1. Machine Learning
На самом деле существует для всей этой области несколько определений и большое количество схем, причем, последние подчас друг другу противоречат, как и во всей прикладной информатике. Я для себя решила предаться перфекционизму и выбирать определенные, отказываясь от других.
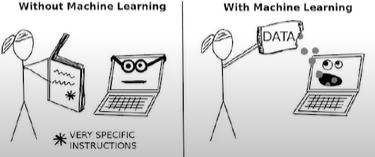
Машинное обучение - класс методов, характерной чертой которого является не прямое решение задачи, а обучение за счёт применения множества сходных задач.
Мы, конечно, можем и формализовать это историю,
ведь у нас есть некие данные и при применении модели, мы хотим получить некие неслучайные ответы.
Часто такие данные представлены в виде таблицы, а признаки, типы данных в ней могут быть числовыми или категориальными.
В целом, типы данных могут быть
- табличными
- изображениями
- естественный язык
- временные ряды.
Естественно, основным понятием является тренировочная выборка, а модель должна использовать признаки для предсказания целевой переменной, которая в свою очередь, зависит от параметров (аргументы, которые оптимизируются моделью без нашего вмешательства) и гиперпараметров (или стратегий, которые мы должны настраивать перед запуском) модели.
Чтобы понять, насколько мы хорошо обучили модель, вводится функция потерь. Функции потерь бывают разные, но выход один - при большом числе потерь они выдают большое значение, и наоборот.
Естественная цель - их минимизировать на тренировочной модели.
Но следующая цель - валидизация на реальной выборке, потому что некоторые из них и при хороших показателях на тренировочной выборке могут себя не очень хорошо повести на новых данных. Это называют "устойчивостью модели к новым данным". Один из способов - отложенная выборка - здесь как бы часть выборки отщепляют, проверяют на основной части, потом на остальной - если ведете себя примерно одинаково и на тренировочной и на валидационной выборках, вероятно, модель устойчива.
Второй вариант - перекрестная проверка. Здесь мы разбиваем выборку несколько раз, например, как на картинке. И проверяем последовательно в разных разбиениях.
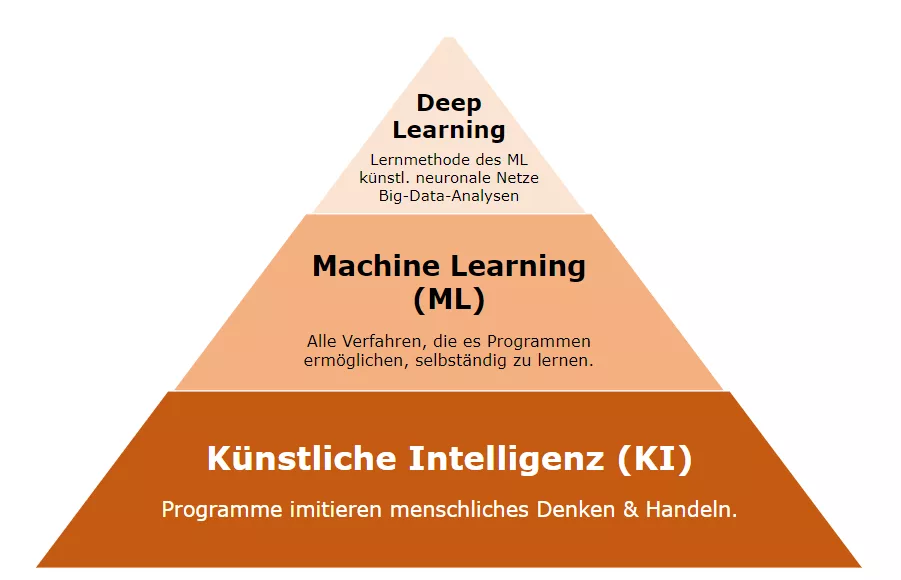
2. Deep Learning
Глубокое обучение (deep learning) — это вид машинного обучения с использованием многослойных нейронных сетей, которые самообучаются на большом наборе данных. Искусственный интеллект с глубоким обучением сам находит алгоритм решения исходной задачи, учится на своих ошибках и после каждой итерации обучения даёт более точный результат, прогноз.
Некоторые области применения глубокого обучения:
- Лингвистика. Глубокое обучение применяется для анализа текстов, распознавания речи, автоматизации ответов и создания текста. 2
- Электронная коммерция и социальные сети. Алгоритмы анализируют предпочтения пользователей, помогают делать персонализированные предложения.
- Обработка изображений. Например, превращение старых чёрно-белых фотографий в цветные.
- Компьютерное зрение. Этот метод помогает распознавать объекты на изображениях и видео, что часто используется в медицинской и автомобильной сферах.
- Автономные транспортные средства. Глубокое обучение помогает анализировать окружающую среду и принимает решения в реальном времени для безопасного управления.
- Создание контента. Алгоритмы могут генерировать тексты, включая новостные сообщения и литературные произведения, основываясь на заданных критериях.
Интересно, что идея появилась еще в середине прошлого 20 века, но тогда результаты не были впечатляющими. Сам термин «глубокое обучение» появился в научном сообществе в 1986 году после работы Рины Дехтер, а первый общий рабочий алгоритм для глубоких многослойных перцептронов прямого распространения был опубликован в книге советских учёных Алексея Григорьевича Ивахненко и Валентина Григорьевича Лапы «Кибернетические предсказывающие устройства» ещё в 1965 году. Но только в начале 21 века компьютеры стали достаточно мощными для этих задач. В 2012 году команда под руководством Джорджа Э. Даля выиграла конкурс «Merck Molecular Activity Challenge», используя многозадачные глубокие нейронные сети для прогнозирования биомолекулярной мишени одного препарата.
Отсюда пошло и понятие "Глубокая нейронная сеть" (глубинная нейронная сеть, ГНС, англ. DNN — Deep neural network) — это искусственная нейронная сеть (ИНС) с несколькими слоями между входным и выходным слоями.
Глубокое обучение — это алгоритмы для моделирования высокоуровневых абстракций с применением многочисленных нелинейных преобразований.
В первую очередь к глубинному обучению относятся следующие методы и их вариации:
- Определённые системы обучения без учителя, такие как ограниченная машина Больцмана для предварительного обучения, автокодировщик, глубокая сеть доверия, генеративно-состязательная сеть,
- Определённые системы обучения с учителем, такие как свёрточная нейронная сеть, которая вывела на новый уровень технологии распознавания образов,
- Рекуррентные нейронные сети, позволяющие обучаться на процессах во времени,
- Рекурсивные нейронные сети, позволяющие включать обратную связь между элементами схемы и цепочками.
Комбинируя эти методы, создаются сложные системы, соответствующие различным задачам.
Сравнение программ глубокого обучения
*Немного о трансформерах*
Трансформер — архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain.
Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией, а декодировщик — часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа. Каждый кодировщик и декодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма внимания).
Таким образом, в основе модели трансформера лежит механизм самовнимания, который позволяет оценивать важность разных элементов входной последовательности. Внимание на основе скалярного произведения.
Трансформеры — относительно новый тип нейросетей, направленный на решение последовательностей с легкой обработкой дальнодействующих зависимостей. На сегодня это самая продвинутая техника в области обработки естественной речи (NLP), , и решения таких задач как машинный перевод и автоматическое реферирование.
С их помощью можно переводить текст, писать стихи и статьи и даже генерировать компьютерный код. В отличие от рекуррентных нейронных сетей (RNN), которые выполняют эти же задачи, трансформеры не обрабатывают последовательности по порядку, поэтому легче распараллеливаются и быстрее обучаются.