Тем, кто писал руководство по Grafana - определенно, незачет. Я потратил 3 часа и тонну своих нервов, чтобы до меня наконец-то дошло. Вот кто им мешал написать, что структура исходного набора данных для визуализации в некоторых случаях (например, при отображении логов из Grafana Loki) является фиксированной и, на уровне запроса, не изменяемой? Простая же вещь: источник данных поставляет dataset, в случае с Loki - это одна таблица. В некоторых случаях, структура таблиц в этом dataset определяется запросом, лежащим в основе визуализации, а в некоторых - эта структура фиксированная (например, как для Loki). После получения dataset из запроса, визуализация может прикрутить сверху свой набор трансформаций данных, в том числе - скрыть колонки, переименовать, добавить свои вычисляемые (в том числе - с выборкой данных, например, из JSON) колонки.
Ну а я, в результате, долго тупил, пытаясь понять - а откуда взялись все эти столбцы, если я их нигде и никак не задавал.
Для тех, кто сейчас будет укоризненно качать головой и кивать на logfmt: не, ни фига не работает. Не знаю, в чем причина, но с помощью logfmt, в данном конкретном случае (логи с Loki), даже уменьшить количество выходных столбцов не удалось. Времени у меня толком нет, так что и разбираться я не стал.
UPD: Тут мне подсказали, что есть нюансы, которые я упустил из виду. Во-первых, в данной ситуации (логи с Loki) logfmt только дописывает метки в поле labels. А на состав столбцов не влияет. Я, правда, видел в документации, что при работе с СУБД, logfmt вполне себе может добавлять и убирать столбцы, но, наверно, это другое. Во-вторых, есть преобразования, которые (внезапно!) могут преобразовать состав столбцов из начального в какой-то другой прямо на уровне Query. В частности, надо смотреть в раздел Operations. Например:
count by(level) (rate({compose_service="promtail"} | logfmt [1m]))
Сколько у нас будет в результате колонок? У меня две - Time и {level="info"}! Почему? А чтоб никто не догадался!
Так, кстати. Используемые версии ПО: grafana/grafana-oss:11.4.0, grafana/loki:3.2.2.
Запишем, теперь, весь процесс настройки панели с логами. Сразу скажу, что получаемые данные зависят и от того, как логи собираются и записываются. Так что мой набор меток - это (частично) результат моих, внешних, настроек.
Добавляем панель визуализации, ставим фильтр меток: {compose_service="promtail"}. В настройке панели (слева, по умолчанию), ставим тип визуализации "Table", меняем заголовок, смотрим и меняем, если нужно, прочие настройки отображения. Я включил "Enable pagination", и все. Не трогаем пока Field Override.
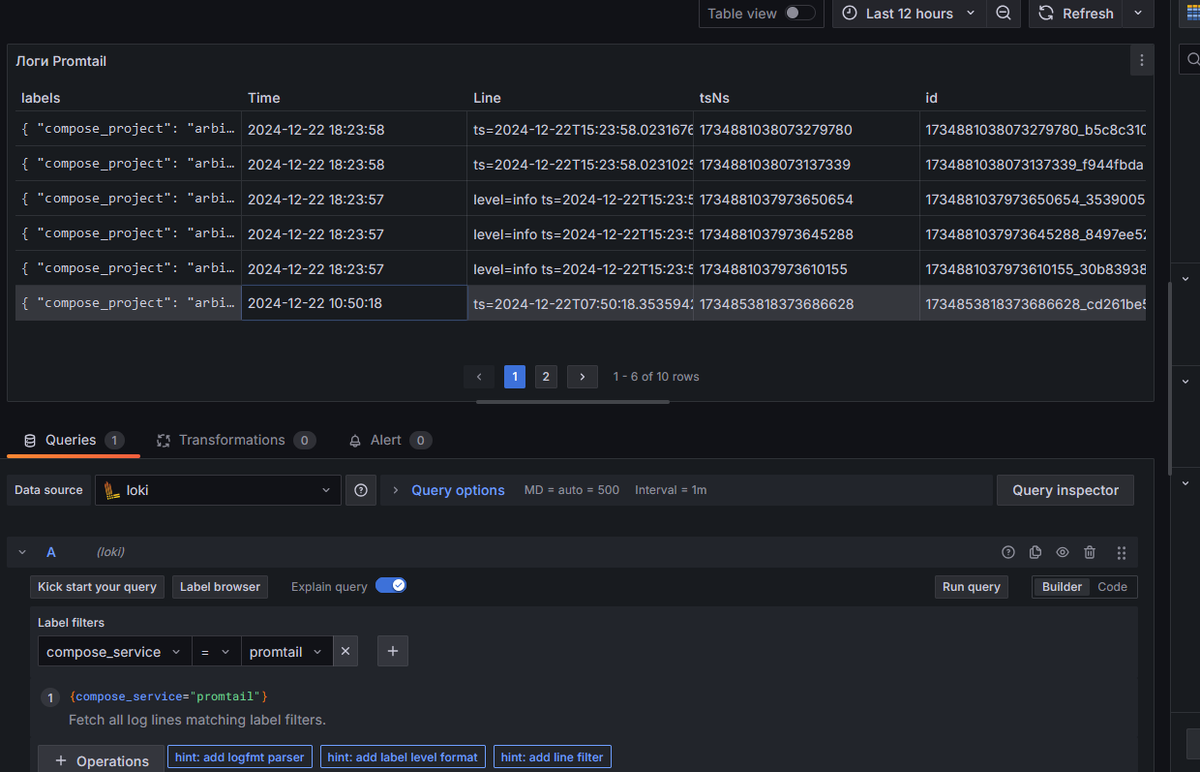
Обратите внимание на состав столбцов. Это и есть тот начальный и фиксированный по структуре набор столбцов, с которыми я дальше буду работать. Фиксированный - в том смысле, что начинать всегда с него придется, все другие столбцы будут получаться из этих исходных. Вроде еще в описании источника данных можно чего-то сделать и какие-то дополнительные поля объявить, но мне пока и этих хватит.
Дальше, в Operations, добавляем logfmt - без каких-либо опций. В результате, общий код запроса:
{compose_service="promtail"} | logfmt
В результате применения этого парсера, у нас теперь нужная информация лежит в поле labels. Чем и будем пользоваться.
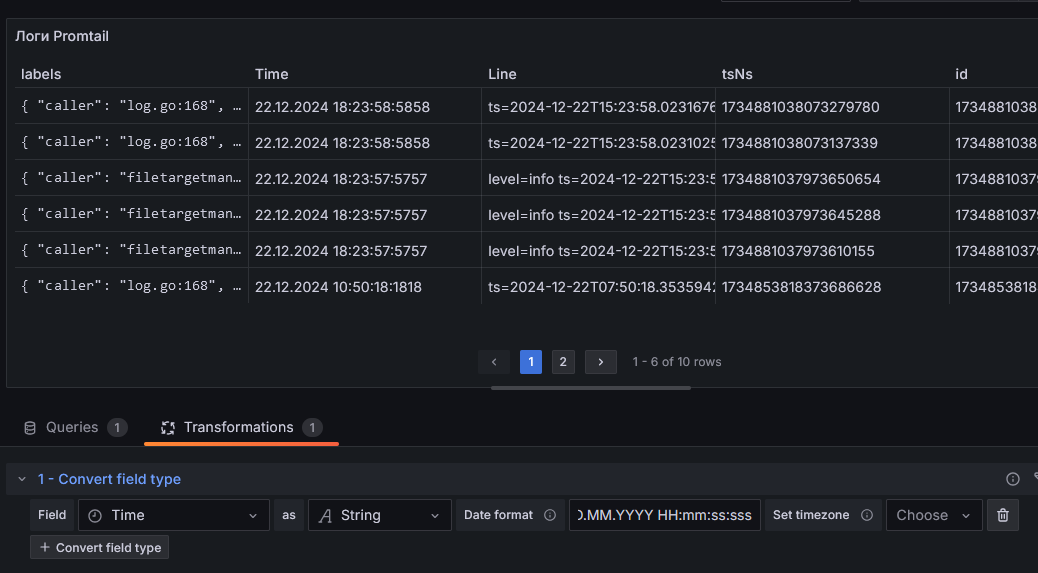
Так-с, переходим к вкладке Transformations. Добавляем первое преобразование: Convert field type. Указываем
Field: Time, As: String, Date format: DD.MM.YYYY HH:mm:ss:sss
Собственно, можно было бы и не делать, но это очень полезный вариант - поскольку мы можем не полагаться на предлагаемый формат даты, а указать свой. Откуда брать описание форматирования? Понятия не имею. Я его так и не нашел. Нашел только несколько примеров, откуда и взял эту строку. Опять же, спасибо составителям документации по Grafana! Вроде бы, этот формат соответствует правилам описания форматов из секции [date formats] файла настроек Grafana, но дальше я копать не стал.
Добавляем вторую трансформацию - Extract fields:
Source: labels
Format: JSON
Add path:
Field: level, Alias: Тип
Field: msg, Alias: Сообщение
Ура, у нас появилось нужное содержание в понятном виде!
Добавляем третье преобразование - Organize fields by name. В нем скрываем поля Line, tsNs, labelTypes, id. Там же переименовываем Time в "Время", и labels в "Все данные". Перетаскивая поля (тащим за элемент, где 6 точек нарисовано) в описании трансформации, разместим поля так, как требуется.
Что ж, почти готово, для первого раза. Осталось немного косметики. Отправляемся в настройки таблицы, в Add field override. Для него выбираем Field by name, и создаем 3 записи - для каждого из видимых полей. Для "Время" указываем column width = 200, для "Тип" - column width = 70, для "Сообщение" и "Все данные" - включаем Cell value inspect. Скрины настроек приводить не буду - там и так все просто.
Сохраняем визуализацию, dasboard - и вот первый, еще достаточно скромный, результат.