
Исследователи Palo Alto Networks на практике проверили использование больших языковых моделей (LLM) для масштабной генерации новых вариантов вредоносного JavaScript-кода. Но главное, что такой код более устойчив к обнаружению всевозможными системами безопасности.
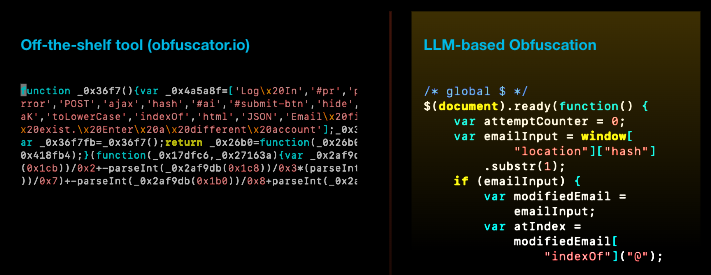
«При наличии достаточного количества слоёв преобразований многие инструменты обнаружения вредоносных программ могут быть обмануты, посчитав, что фрагмент вредоносного кода является безвредным. Это означает, что по мере того как вредоносное ПО со временем развивается (намеренно или случайно в целях скрытия), эффективность классификации вредоносных программ ухудшается», — пишут исследователи.
Они создали алгоритм на основе LLM, служащий для пошагового переписывания вредоносного JavaScript-кода. Для начала ему было задано переименовать переменные, добавить «мёртвый» (ненужный) код и удалить ненужные пробелы. Используя раз за разом этот метод, сервисы определения вредоносного кода с каждым разом всё реже справлялись со своей задачей.
Специалисты по кибербезопасности были вынуждены модернизировать собственный классификатор вредоносного JavaScript-кода, обучив его на десятках тысяч переписанных с помощью LLM примеров. Это помогло значительно повысить защиту от фишинговых атак и вредоносных веб-страниц.
Подробности исследования доступны по ссылке.