
Части 1, 2, 3, 4-1, 4-2, 5, 6, 7, 8, 9,
В этой главе посмотрим на самую животрепещущую проблему юристов, как гуманитариев – это систематизация документов и информации в них и о них.
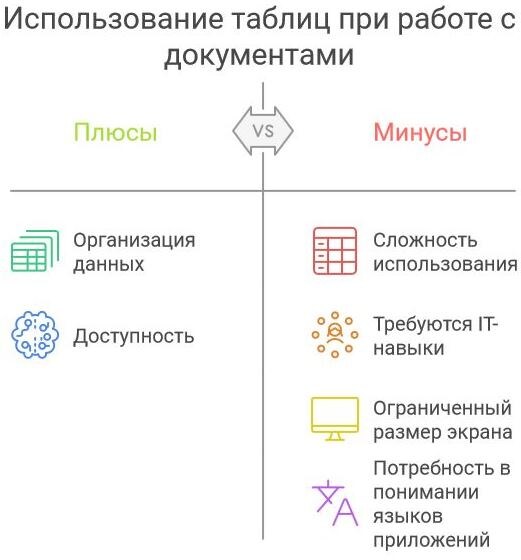
В современном праве все юристы сталкиваются с необходимостью обработкибольшого массива документов, особенно в сложных длительных судебных процессах. На сегодня есть только таблицы Excel, в которых можно организовать базу данных для частного пользователя, так как остальные инструменты требуют навыков владения IT-инструментами на уровне выше среднего.
Однако большинство юристов сталкиваются с трудностями при использовании таких таблиц, так как работа с табличной формой представляет сложность из-за отсутствия навыков работы с таблицами, тем более с такими, размеры которых выходят за размеры экрана дисплея. Такие действия, как преобразование и формирование новых и промежуточных таблиц, требует понимания внутренних языков приложения, так как не всегда стандартные функции, присутствующие на панели, могут привести таблицу к виду, который позволяет анализировать материалы дела.
Для примера, в этой публикации был использован материал трёхтомного дела объёмом более 700 страниц. Перечислив документы только первой половины первого тома, у меня получился список из 59 документов. Посчитав излишне, пополнять список следующими документами, в примере данной публикации, я остановился.
С другой стороны, при проведении сложного анализа документов, экран смартфона не позволяет работать с большой таблицей, особенно, во время судебного заседания. Это препятствует эффективности юристов, при формировании аргументов в реальном времени, что может быть критично в динамичной среде судебного процесса.
Современные юристы-гуманитарии обладают отшлифованной способностью к работе с текстовыми документами, которые структурированы, сложные и разветвлённые.
GPT-системы позволяют вводить данные в виде текста, обрабатывать его, сортировать, упорядочивать и группировать связанные элементы. Хотя эти процессы требуют определённых навыков в области информационных технологий от юристов, но системы искусственного интеллекта, значительно облегчают этот процесс, так как они доступны для неподготовленных пользователей.
Процесс фиксации необходимых данных из материалов дела, своего рода создание оглавления, представляет собой трудоёмкое занятие. Однако результатом становится файл, в котором занесены все ключевые моменты документов из дела, включая собственные наблюдения, аналитические выводы и внезапные идеи, пришедшие ему в голову во время слушаний.
Поскольку вспомогательных материалов обычно бывает много, возможность последующего просмотра в смартфоне прямо в зале суда имеет большое значение. Это можно сделать путем сохранения файлов в смартфоне или заливки их на свою страницу в интернете. Этот материал становится незаменимым помощником в ходе судебных заседаний, особенно при наличии большого количества сопутствующих документов.
В этой статье я опирался на структуру материалов по земельному делу. В деле сотни документов, некоторые из которых повторяются, так как были получены по разным запросам в различные органы. Документы относятся к разным эпохам (СССР, Россия до и после кадастрового учёта), были созданы различными организациями (исполкомы народных депутатов, муниципалитеты, БТИ, Архитектор города, МВД СССР и т. д.). Документы предоставлены разнообразными сторонами: истцом, ответчиком, Росреестром, архитектурными службами.
Образуется такой большой объём информации, который сложно удержать в голове. А если учесть, что такие процессы могут длиться месяцы или даже годы, и у любого профессионального представителя может быть несколько таких дел параллельно, то дополнительная возможность провести критический анализ и быстро представить необходимую позицию становится бесценной.
В качестве примера в статье я покажу, как строить и составлять хронологический список документов, который помогает определить, какой документ является основанием для договора купли-продажи земли, и возможность обнаружить, когда документы были составлены «задним числом».
Создание базы данных документов — процесс, требующий значительных усилий. Он состоит из нескольких этапов: фиксации, сохранения, идентификации, сортировки, анализа и синтеза. Фиксация происходит при ознакомлении с материалами дела в помещения суда, в котором обычно делают фотографии документов. Затем изучают фотографии в более комфортной обстановке. Совместить эти два этапа - задача особой сложности.
Это длительная во времени задача, но специалисты, которые перегружены работой, могут привлечь помощников, практикантов, ассистентов и секретарей, что значительно сокращает для них временные затраты на выполнение систематизации.
Первым шагом при создании такой базы данных будет формирование нескольких базовых строк в специально созданном для этой цели текстовом документе:
ДОКУМЕНТ001
НАЗВАНИЕ
ПОЗИЦИЯ
ДАТА
ИСТОЧНИК
КОЛИЧЕСТВО
КАЧЕСТВО
СВЯЗЬ
НОРМ
НОРМЫДОП
АДРЕС
ЗАМЕТКИ
Этот блок относится к отдельному документу и копируется для последующих документов, с увеличением номера на единицу и сохранением порядка следования в материалах дела: ДОКУМЕНТ001, ДОКУМЕНТ002, … ДОКУМЕНТ151.
Если в материалах дела появляются новые документы, то вы просто добавляете новый блок и изменяете нумерацию в соответствии с порядком следования. В данном случае эта нумерация понимается GPT-системой как идентификатор записи в базе данных. Согласно правилам формирования баз данных, идентификатор должен быть уникальным. Если он повторяется, то GPT-система может выдать ошибку или абсурд. Уникальность идентификационных номеров, или ID-номеров, является критически важной для функционирования системы.
Прописные буквы обозначают названия полей (столбцов) базы данных, что позволяет избежать путаницы в будущем.
Технически, названия документов могут быть адаптированы под конкретные нужды пользователя. Название ДОКУМЕНТ можно представлять как вам удобно: ДОКУМЕНТИВАНОВ, ДОКУМЕНТГАЗПРОМ и т.п. Такое представление будет влиять только на количество знаков в запросе к GPT-системе, что требует, если доступ платный, дополнительных расходов.
Визуальное представление названий документов позволяет пользователям сразу определить, какой файл они открывают, что особенно важно в условиях работы с большим объёмом информации. Это может предотвратить ошибки, связанные с открытием документов используемых в других делах и, соответственно, с неправильной интерпретацией данных.
На рисунке 2 представлю, какие обстоятельства (сущности, если говорить IT языком) закладываю в эти строки, для нашего примера, что ещё раз подчёркивает важность структурированного подхода в управлении информацией. В дополнение к основной информации здесь могут быть закодированы дополнительные параметры, которые помогут более точно охарактеризовать содержание каждого документа. Это может включать идентификаторы, статус, тип документа и другие важные сведения.
Правила.
1) Объем записи в строке принципиально особо не ограничивается. Если вы собираетесь использовать Excel, то рекомендую не больше 256 знаков.
2) Не используйте в тексте записи знаки «<», «>», «/»,
Ограничения для полей, их количество и способ представления информации зависят от целей, поставленных перед базой данных и результатами, которые вы хотите получить.
В использованном примере представлено второстепенное поле НОРМДОП, где в реальном процессе для одного и того же типа документов в течение 30 лет использовались различные нормативные акты.
В этом деле можно было бы добавить дополнительные поля, которые раскрывали бы информацию о дате заявления, дате извлечения документа, дате регистрации земельного участка. Также можно было бы добавить поле ДАТАПЛОЩАДИ, поскольку площадь земельного участка менялась с течением времени.
Если бы была введена такая учётная единица, то для одного из участков также необходимо было бы добавить поле ПЛОЩАДЬ, поскольку площадь этого участка менялась более 10 раз. Существовали такие периоды времени, что у спорного участка было несколько площадей: реально занимаемая владельцем, учтённая Росреестром, выделенная администрацией города и та, которую владельцы считали своей.
Как легко понять, для полного учёта всех аспектов этого дела в исходной базе данных необходимо предусмотреть встроенные модули для подбаз данных. Эти модули позволят адаптироваться к изменяющимся условиям и обеспечить максимальную достоверность и полноту получаемых результатов.
Как следует из предыдущего анализа, заранее определить точное количество необходимых полей для систематизации оказывается крайне сложной задачей.
В процессе работы над делом сведения о рассматриваемом объекте могут существенно изменяться и даже не один раз.
Для юристов, работающих с доказательной базой, это создаёт трудности, поскольку им необходимо адаптироваться к новым условиям и изменениям в структуре фактов.
Однако, несмотря на эти сложности, существует способ справиться с ними. Технические инструменты, которыми владеют GPT-системы, позволяют адаптироваться к появлению новых аспектов путём добавления дополнительных полей в исходный список. Такой подход безразличен к типу дел, которые вы сопровождаете: банкротство, развод, арбитражный спор, уголовный процесс.
Универсальность предложенной схемы позволяет использовать её в различных контекстах. В случае, если доказательная база не представляет собой сложности, создание подобной структуры становится излишним, так как затраты времени на подготовку этой базы превысят время естественной подготовки к судебному процессу.
Хотел бы напомнить, что каждый практикующий юрист знает по собственному опыту, как проявляются все новые и неожиданные обстоятельства по мере ознакомления с документами. Опытный юрист понимает, что возможность использовать эти факты в свою пользу напрямую зависит от его умения и настойчивости, а убедительность и значимость для суда — исключительно от его таланта и профессиональных качеств.
То же самое касается создания базы данных, предлагаемой в этой публикации, которые невозможно заранее предугадать и какие новые факты вы обнаружите. Все зависит от вашего мастерства составления запросов, тщательности анализа и осмысления информации в материалах дела, чтобы извлекать важные данные и делать выводы.
Перейдём от теоретических рассуждений к практическому применению GPT-систем.
После подготовки данных следующим этапом следует загрузка их в GPT-систему. Для частного пользователя это происходит через поле загрузки. В некоторых системах возможна загрузка всего файла сразу, но так, как у меня это получалось сделать один раз из пяти, то рассматривать этот способ не будем. Предполагаем, что эта ошибка связана с молодостью GPT-систем.
Поле ввода обычно ограничивает количество введённых символов одномоментно, в диапазоне от 2000 до 4000 знаков. Чтобы узнать это ограничение необходимо ознакомиться с инструкцией и выяснить допустимый лимит символов. При этом не следует беспокоиться, все системы предлагают для работы «сеансы». Любые части сеанса, даже загруженные по отдельности, GPT-системы, воспринимают как единое целое в той последовательности, в которой были загружены.
Затем, понятными вам разметками, делите текст на блоки необходимого размера в составленном файле. Это можно сделать с помощью макроса Word, но макросы достаточно капризная вещь, поэтому предлагать не буду. Этот процесс можно осуществить вручную, используя стандартные функции программы Word, но встроенного инструмента для выполнения такой задачи нет.
Метод подбора достаточно прост и понятен, он приведён на рисунке 3.
Совет. Перед загрузкой поставьте сообщения:
1) «Загружаю базу данных ДОКУМЕНТ» - сообщает системе, что вы собираетесь делать.
2) «База данных ДОКУМЕНТ» - позволяет понять системе, что база данных начинается с этого момента.
Это позволяет GPT-системе ориентироваться в том, что вы делаете и не мешать проводить загрузку.
И в конце загрузить сообщение «Конец Базы данных ДОКУМЕНТ», которое позволяет системе определить конец ваших данных.
Представляю результаты загрузки на рисунке 4.
Продолжение следует
Часть 1. Давайте дружить
Часть 2. Криминалистическое описание
Часть 3. Дефекты печати, пока не преодолимо
Часть 4-1. Систематизация (1)
Часть 4-2. Систематизация (2)
Часть 5. Инструменты GPT
Часть 6. Zero-shot - контролируй соперника
Часть 7.
Часть 8.
Часть 9.