Метод K-ближайших соседей (K-Nearest Neighbors, KNN) — алгоритм классификации и регрессии, основанный на гипотезе компактности. Она предполагает, что расположенные близко друг к другу объекты в пространстве признаков имеют схожие значения целевой переменной или принадлежат к одному классу.

Преимущества метода K-ближайших соседей: простота, отсутствие необходимости в обучении модели, гибкость. Недостатки: высокие вычислительные затраты при работе с большими наборами данных, чувствительность к шуму и выбросам в данных.
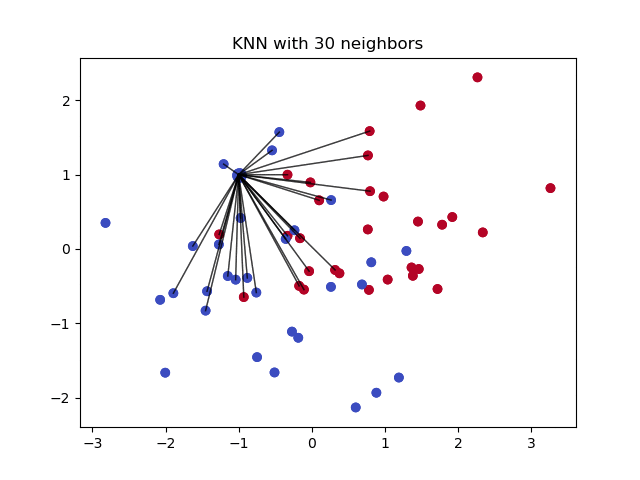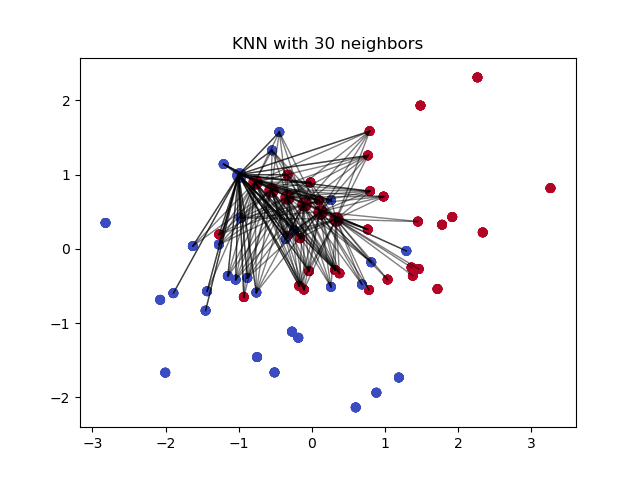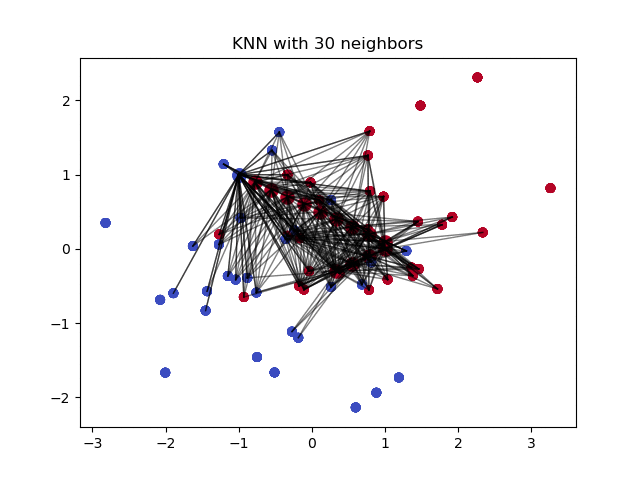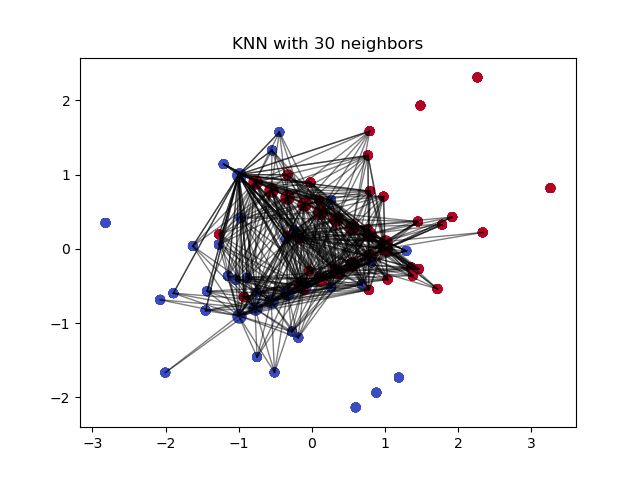
1) Вычисляется расстояние между тестовым и всеми обучающими образцами.
2) Далее из них выбирается k-ближайших образцов (соседей), где число k задаётся заранее.
3) Итоговое прогнозом среди выбранных k-ближайших образцов будет мода в случае классификации и среднее арифметическое в случае регрессии.
4) Предыдущие шаги повторяются для всех тестовых образцов
Как происходит предсказание
влияние к
Также зависит от выбора весов - есть две стратегии 1. все веса одинаковы 2. выбор весов пропорционален их расстоянию до точки
в итоге регрессия будет выглядеть так
Основные шаги работы KNN:
- Выбор параметра K. Определяется количество ближайших соседей, которые будут использоваться для классификации.
- Расчёт расстояний. Вычисляются расстояния между новым объектом и всеми объектами в обучающем наборе данных.
- Сортировка соседей. Все объекты обучающего набора данных сортируются по возрастанию расстояния до нового объекта.
- Выбор K ближайших соседей. Выбираются K объектов, которые находятся ближе всего к новому объекту.
- Классификация. Определяется класс нового объекта на основе большинства голосов среди K ближайших соседей. Класс, который встречается чаще всего среди ближайших соседей, будет присвоен новому объекту.