
Индексация страниц
Индексацией называют добавление информации о страницах сайта в базу данных поисковой системы, которую называют «поисковым индексом».
Поисковые системы и владельцы сайтов заинтересованы, чтобы в индексе находились только посадочные страницы (важные страницы с полезным для потенциального покупателя контентом), например, с информацией о выгодах приобретения и преимуществах использования товаров или услуг.
Однако, в индекс с определенным постоянством также попадают страницы без контента, технические страницы, страницы с дублями контента и т.д. Подобные страницы бесполезны для целевых посетителей сайта и их необходимо периодически из индекса удалять.
Страницы с малополезным контентом
Вот основные типы страниц, бесполезных для целевой аудитории:
- Страницы с конфиденциальными данными: с платежной информацией, личные кабинеты пользователей и т.д.
- Страницы без контента (thin content) типа «Спасибо за покупку» или «Ошибка 404» и т.д.
- Технические страницы, например, отвечающие за функционирование админ-панели управления контентом сайта.
- Страницы с дублями контента.
Страницы с дублями контента
Существует более двух десятков различных вариантов страниц с дублями контента.
Вот простой пример их появления:
при создании новой страницы система управления контентом сайта (CMS), например, Tilda или WordPress присваивает ей внутренний системный url адрес с цифровым идентификатором. Одновременно веб-мастер, заполняющий страницу контентом, присваивает ей публичный человеко-понятный url.
Если все пустить на самотёк, то через некоторое время с большой вероятностью обе страницы попадут в индекс:
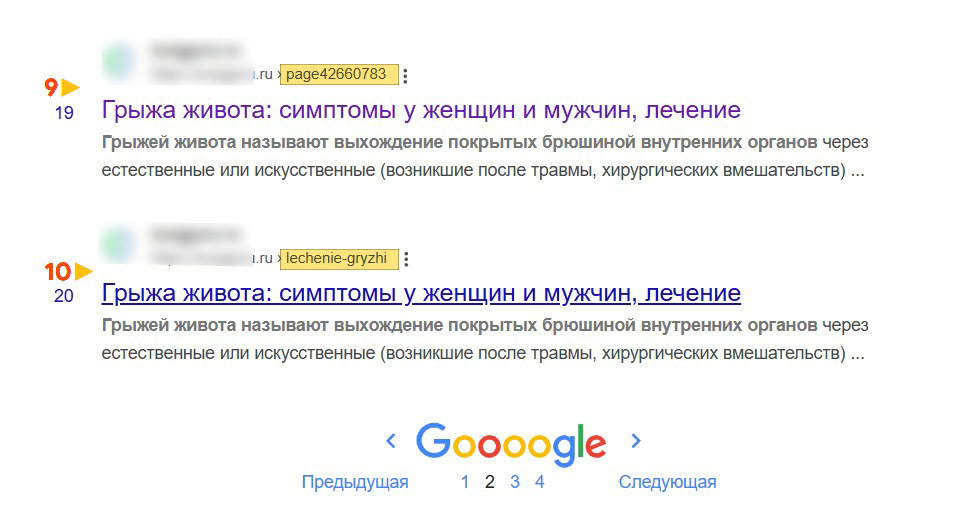
Почему очень важно начинать оптимизацию сайта с закрытия от индексации страниц с дублями контента.
- SEO каннибализация: дубликат конкурирует с основной версией страницы за ТОП поисковой выдачи.
- Снижение рейтинга ранжирования сайта: поисковые системы наказывают сайты, содержащие многочисленные дубликаты контента.
Почему важно контролировать индексацию
Краулер (поисковый бот) периодически посещает сайт, регистрирует изменения контента и обновляет свой индекс, причем время его нахождения на сайте ограничено.
Если SEO специалист не заблокировал бесполезные для пользователей страницы, возникают следующие проблемы:
- Нерациональное расходование бюджета: робот будет бесполезно тратить выделенный лимит времени на анализ мусорных страниц.
- Размывание поисковых сигналов: страницы с дублями контента сбивают с толку краулер, ищущий контент посадочной страницы.
- Увеличение нагрузки на сервер: на больших сайтах слишком большое количество бесполезных для пользователей страниц, просматриваемых краулерами, может замедлить работу сайта, что негативно скажется на его дальнейшем ранжировании.
Выявление бесполезных для пользователей страниц в индексе
Для их поиска используют два бесплатных инструмента:
- Google Search Console: раздел «Проиндексированные страницы».
- Яндекс Вебмастер.
Как управлять индексацией ненужных в поиске страниц
SEO-эксперты используют следующие методы:
1. Запретить краулеру сканировать и индексировать страницы
- через файл robots.txt
- через ограничение доступа на страницу (пароль)
2. Разрешить краулеру сканировать страницу, но заблокировать ее индексацию
- через метатег noindex
3. Склеить страницу -дубль с ее основной версией
- с помощью тега rel=canonical
- с помощью 301 редиректа
- с помощью директивы clean-param (для Яндекса).
После проведения этих работ в течение полугода ненужные в поиске страницы обычно удаляются из индекса.
Инструменты для управления индексацией
Для каждого типа бесполезных для пользователей страниц существует свой оптимальный метод блокировки.
Пароль на страницу
Непубличные страницы с конфиденциальными данными лучше всего закрывать паролем.
robots.txt
Чтобы запретить краулерам посещать, например, технические разделы сайта со служебными страницами, файлами и папками, используют инструмент robots.txt.
Robots.txt представляет собой текстовый файл, расположенный в корневой директории сайта с комбинациями запрещающих и разрешающих директив.
В нижеследующем примере показана совместная работа двух директив, указывающих краулеру не посещать системный раздел “wp-admin” сайта за исключением страницы “admin-ajax.php”. (Раздел “wp-admin” отвечает за функционирование админ-панели управления контентом сайта):
Внимание: В заблокированных от сканирования технических разделах сайта обязательно открывайте краулеру доступ к файлам js и css, которые необходимы для рендеринга страниц.
Метатег noindex
Для закрытия от индексации страницы без контента в её код вписывают метатег “noindex”.
Вот как это выглядит на примере:
Убедитесь, что страница с метатегом noindex не заблокирована в файле robots.txt, иначе краулер не сможет прочитать эту директиву.
Преимущество этого метода заключается в «гибкости» контроля за индексацией каждой отдельной страницы.
rel=canonical
Для управления индексацией страниц с дублями контента используют более «изощренные» приемы.
Появившись в поисковой выдаче, страница с дублем контента также, как и посадочная страница с основной версией контента со временем соберут положительные поисковые сигналы, влияющие на рейтинг сайта (если контент качественный).
Поисковые сигналы — это факторы, которые поисковые системы используют для определения релевантности и качества веб-страниц по отношению к запросам пользователей.
К внешним поисковым сигналам относятся, например, отношение показов страницы к кликам по ее url (CTR); обратные ссылки (ссылочный вес); последний клик (полнота контента) и т.д.
При работе с дублями контента цель не в том, чтобы удалить их из индекса, а в том, чтобы, во-первых, подклеить их сигналы к сигналам посадочных страниц, во-вторых, перевести дубли контента в разряд «неосновная версия страницы».
Для решения этой задачи используют атрибут rel=canonical тега <link> в коде страниц.
Пример:
Итак, rel=canonical, расположенный в коде страницы с дублем контента, указывает, где находится посадочная страница с основной версией контента.
301 редирект
Этот прием можно использовать для управления индексацией, например, страниц c частично-дублированным контентом (near duplicat content).
Предположим, что на сайте есть две страницы из индекса, контент которых частично дублируется:
- URL1 с устаревшей инструкцией для Айфон 1 (https://site.com/apple/iphone1-guide);
- URL2 с инструкцией для Айфон 16 (https://site.com/apple/iphone16-guide).
На первый взгляд логично было бы просто физически удалить с сайта страницу с устаревшим контентом.
Однако в этом случае возникают проблемы с SEO:
- обратные ссылки на удаленную страницу становятся для краулера битыми;
- накопленные прежде положительные поисковые сигналы удаленной страницы без пользы «утекут» с сайта в никуда.
Чтобы этого избежать мы применяем 301 редирект.
Преимущества метода:
- Во-первых, 301 редирект сообщает краулерам, что страница с частичным дублем контента (URL1) была перенаправлена на страницу с актуальным контентом (URL2), т.е. проблем с дублями контента больше не существует.
- Во-вторых, 301 редирект позволяет автоматически перенаправлять пользователя на актуальную версию страницы без посещения страницы с устаревшим контентом, что удобно.
Существуют несколько вариантов настроить 301 редирект. Один из них- это внести в файл .htaccess сайта следующую запись:
Владельцы сайтов часто задают следующий вопрос: «Зачем применять 301 редирект и затем удалять страницу с частичным дублем контента, если вместо этого можно обновить ее контент до актуального?»
Ответ: «А как быть с неактуальным названием товара/услуги, прописанным в url обновленной страницы? URL не изменить, также как не изменить почтовый адрес вашей квартиры. »
Директива clean-param
Yandex разработал интересный инструмент для управления действиями своих краулеров, связанных с индексацией страниц c частично-дублированным контентом (near duplicat content), который называется Clean-param.
Этот инструмент (директива) особенно удобен для групповой блокировки от индексации страниц-частичных дублей, URL которых содержат GET-параметры.
Что такое URL с GET-параметрами разберем на примере:
Пользователь использовал фасетный фильтр сайдбара для группировки товаров по определенным характеристикам. В ответ CMS сайта сгенерировала соответствующую страницу, URL которой содержит GET-параметры.
Теперь нам нужно заблокировать индексацию группы URL с GET-параметрами:
Для этого в файле robots.txt прописываем директиву Clean-param:
Алгоритм работы этой директивы для Яндекс- краулера следующий: «Если URL страницы содержит параметры «yprqee» и/или «device», то игнорировать их и переключиться обратно на версию основной страницы».
Заключение
Закрывайте непубличные и личные страницы с помощью авторизации соединения.
Блокируйте группы технических страниц с помощью директив файла robots.txt.
Блокируйте страницы без контента с помощью метатегов noindex robots.
Склеивайте дублированный контент с его основной версией, применяя атрибут rel=canonical.
Склеивайте частично дублированный контент с его основной версией, применяя 301 редирект (Clean-param в случае SEO под Яндекс).
Анатолий Снежко, SEO специалист, маркетолог, https://anatole-seo.ru/