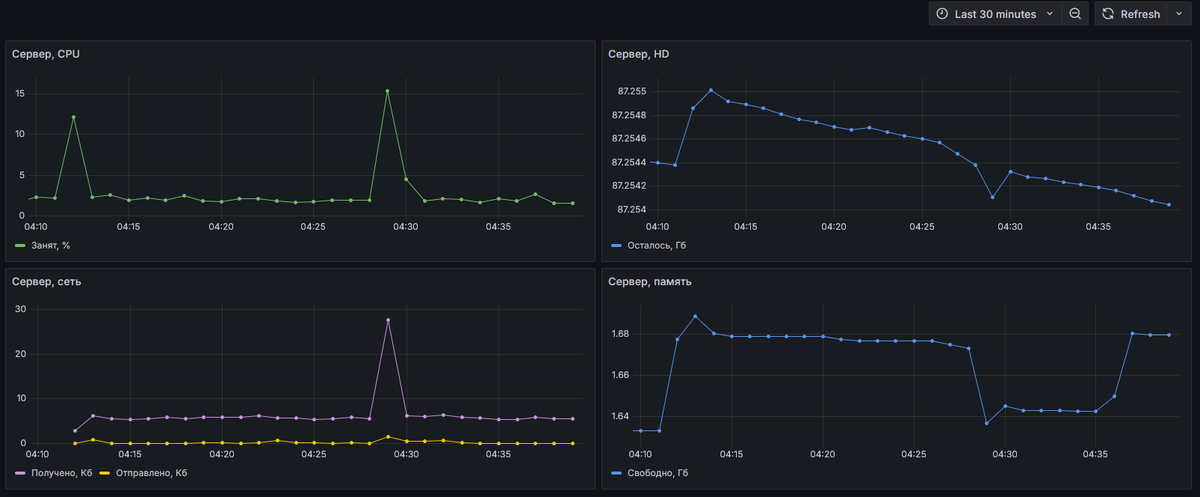
Собственно, поглядите - это именно то, что я и хотел видеть в статистике по серверу разработки и тестирования. Нагрузка на процессор, что там с трафиком сети, сколько осталось места на диске, и насколько используется оперативная память (точнее, сколько ее там осталось).
Теперь более подробно. Во-первых, добавлен новый образ в Docker Compose:
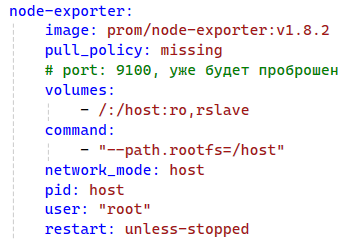
node-exporter:
image: prom/node-exporter:v1.8.2
pull_policy: missing
# port: 9100, уже будет проброшен
volumes:
- /:/host:ro,rslave
command:
- "--path.rootfs=/host"
network_mode: host
pid: host
user: "root"
restart: unless-stopped
Внимание! Node Exporter работает в контейнере, но собирает показатели основной системы, за пределами контейнера! Для этого и указаны все эти особые настройки. Они взяты из документации по Node Exporter: https://github.com/prometheus/node_exporter/blob/master/README.md
Чтобы не порушить работу сети для остальных контейнеров, пришлось в начале файла compose.yaml добавить еще секцию описания используемой сети:
networks:
monitoring:
driver: bridge
И для всех контейнеров, кроме node-exporter, указать, что они используют эту сеть:
networks:
- monitoring
Например:
В Prometheus после этого была добавлена еще одна секция по сбору данных:
- job_name: 'devandtest_node'
static_configs:
- targets: ['host.docker.internal:9100']
Ладно, перейдем теперь к Grafana. Здесь у нас 4 панели, и они определены следующим образом:
- Сервер, CPU: sum(rate(node_cpu_seconds_total{mode!="idle"}[1m])) * 100. Функция rate работет здесь не так, как с Loki. Она считает посекундную дельту значения указанной метрики на указанном (1m) отрезке времени. node_cpu_seconds_total выдает прирост суммы времени процессора, отработанного в определенном режиме, за секунду. В общем, достаточно умножить сумму от rate на 100, и получить процент занятого времени (поскольку в выборке мы исключили режим idle)
- Сервер, сеть. Для полученных байт, аналогично: rate(node_network_receive_bytes_total{device="enp0s3"}[1m]) / 1024. Для отправленных используем второй запрос, на основе метрики node_network_transmit_bytes_total. Сетевое устройство указано в соответствии с тем, что у нас тут фактически настроено на сервере.
- Сервер, HD. Здесь все намного проще, поскольку идет метрика, которая отображает не нарастающую сумму, а просто текущее значение: avg_over_time(node_filesystem_free_bytes{mountpoint="/"}[1m]) / 1073741824. Делитель в конце - для перевода в гигабайты.
- Сервер, память. Аналогично: avg_over_time(node_memory_MemFree_bytes[1m]) / 1073741824
Как видите, с метриками Prometheus, Grafana может работать без особых проблем. Даже удивительно.