Случайный лес (Random Forest) — алгоритм машинного обучения с учителем, который состоит из множества отдельных независимых «решающих деревьев».
Чтобы повысить качество предсказаний, в машинном обучении используют ансамбли — алгоритмы, сочетающие сразу несколько моделей. Метод случайного леса предложен Лео Брейманом и Адель Катлер.
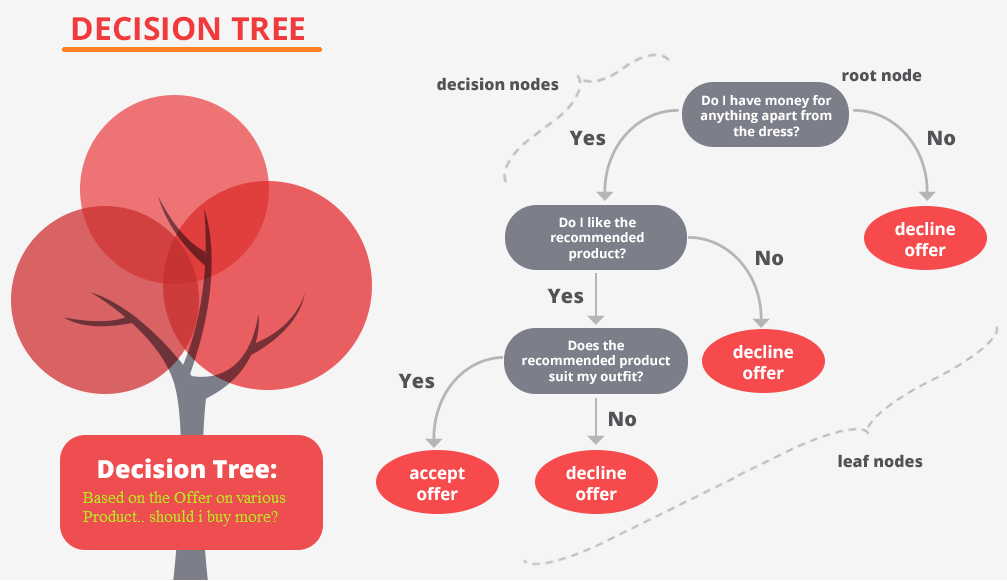
Алгоритм применяется для задач классификации (предсказание класса, например, к какому семейству принадлежит растение), регрессии (предсказание непрерывной величины — на сколько градусов повысится средняя температура зимой) и кластеризации. Основная идея заключается в использовании большого ансамбля решающих деревьев, каждое из которых само по себе даёт очень невысокое качество классификации, но за счёт их большого количества результат получается хорошим. Каждое дерево строится независимо друг от друга на разных подвыборках обучающих данных. При этом при обучении каждого дерева используются разные комбинации признаков (характеристик) объектов, для которых делается предсказание, — поэтому деревья не похожи друг на друга.

Алгоритм сочетает в себе две основные идеи: метод бэггинга (bootstrap aggregating, бутстрэп-агрегирование) Бреймана и метод случайных подпространств, предложенный Тин Кам Хо.
В итоге мы много раз строим много разных деревьев на случайно выбранных данных.
Основные шаги работы метода случайного леса:
- Создание подвыборок данных. Для каждого дерева создаётся случайная подвыборка из исходного набора данных с возвращением (bootstrap).
- Построение деревьев решений. Для каждой подвыборки строится дерево решений. При этом на каждом узле дерева выбирается случайное подмножество признаков для разделения.
- Агрегация результатов. Для задачи классификации используется голосование большинства, а для задачи регрессии — усреднение предсказаний всех деревьев. Таким образом, итоговый прогноз получается более точным и устойчивым к шуму в данных.
Некоторые преимущества метода случайного леса:
- Высокая точность. Случайный лес часто показывает высокую точность благодаря объединению множества деревьев.
- Устойчивость к переобучению. За счёт использования подвыборок и случайных признаков метод случайного леса менее подвержен переобучению.
- Обработка пропущенных данных. Алгоритм может работать с пропущенными данными, что делает его более гибким.
- Интерпретируемость. Возможность оценки важности признаков помогает понять, какие признаки наиболее влияют на результат.
Некоторые недостатки метода случайного леса:
- Для реализации алгоритма требуется значительный объём вычислительных ресурсов.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумлённых данных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов, алгоритм работает хуже чем линейные методы.
- Проблема получения оптимального дерева решений является NP-полной задачей, с точки зрения некоторых аспектов оптимальности даже для простых задач. Таким образом, практическое применение алгоритма деревьев решений основано на эвристических алгоритмах, таких как алгоритм «жадности», где единственно оптимальное решение выбирается локально в каждом узле. Такие алгоритмы не могут обеспечить оптимальность всего дерева в целом.
Регулирование глубины дерева
- это техника, которая позволяет уменьшать размер дерева решений, удаляя участки дерева, которые имеют маленький вес.
То есть, вопрос, который возникает в алгоритме дерева решений — это оптимальный размер конечного дерева. Так, небольшое дерево может не охватить ту или иную важную информацию о выборочном пространстве. Тем не менее, трудно сказать, когда алгоритм должен остановиться, потому что невозможно спрогнозировать, добавление какого узла позволит значительно уменьшить ошибку. Эта проблема известна как «эффект горизонта». Тем не менее, общая стратегия ограничения дерева сохраняется, то есть удаление узлов реализуется в случае, если они не дают дополнительной информации.
Регулирование глубины дерева должно уменьшить размер обучающей модели дерева без уменьшения точности её прогноза или с помощью перекрестной проверки.
Есть много методов регулирования глубины дерева, которые отличаются измерением оптимизации производительности. Сокращение дерева может осуществляться сверху вниз или снизу вверх. Сверху вниз — обрезка начинается с корня, снизу вверх — сокращается число листьев дерева. Один из простейших методов регулирования — уменьшение ошибки ограничения дерева. Начиная с листьев, каждый узел заменяется на самый популярный класс. Если изменение не влияет на точность предсказания, то оно сохраняется.