Аннотация
Фотография стала неотъемлемой частью современной жизни, с повсеместным распространением социальных сетей и смартфонов, оснащенных камерами. Качество этих камер определяется двумя ключевыми параметрами: разрешением изображения (количеством пикселей) и глубиной цвета (битностью). Однако даже при высоких значениях этих параметров, мобильные камеры часто не способны передать всю полноту реального мира из-за ограниченного динамического диапазона.
Природные сцены характеризуются широким спектром интенсивности освещения, от глубоких теней до ярких бликов, что создает проблемы для стандартных камер без поддержки HDR (High Dynamic Range). В результате, снимки, сделанные на мобильные устройства, часто страдают от потери деталей в слишком темных или светлых областях, что особенно заметно в сложных условиях освещения.
Данный эксперимент ставит целью разработку инновационного подхода к решению этой проблемы с использованием искусственных нейронных сетей. Предлагается метод программного создания HDR-изображений, который позволит значительно улучшить качество фотографий, сделанных на камеры с ограниченными возможностями.
Первым этапом эксперимента станет создание карты изображения на основе набора данных, состоящего из серии снимков одной и той же статичной сцены, но с разной экспозицией. Эти LDR (Low Dynamic Range) изображения послужат основой для обучения нейронной сети распознаванию и воссозданию широкого динамического диапазона.
На следующем этапе планируется применение обученной модели для оптимальной настройки параметров изображения с целью получения корректного цветового пространства и максимально реалистичной передачи сцены. В процессе разработки и оптимизации алгоритма будут учитываться несколько ключевых факторов: количество итераций обучения, различные стратегии машинного обучения, данные, получаемые непосредственно с сенсоров камеры, а также оптимальное количество исходных снимков с разной экспозицией, необходимое для достижения наилучшего результата.
Ожидается, что результаты данного труда найдут широкое применение в области мобильной фотографии. Разработанный алгоритм позволит пользователям бюджетных устройств получать более качественные, детализированные и реалистичные снимки, приближающиеся по своим характеристикам к фотографиям, сделанным на профессиональное оборудование. Это не только повысит удовлетворенность пользователей, но и может открыть новые возможности для творческого самовыражения и документирования окружающего мира с помощью доступных технологий.
Цели работы
- Совершенствование алгоритмов машинного обучения для задач компьютерного зрения: разработка инновационных подходов, позволяющих повысить точность и эффективность распознавания объектов на изображениях, особенно в условиях ограниченных наборов данных или сложных визуальных сцен.
- Улучшение обобщающей способности моделей компьютерного зрения: создание архитектур нейронных сетей, способных успешно адаптироваться к различным условиям съемки, освещения, ракурсов и масштабов объектов, обеспечивая стабильную производительность в реальных сценариях применения.
- Восстановление и компенсация потерь и ошибок, вызванных процессом квантизации: разработка методов, позволяющих минимизировать негативные эффекты квантизации на качество изображений.
- Реконструкция HDR-изображений: создание алгоритмов для восстановления HDR-изображений из низкокачественных HDR или LDR-изображений с учетом различных масштабов разрешения.
- Разработка системы для создания HDR-изображений на устройствах с низкой вычислительной мощностью: оптимизация алгоритмов для эффективной работы на персональных компьютерах и мобильных устройствах, расширяя возможности создания HDR-изображений на широком спектре устройств.
Введение
В современной сфере обработки визуальной информации технология расширенного тонального диапазона (HDR) становится ключевым элементом в создании изображений исключительной четкости. Эта инновация находит широкое применение в различных областях, включая компьютерную графику, системы машинного зрения и другие визуальные технологии. Суть HDR заключается в значительном расширении диапазона интенсивности, позволяя создавать изображения с более широким спектром яркости, чем это возможно при использовании стандартных методов фиксации.

Тональный диапазон определяется как соотношение между максимальными и минимальными значениями интенсивности, которые могут быть надежно переданы или воссозданы с использованием доступных вычислительных систем. Альтернативное определение рассматривает тональный диапазон как объем данных, который устройство способно зафиксировать при максимальной светочувствительности в сцене. Это подразумевает наличие широкой шкалы интенсивностей, охватывающей как самые темные, так и самые светлые участки изображения.
Эффект расширенного тонального диапазона особенно заметен при фиксации сцен в условиях яркого естественного освещения. В таких ситуациях различия между световыми шкалами становятся очевидными, в зависимости от настроек светочувствительности. Небосвод может выглядеть чрезмерно ярким, в то время как тени под растительностью и некоторые участки изображения могут казаться полностью затемненными.
Для количественной оценки тонального диапазона используется понятие "шага экспозиции". Каждый шаг соответствует удвоению или уменьшению вдвое количества света. Это означает, что увеличение экспозиции на один шаг удваивает количество света на изображении. Например, если фиксация производится с выдержкой 1/100 секунды, то экспозиция в один шаг будет соответствовать 1/50 секунды, а на один шаг темнее - 1/200 секунды.
При фиксации с использованием одного шага самые светлые объекты на изображении будут такими же яркими, как и самые темные участки. Отношение между шагами близко к экспоненциальному, что означает: если устройство имеет сенсор с тональным диапазоном в два шага, самая светлая область сцены будет значительно ярче самой темной точки. Выход за эти границы приведет к появлению на изображении ярко выраженных бликов или черных теней.
Большинство современных устройств для фиксации изображений обладают широким тональным диапазоном и высокой производительностью. Обычно встречаются модели с диапазоном от 12 до 14 шагов, в то время как человеческое зрение способно различать до 20 шагов яркости.
Для создания изображений с расширенным тональным диапазоном требуется набор снимков одной и той же сцены, охватывающий диапазон от теней до ярко освещенных участков. Использование таких изображений позволяет захватывать и сохранять реальное освещение, передавать его или обрабатывать для различных задач без необходимости линеаризации сигнала или работы с обрезанными значениями. Для получения настоящего изображения с расширенным тональным диапазоном традиционными методами необходимо использовать специализированное оборудование. Однако такое оборудование часто недоступно рядовым пользователям из-за высокой стоимости.
В связи с этим возникла потребность в разработке альтернативных решений для создания изображений с расширенным тональным диапазоном на основе обычных снимков. Такие технологии находят применение в различных областях, включая игровую индустрию и системы виртуальной реальности.
Существует несколько подходов к решению этой задачи. Один из них заключается в объединении нескольких изображений с различной экспозицией для создания единого изображения с расширенным тональным диапазоном. Основная проблема этого метода состоит в необходимости использования специального программного обеспечения или оборудования для получения изображений с разной экспозицией. Это затрудняет создание необходимых наборов данных для обучения и тестирования алгоритмов.
В результате, ряд исследований сосредоточился на разработке методов создания изображений с расширенным тональным диапазоном на основе одиночного снимка. Этот подход позволяет обойти ограничения, связанные с необходимостью получения нескольких экспозиций одной сцены.
С развитием новых технологий машинное обучение стало одним из наиболее перспективных подходов, используемых в настоящее время для решения задач в области обработки изображений. Это развитие привело к появлению методов создания изображений с расширенным тональным диапазоном на основе глубокого обучения.
Некоторые исследования используют модели глубоких нейронных сетей, разработанные на основе широкого спектра архитектур, начиная от традиционных сверточных нейронных сетей и заканчивая генеративно-состязательными сетями. Эти подходы показывают многообещающие результаты в задачах создания и улучшения изображений с расширенным тональным диапазоном.
Применение методов глубокого обучения открыло новые возможности для улучшения качества изображений и расширения их тонального диапазона. Исследователи экспериментируют с различными архитектурами нейронных сетей, адаптируя их для решения специфических задач в этой области. Например, сверточные нейронные сети успешно применяются для извлечения важных признаков из изображений и их последующего преобразования в формат с расширенным тональным диапазоном. Генеративно-состязательные сети, в свою очередь, показывают впечатляющие результаты в генерации реалистичных изображений с расширенным тональным диапазоном, способных обмануть даже опытный глаз.
Теория. Используемые методы
Получение цифрового изображения
В сфере обработки цифровых изображений формирование изображений с расширенным динамическим диапазоном (HDR) опирается на значительную вариативность уровней яркости, присущую реальным сценам. Достижение HDR-эффекта возможно путем манипулирования различными характеристиками съемки, в частности, длительностью выдержки. При этом следует принимать во внимание, что устройство камеры функционирует как нелинейная система. Яркость точки изображения в координатах (i,j) может быть выражена следующим образом:
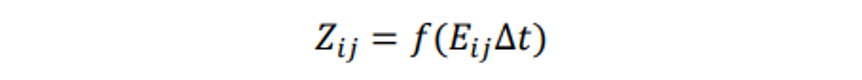
В данном случае ∆t обозначает длительность выдержки, Eij - уровень освещенности в той же точке, а f - нелинейную характеристику камеры. Анализируя значения конкретной точки на снимках одной и той же сцены, сделанных с разной выдержкой, можно получить аппроксимацию изображения с шумами. На основе этого метода создали взвешенную функцию f⁻¹(Zij)/∆t для оценки реального значения пикселя Eij. Для применения нейросетевых алгоритмов в процессе формирования HDR-изображений, на вход подаются значения пикселей LDR-изображения статичного объекта. Эти данные затем используются для прогнозирования уровней освещенности или построения HDR-карты сцены. Следует подчеркнуть, что создание идеально точного отображения не представляется возможным, достижимо лишь приближенное решение.
Архитектура CNN
Сверточные нейронные сети (CNN) представляют собой особый класс архитектур глубокого обучения, которые произвели революцию в области компьютерного зрения. Их уникальность заключается в использовании специальных сверточных слоев, где математические операции свертки позволяют автоматически извлекать важные признаки из изображений. В отличие от полносвязных нейронных сетей, CNN эффективно обрабатывают пространственные данные благодаря разделяемым весам и локальным рецептивным полям.
Ключевой механизм работы CNN основан на последовательном применении фильтров различного масштаба, что позволяет выявлять как простые элементы изображения (края, углы), так и сложные семантические структуры. Современные архитектуры CNN успешно решают широкий спектр задач - от классификации объектов до сегментации изображений и обнаружения аномалий в медицинской диагностике.
Особенно впечатляющие результаты достигнуты в области компьютерного зрения, где CNN демонстрируют способность к обобщению и устойчивость к различным искажениям входных данных. Развитие этой технологии открывает новые перспективы в создании систем искусственного интеллекта, способных взаимодействовать с окружающим миром на качественно новом уровне, включая разработку передовых нейроинтерфейсов.
В области нейросетевых архитектур, сверточные сети (CNN) выделяются как особый тип многослойных перцептронов. Отличительной чертой этих сетей является полносвязный принцип организации, при котором каждый элемент одного уровня связан со всеми элементами следующего. Подобная организация обеспечивает высокую производительность, но также может вести к избыточной адаптации модели к обучающим данным. Тем не менее, CNN обладают механизмами, позволяющими минимизировать риск такой избыточной адаптации. Среди них можно выделить динамическую корректировку параметров в процессе обучения (например, весовых коэффициентов), а также деактивацию нейронов с низким вкладом, что достигается пропуском связей или включением специальных слоев, реализующих прореживание. Для снижения сложности обрабатываемых данных и акцентирования внимания на ключевых характеристиках, в CNN применяются фильтры.
Альтернативное описание обходных слоев
В первую очередь, при работе с CNN, модель настраивается на прием входных данных, представленных в виде тензора размерностью 𝑁× 𝑀 × 𝑃 × 𝑟. Здесь 𝑁 соответствует числу входных образцов, 𝑀и 𝑃 определяют пространственные размеры (высоту и ширину), а 𝑟 указывает на количество каналов (к примеру, уровни серого). Далее, эти данные подвергаются обработке в сверточном слое, в результате чего формируется набор карт признаков, иногда называемый картами активации. Эти карты имеют размерность 𝑥 × 𝑦× 𝑧 × 𝑠, где 𝑥 обозначает количество элементов, 𝑦и 𝑧 – пространственные размеры карты признаков (высоту и ширину), а 𝑠 отражает характеристики каналов карты.
Сверточный слой, являющийся неотъемлемой частью CNN, обычно характеризуется следующими особенностями:
В сверточных операциях используются фильтры, определяемые параметрами ширины и высоты, которые можно назвать структурными параметрами. Наряду с ними, существуют управляющие параметры, задающие количество каналов на входе и выходе. Число выходных каналов входного слоя определяет глубину всей сети.
На процесс свертки также оказывают влияние такие параметры как дополнение краев, величина смещения фильтра и коэффициент его расширения.
Сверточные слои преобразуют входной сигнал и передают его на последующие уровни обработки. Такой механизм особенно полезен при работе с данными большого объема, такими как видеоряд или изображения с высоким разрешением. В задачах, связанных с изображениями, как правило, задействуется большое количество нейронов. Так, для полносвязного слоя, обрабатывающего изображение размером всего 100 x 100 пикселей, потребуется около 10 000 весовых коэффициентов для каждого нейрона на следующем уровне. Механизм свертки позволяет значительно уменьшить количество независимых параметров, что открывает возможность создания нейронных сетей большей глубины.
Применение единых весов помогает нивелировать эффекты затухающих и резко возрастающих градиентов, способных нарушить функционирование всей сети при обратном распространении ошибки в классических нейронных сетях. Важно отметить, что в ходе сверточной операции также анализируются пространственные отношения между различными элементами изображения.
Слой объединения
Слои объединения служат для уменьшения размерности обрабатываемых данных. Достигается это за счет слияния выходных значений кластеризованных нейронов предыдущего уровня в единственный нейрон на следующем. Возможно также применение локального объединения, при котором обрабатываются небольшие группы данных. В таких слоях обычно применяются фильтры размером 2 x 2. При глобальном же объединении задействуются все нейроны карты признаков.
Данный процесс, также именуемый пулингом, может осуществляться по принципу выбора максимального значения (максимальный пулинг) или усреднения (усредненный пулинг). В первом случае из области, покрываемой фильтром, выбирается наибольшее значение, во втором - вычисляется среднее арифметическое всех значений в этой области.
Полносвязный уровень
Как было определено ранее, функция полносвязного уровня заключается в установлении связей между каждым нейроном на входе и всеми нейронами на выходе. Такой подход обеспечивает возможность обмена информацией и характеристиками между всеми нейронами в сети, что приводит к дифференцированному обучению, когда одни нейроны усваивают информацию лучше других. Этот механизм позволяет в дальнейшем исключать малоинформативные нейроны.
Веса связей
После подачи входного сигнала в нейросеть, каждый нейрон приступает к вычислению выходного значения, основываясь на заданной функции. Каждое соединение между нейронами характеризуется определенным числовым значением, именуемым весом. Ввиду наличия множества связей, весовые коэффициенты удобно представлять в виде матрицы. Кроме того, в модель вводится параметр смещения.
В упрощенном виде связь между входом и выходом сети можно описать следующим образом:
𝑦= 𝑤 ∗ 𝑥 + 𝑏
где 𝑥, 𝑦 - входные и выходные данные, 𝑤- матрица весов, а 𝑏- смещение
Набор весов и значение смещения в рамках сети функционируют подобно фильтру, причем один и тот же фильтр может использоваться несколькими нейронами, что позволяет оптимизировать использование памяти. Однако, в некоторых случаях, для различных сенсорных объектов требуется применение индивидуальных фильтров весов и смещения.
Ограниченная область взаимодействия в сверточных сетях
При работе с нейросетями, особенно при анализе изображений, возникает проблема, связанная с большим количеством входных данных. Каждый пиксель изображения представляет собой отдельный вход, и соединение каждого нейрона со всеми входами становится непрактичным. Сверточные нейронные сети (CNN) решают эту проблему, анализируя не все изображение сразу, а фокусируясь на локальных областях. Они выявляют закономерности в расположении соседних пикселей, определяя таким образом наиболее информативные участки. Этот принцип локальности отражается в весовых коэффициентах, и каждый нейрон "отвечает" за обработку определенного фрагмента изображения.
Конфигурация выходного слоя
Размерность выходного слоя в CNNопределяется тремя ключевыми параметрами: глубиной, шагом смещения фильтра и величиной дополнения границ.
Глубина определяет количество нейронов, анализирующих одну и ту же область входного изображения. Это позволяет выявлять различные характеристики в пределах одной области. Например, некоторые нейроны могут быть настроены на выявление контуров, а другие - на распознавание цветовых паттернов.
Шаг смещения фильтра (Stride) регулирует его перемещение по изображению. При шаге, равном 1, фильтр сдвигается на один пиксель за итерацию, что приводит к перекрытию анализируемых областей. Для исключения перекрытия, шаг обычно устанавливается равным 3 или более.
В некоторых случаях целесообразно дополнять края изображения, например, нулями. Величина этого дополнения (padding) является третьим параметром. Альтернативой нулевому дополнению является дублирование значений граничных пикселей, известное как "одинаковое" дополнение.
Формула для расчета размерности выходного слоя:
где W - размер входного объема, K - размер рецептивного поля нейронов, S- шаг, а P- размер заполнения.
Активационная функция ReLU
Функция активации ReLU (Rectified Linear Unit) применяется для "выпрямления" линейных значений. Она преобразует все отрицательные входные значения в ноль, оставляя положительные без изменений. Формально ее можно описать как:
f(x) = max(0, x)
Введение этой функции привносит нелинейность в процесс принятия решений сетью, не затрагивая при этом области восприятия сверточных слоев. Для этой задачи могут использоваться и другие функции, например:
Гиперболический тангенс: f(x) = tanh(x)
Сигмоида: f(x) = 1 / (1 + e-x)
Финальный классификационный слой
Последний слой сети отвечает за окончательную классификацию. Активация в этом слое рассчитывается через аффинное преобразование, которое включает в себя матричное умножение и последующую корректировку смещения (прибавление вектора, представляющего собой фиксированное или вычисленное смещение).
Определение числа фильтров
По мере увеличения глубины сети, размерность карт признаков, как правило, уменьшается. На начальных слоях используется сравнительно немного фильтров, но их количество может возрастать на более глубоких уровнях. Необходимо поддерживать баланс вычислительной нагрузки между фильтрами, стремясь к тому, чтобы произведение значений признаков по координатам пикселей оставалось неизменным на всех уровнях.
Важно обеспечить, чтобы суммарное количество активаций не снижалось при переходе от одного слоя к другому.
Выбор размера фильтра
Размер фильтра определяется характеристиками набора данных и особенностями его структуры. Некорректный выбор размера может привести к проблеме переполнения. В стандартных архитектурах CNN для операции максимальной подвыборки (max pooling) обычно используется фильтр размером 2x2 с шагом смещения 2. Это позволяет уменьшить размерность данных, повышая тем самым эффективность вычислений.
Анализ существующих подходов
Для полного охвата динамического диапазона яркости сцены требуется разработка специальных методов, аналогичных мультиплексированию экспозиции. В случае статичных сцен такой проблемы не возникает, поскольку изображение одно. Однако при съемке динамичных сцен необходимы специальные алгоритмы для корректной настройки экспозиции. Существуют различные подходы к решению этой задачи, включая использование нескольких сенсоров, адаптивную экспозицию на уровне пикселей и алгоритмы управления коэффициентом усиления.
Недостатками данных систем являются их сложность, необходимость специального изготовления, трудности калибровки под конкретную сцену, а также увеличение объема данных, связанное с ростом разрешения.
Методы восстановления расширенного динамического диапазона
Разработан ряд методов, направленных на восстановление изображений с высоким динамическим диапазоном (HDR) на основе преобразований с использованием различных функций. Результаты этих преобразований сильно варьируются по качеству. Например, предложено осуществлять глобальное преобразование пикселей, задействуя больше исходных данных. Существуют решения, основанные на линейном масштабировании, а также исследования нелинейных методов. Однако, данные подходы не позволяют полностью устранить потерю информации и отдельных пикселей на изображении.
Другой подход к генерации HDR-изображений основан на реконструкции пикселей методом попарного сжатия, который был протестирован на HDR-дисплее. Были попытки применить линейное преобразование с акцентом на различные по масштабу области интереса. Сначала применялась линейная функция для линеаризации входного сигнала, а затем выполнялось усиление светлых участков с использованием расширенной карты, построенной по алгоритму медианного сечения. Этот подход применялся для видеообработки с автоматической калибровкой и перекрестно-двусторонней фильтрацией расширенной карты. Использовался и другой тип фильтрации, а именно фильтр Гаусса, для обеспечения работы в реальном времени. Также применялись так называемые полуавтоматические методы, например, разделение изображения на компоненты: рассеянное отражение, зеркальное отражение и источники света. Поскольку человеческое зрение особенно чувствительно к источникам света и зеркальному отражению, основное внимание уделялось именно им, а рассеянное отражение оставалось без изменений
Методы увеличения разрядности представления данных
В системах обработки изображений при оцифровке сигнала, например, при использовании камеры, возникает эффект квантования, который для стандартных 8-битных изображений может приводить к потере деталей. Для борьбы с этим эффектом применяются методы увеличения разрядности, в частности, методы дизеринга. Эти методы основаны на добавлении шума для маскировки артефактов, возникающих из-за ступенчатого изменения яркости.
Другой подход заключается в предварительном применении фильтров нижних частот с последующим использованием алгоритмов квантования для выявления ложных контуров. Также для решения этой задачи применялись и другие методы фильтрации, сохраняющие границы объектов.
Реализация разработанного подхода
Основная цель данного эксперимента - разработать модель, которая предсказывает значения пикселей LDR-изображения, полученного с помощью обычной камеры, и генерирует его пересвеченную версию. Задача состоит в том, чтобы спрогнозировать значение выходного пикселя путем комбинирования предсказанных пикселей и линеаризованного входного изображения. Выходной пиксель будет рассчитываться по следующей формуле:
где 𝐻̂i,c - восстановленный пиксель с индексом i и цветовым каналом c, 𝐷i,c - значение входного пикселя, ŷi,c - логарифмический выход сверточной нейронной сети, а 𝑓-1 - обратная кривая камеры, используемая для преобразования входных данных системы в линейную форму. Здесь можно использовать линейный переход, начинающийся с определенного значения пикселя с заданным пороговым значением пикселя 𝜏 и заканчивающийся максимальным значением пикселя. Он рассчитывается по формуле:
Можно выбрать 𝜏 = 0.95, если входные данные определены в диапазоне [0,1]. Выбор этого значения позволяет нам добиться большей точности в предотвращении образования полос между нормально предсказанными пикселями и окружающими их областями.
Рассмотрим реализацию:
import numpy as np
import tensorflow as tf
from PIL import Image
# --- 1. Определение архитектуры CNN --- # Увеличиваем количество слоев и используем более продвинутые техники
def create_cnn_model(): """
Создает архитектуру сверточной нейронной сети. Используем больше
слоев, меньший шаг (stride) в сверточных слоях, а
также добавляем Batch Normalization для ускорения обучения и
улучшения стабильности.
Returns:
tf.keras.Model: Модель CNN.
""" model = tf.keras.models.Sequential([
# Первый сверточный блок
tf.keras.layers.Conv2D(32, (3, 3), padding='same', input_shape=(256, 256, 3)),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(32, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# Второй сверточный блок
tf.keras.layers.Conv2D(64, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(64, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# Третий сверточный блок
tf.keras.layers.Conv2D(128, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(128, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# Четвертый сверточный блок
tf.keras.layers.Conv2D(256, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(256, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# Пятый сверточный блок
tf.keras.layers.Conv2D(512, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Conv2D(512, (3, 3), padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
# Полносвязная часть
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.Dropout(0.5), # Добавляем Dropout для регуляризации
tf.keras.layers.Dense(256 * 256 * 3), # Выходной слой
tf.keras.layers.Reshape((256, 256, 3)) # Изменяем форму на размерность
# изображения
])
return model
# --- 2. Создание модели и загрузка весов ---
model = create_cnn_model()
try:
model.load_weights('my_cnn_model.h5')
except OSError:
print("Ошибка: Не удалось загрузить веса из 'my_cnn_model.h5'. Убедитесь,
что файл существует и путь к нему указан верно.")
print("Либо обучите модель с помощью функции create_cnn_model и
сохраните веса.")
exit()
# Функция линеаризации
def linearize_image(image, gamma=2.2): """
Линеаризует изображение, применяя обратную гамма-коррекцию.
Args:
image: Входное изображение (массив NumPy).
gamma: Коэффициент гамма-коррекции.
Returns:
Линеаризованное изображение (массив NumPy).
"""
return np.power(image, gamma)
# --- 3. Функции для обработки изображения ---
# Функция обратной кривой камеры (f^-1)
def inverse_camera_curve(pixel_value): """
Пример обратной кривой камеры.
В реальности эта функция должна соответствовать характеристикам камеры,
используемой для создания LDR изображений. """
# Простая линейная функция для примера
return pixel_value
# Функция для расчета alpha def calculate_alpha(ldr_pixel, tau=0.95): """
Вычисляет коэффициент alpha для пикселя.
"""
return max(0, (np.max(ldr_pixel) - tau) / (1 - tau))
# Функция для генерации пересвеченной версии пикселя
def generate_hdr_pixel(ldr_pixel, cnn_output, alpha): """
Генерирует значение HDR пикселя.
"""
return (1 - alpha) * inverse_camera_curve(ldr_pixel) + alpha * np.exp(cnn_output)
# Функция для обработки всего изображения def generate_hdr_image(ldr_image_path, model): """
Генерирует пересвеченную версию LDR изображения.
Args:
ldr_image_path: Путь к LDR изображению.
model: Обученная CNN модель.
Returns:
Пересвеченная версия изображения (HDR) в формате numpy array.
"""
# Загрузка изображения
try:
ldr_image = np.array(Image.open(ldr_image_path)).astype(np.float32) / 255.0
except FileNotFoundError:
print(f"Ошибка: Не удалось открыть изображение '{ldr_image_path}'.
Убедитесь, что файл существует и путь к нему указан верно.")
return None
# Проверка размерности изображения
if ldr_image.shape != (256, 256, 3):
print("Ошибка: Размер изображения должен быть 256x256x3.")
return None
# 1. Линеаризация входного изображения (в данном примере уже
предполагается, что изображение линеаризовано)
linearized_ldr_image = ldr_image
# 2. Получение логарифмического выхода CNN
cnn_output = model.predict(np.expand_dims(linearized_ldr_image, axis=0))[0]
# 3. Расчет HDR изображения
hdr_image = np.zeros_like(ldr_image)
for i in range(ldr_image.shape[0]):
for j in range(ldr_image.shape[1]):
for c in range(ldr_image.shape[2]):
alpha = calculate_alpha(ldr_image[i, j, :])
hdr_image[i, j, c] = generate_hdr_pixel(ldr_image[i, j, c], cnn_output[i,
j, c], alpha)
return hdr_image
# --- 4. Пример использования ---
ldr_image_path = 'path/to/your/ldr/image.jpg'
# Генерация HDR изображения
hdr_image = generate_hdr_image(ldr_image_path, model)
# --- 5. Сохранение или отображение результата ---
if hdr_image is not None:
# Нормализация и преобразование к uint8 для сохранения в обычном
# формате
hdr_image_normalized = np.clip(hdr_image, 0, 1)
hdr_image_uint8 = (hdr_image_normalized * 255).astype(np.uint8)
# Отображение (опционально)
img = Image.fromarray(hdr_image_uint8)
img.show()
# Сохранение результата
output_filename = 'hdr_image.jpg' # Или другой формат, например,
# hdr_image.png
img.save(output_filename)
print(f"Изображение сохранено как {output_filename}")
Результат:
При работе над моделью был выявлен ряд проблем, влияющих на общую производительность:
- Первая проблема заключается в том, что каждое изображение содержит множество мелких текстур, которые невозможно точно предсказать, что может привести к появлению шума на выходном изображении.
- При работе с HDR-изображениями возникает проблема цветового диапазона. Это означает, что при создании HDR-изображения из одного LDR-изображения многие цветовые градиенты исчезнут, что приведет к потере качества выходного изображения.
- Квантование изображения после съемки также приводит к потере деталей, что снижает разрешение выходного изображения.
Визуализация и обработка динамического диапазона в изображениях
Разница в динамическом диапазоне между изображениями LDR (низкий динамический диапазон) и HDR (высокий динамический диапазон) существенна. Анализ гистограмм яркостей этих изображений подтверждает данное утверждение. В случае LDR-изображений, распределение значений яркости пикселей близко к равномерному, за исключением пиковых значений, которые, как правило, соответствуют шумам. HDR-изображения, напротив, демонстрируют плавное убывание количества пикселей с ростом яркости, напоминающее экспоненциальный спад, при этом доля пикселей с максимальной яркостью (насыщенных) относительно невелика.
Гистограммы двух наборов данных LDR-изображений по сравнению с предварительно обработанным набором данных HDR. Как мы видим, вероятность имеет большое увеличение вблизи 1, что означает насыщенную информацию. Изображение HDR также имеет информацию о насыщенности, представленную в хвосте убывающей частоты.
Подготовка и настройка процесса обучения
Для эффективного обучения нейронной сети важна правильная инициализация весов. Использование нулевых начальных значений может существенно замедлить процесс обучения. Поэтому в данной работе было решено использовать предобученные веса сети VGG16, которая продемонстрировала высокую эффективность в задачах классификации изображений. В качестве оптимизатора был выбран алгоритм ADAM со скоростью обучения 5e-5. Функция потерь, минимизируемая в процессе обучения, определяется следующим образом:
где:
N - общее количество пикселей;
I_i и Î_i - интенсивность i-го пикселя соответственно для исходного LDR и предсказанного HDR изображения;
R_(i,c) и Ȓ_(i,c) - коэффициент отражения i-го пикселя в канале c для исходного LDR и предсказанного HDR изображения;
α_i - весовой коэффициент для i-го пикселя;
λ - параметр, регулирующий баланс между яркостью и цветом.
Для обработки нулевых значений интенсивности в исходном изображении используется сдвиг на малую величину 𝜖: I_i = log(H_i + 𝜖). Разложение изображения на интенсивность (I) и коэффициент отражения (R) выполняется по формуле: H_(i,c) = I_i * R_(i,c).
Подготовка обучающих данных и предварительное обучение
В связи с ограниченным доступом к HDR-данным, обучение модели проводилось на специально подготовленном наборе. Для отбора изображений, подходящих для обучения, был проведен анализ гистограмм. Изображения, в которых менее 50/256 пикселей имели максимальное значение яркости (то есть были близки к насыщению), были отобраны для обучения. Размер изображений был установлен равным 224x224 пикселя без изменения исходного разрешения. В процессе обучения использовался оптимизатор ADAM со скоростью обучения 2e-5 и размером патча 4.
Реализация обучения:
import os
import numpy as np from PIL import Image
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Input, Dense, Reshape
from tensorflow.keras.models import Model
# --- Параметры ---
IMAGE_SIZE = (224, 224)
BATCH_SIZE = 4
LEARNING_RATE = 2e-5
THRESHOLD_SATURATED_PIXELS = 50 / 256
DATA_DIR = 'path/to/your/ldr/images' # Путь к директории с LDR изображениями
MODEL_WEIGHTS_PATH = 'my_cnn_model.h5'
# --- Функция для анализа гистограммы и отбора изображений --- def is_image_suitable(image_path,threshold=THRESHOLD_SATURATED_PIXELS):
"""
Проверяет, подходит ли изображение для обучения на основе анализа
гистограммы.
Args:
image_path: Путь к изображению.
threshold: Пороговое значение доли насыщенных пикселей.
Returns:
True, если изображение подходит, иначе False. """
try:
img = Image.open(image_path)
# Рассчитываем гистограмму для каждого канала
histograms = [np.histogram(np.array(img.getchannel(c)), bins=256, range=(0,
256))[0] for c in range(3)]
# Объединяем гистограммы
histogram = np.sum(histograms, axis=0)
# Считаем количество пикселей с максимальной яркостью (255)
saturated_pixels = histogram[-1]
# Проверяем, не превышает ли доля насыщенных пикселей порог
return (saturated_pixels / np.prod(img.size)) < threshold
except Exception as e:
print(f"Ошибка при обработке изображения {image_path}: {e}")
return False
# --- Функция для загрузки и предобработки изображения ---
def load_and_preprocess_image(image_path): """
Загружает и предобрабатывает изображение для подачи в модель.
Args:
image_path: Путь к изображению.
Returns:
Предобработанное изображение (numpy array) или None, если
произошла ошибка. """
try:
img = Image.open(image_path)
# Изменяем размер на 224x224
img= img.resize(IMAGE_SIZE)
# Преобразуем в numpy arrayи нормализуем
img_array = np.array(img).astype(np.float32) / 255.0
return img_array
except Exception as e:
print(f"Ошибка при загрузке изображения {image_path}: {e}")
return None
# --- Функция для создания модели с предобученными весами VGG16 ---
def create_model_with_vgg16_weights(): """
Создает модель с предобученными весами VGG16.
Returns:
tf.keras.Model: Модель с предобученными весами. """
# Загружаем VGG16 без полносвязных слоев (include_top=False)
vgg16 = VGG16(weights='imagenet', include_top=False, input_shape=
(*IMAGE_SIZE, 3))
# Замораживаем веса VGG16
for layer in vgg16.layers:
layer.trainable = False
# Добавляем свои полносвязные слои
x = vgg16.output
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(1024, activation='relu')(x)
x = tf.keras.layers.Dense(np.prod(IMAGE_SIZE) * 3)(x)
output = Reshape((*IMAGE_SIZE, 3))(x)
# Создаем модель
model = Model(inputs=vgg16.input, outputs=output)
return model
# --- Подготовка списка подходящих изображений ---
suitable_image_paths = []
for filename in os.listdir(DATA_DIR):
if filename.lower().endswith(('.png', '.jpg', '.jpeg')): # Проверяем расширение
# файл
image_path = os.path.join(DATA_DIR, filename)
if is_image_suitable(image_path):
suitable_image_paths.append(image_path)
print(f"Найдено {len(suitable_image_paths)} подходящих изображений.")
# --- Генератор данных --- def data_generator(image_paths, batch_size): """
Генератор данных для обучения модели.
Args:
image_paths: Список путей к изображениям.
batch_size: Размер пакета.
Yields:
Пакет входных данных (батч предобработанных изображений). """
while True:
batch_images = []
for image_path in image_paths:
image = load_and_preprocess_image(image_path)
if image is not None:
batch_images.append(image)
if len(batch_images) == batch_size:
yield np.array(batch_images)
batch_images = []
# Если остались необработанные изображения
if batch_images:
yield np.array(batch_images)
# --- Создание модели и компиляция ---
model = create_model_with_vgg16_weights()
optimizer = Adam(learning_rate=LEARNING_RATE)
# Заглушка для функции потерь, т.к. точная реализация в тексте не приведена def custom_loss(y_true, y_pred):
"""
Пример кастомной функции потерь.
где: N - общее количество пикселей;
I_i и Î_i - интенсивность i-го пикселя соответственно для исходного LDR
и предсказанного HDR изображения;
R_(i,c) и Ȓ_(i,c) - коэффициент отражения i-го пикселя в канале c для
исходного LDR и предсказанного HDR изображения;
α_i - весовой коэффициент для i-го пикселя;
λ - параметр, регулирующий баланс между яркостью и цветом
Для обработки нулевых значений интенсивности в исходном изображении
используется сдвиг на малую величину 𝜖: I_i = log(H_i + 𝜖). Разложение
изображения на интенсивность (I) и коэффициент отражения (R) выполняется
по формуле: H_(i,c) = I_i * R_(i,c). """
return tf.reduce_mean(tf.square(y_true - y_pred))
model.compile(optimizer=optimizer, loss=custom_loss)
# --- Обучение модели ---
# Используем генератор данных для обучения
train_generator = data_generator(suitable_image_paths, BATCH_SIZE)
# Рассчитываем количество шагов в эпохе
steps_per_epoch = len(suitable_image_paths) // BATCH_SIZE
# Запускаем обучение (предварительное обучение)
model.fit(train_generator, steps_per_epoch=steps_per_epoch, epochs=5)
# --- Сохранение весов модели ---
model.save_weights(MODEL_WEIGHTS_PATH)
print(f"Веса модели сохранены в {MODEL_WEIGHTS_PATH}")
Результаты
В рамках данного эксперимента была проведена оценка эффективности системы, предназначенной для восстановления изображений с широким динамическим диапазоном (HDR). Для тестирования использовался набор из 95 HDR-изображений, приведенных к разрешению 1024x768 пикселей. Изначально, базовая архитектура сверточной нейронной сети (CNN) демонстрировала приемлемый уровень ошибок, однако внедрение механизма пропускных соединений позволило снизить среднюю квадратичную ошибку (MSE) на 24% и заметно улучшить детализацию результирующих изображений. Для более детального анализа, в таблице ниже представлены значения MSE, полученные при использовании различных методов реконструкции. Строки таблицы соответствуют различным подходам к восстановлению, а столбцы отражают ошибки, рассчитанные по разным метрикам: "Общая ошибка" – это MSE между исходным LDR и восстановленным HDR изображением; "Ошибка I/R" учитывает разложение изображения на компоненты интенсивности (I) и коэффициента отражения (R); "Ошибка по I" и "Ошибка по R" - это ошибки, посчитанные отдельно для компонент интенсивности и отражения.
Сравнительный анализ данных таблицы показывает, что применение специализированной функции потерь, учитывающей разделение изображения на составляющие I и R, дает существенный прирост качества по сравнению с использованием стандартной функции потерь и базовой CNN. Более того, комбинация предобученных весов и специализированной функции потерь обеспечивает наилучший результат среди рассмотренных методов. Примечательно, что "Референсный метод", представляющий, по всей видимости, некий альтернативный алгоритм реконструкции, демонстрирует высокие значения ошибок в первых трех столбцах, что может быть связано с иной методологией обработки компонент I/R или использованием отличной от MSE метрики в этих компонентах. В то же время, низкое значение ошибки по R для "Референсного метода" может указывать на его высокую эффективность в восстановлении именно коэффициента отражения. Анализ значений в столбцах также позволяет заключить, что компонента интенсивности вносит наибольший вклад в общую ошибку, и именно ее оптимизация является ключевым фактором улучшения производительности в методах, основанных на специализированной функции потерь, учитывающей I/R разложение.
Как видно, автоэнкодер смог восстановить высокую яркость.
Влияние количества эпох обучения:
В ходе исследования был проведен эксперимент с целью изучения влияния количества итераций обучения на производительность нейросетевой модели. Известно, что сокращение числа итераций ведёт к уменьшению времени, затрачиваемого на обучение, и снижению нагрузки на вычислительные ресурсы. В базовом варианте модель проходила обучение в течение 10 итераций. При сокращении этого числа до 5 было зафиксировано повышение скорости обработки данных на 30%. Результаты данного эксперимента, выраженные в значениях среднеквадратичной ошибки (MSE), представлены в таблице:
Как видно из таблицы, уменьшение количества итераций обучения привело к росту ошибки MSE приблизительно на 25%. Это свидетельствует о том, что для достижения оптимальной точности модели требуется большее количество циклов обучения. Однако следует учитывать, что неограниченное увеличение числа итераций не представляется возможным, так как это может привести к эффекту "переобучения". В таком случае модель чрезмерно адаптируется к обучающему набору данных, теряя способность к обобщению и корректной работе с новыми данными. Кроме того, чрезмерное количество итераций приводит к экспоненциальному росту требований к объему памяти и неприемлемому увеличению времени, необходимого для завершения процесса обучения. Таким образом, при обучении нейросетевой модели необходимо находить баланс между количеством итераций, точностью модели и потребляемыми ресурсами, избегая как недостаточного, так и избыточного обучения.
Заключение
Данный эксперимент посвящен разработке инновационного метода программного создания HDR-изображений (High Dynamic Range) с использованием искусственных нейронных сетей, призванного нивелировать ограничения камер мобильных устройств.
В рамках эксперимента был применен комплексный подход, включающий в себя создание карты изображения на основе серии LDR-снимков (Low Dynamic Range) одной и той же статичной сцены, снятых с разной экспозицией. Этот набор данных послужил основой для обучения нейронной сети, способной распознавать и реконструировать широкий динамический диапазон. В дальнейшем обученная модель использовалась для оптимизации параметров изображения, стремясь к корректному воспроизведению цветового пространства и максимально реалистичной передаче сцены. Ключевыми факторами, учитываемыми при разработке и оптимизации алгоритма, являлись: количество итераций обучения, различные стратегии машинного обучения, данные, получаемые непосредственно с сенсоров камеры, а также оптимальное количество исходных снимков с разной экспозицией.
В результате проделанной работы был создан алгоритм, позволяющий генерировать HDR-изображения из обычных LDR-снимков. Как отмечено в исследовании, обученная нейронная сеть эффективно работает с цветовыми диапазонами, освещением, мелкими структурами и краями, обеспечивая хорошее разрешение выходных изображений. Достигнутая точность, по сравнению с реальными HDR-изображениями, отличается максимум на 20%, что является многообещающим результатом. Это подтверждает эффективность предложенного метода и открывает перспективы для его применения в области мобильной фотографии.
Разработанный алгоритм имеет значительный потенциал для улучшения качества фотографий, сделанных на устройства с ограниченными возможностями. Пользователи бюджетных смартфонов смогут получать более детализированные и реалистичные снимки, приближенные по своим характеристикам к профессиональным фотографиям. Это не только повысит удовлетворенность пользователей, но и откроет новые горизонты для творческого самовыражения и документирования окружающего мира.
Достигнутые результаты вносят вклад в решение ряда актуальных задач в области компьютерного зрения, среди которых: совершенствование алгоритмов машинного обучения для повышения точности распознавания объектов, улучшение обобщающей способности моделей для адаптации к различным условиям съемки, восстановление и компенсация потерь, вызванных квантованием, а также реконструкция HDR-изображений из LDR. Кроме того, данная работа демонстрирует возможность создания систем для генерации HDR-изображений на устройствах с ограниченной вычислительной мощностью, что расширяет доступность HDR-технологий для широкого круга пользователей.
В целом, данный эксперимент демонстрирует перспективность применения искусственных нейронных сетей для решения проблемы ограниченного динамического диапазона в мобильной фотографии. Разработанный алгоритм является значимым шагом на пути к созданию высококачественных HDR-изображений, доступных каждому, и открывает новые возможности для развития технологий обработки изображений в будущем.
Список литературы
- К. Дебаттиста, П. Ледда, Ф. Бантерле. Расширение видео с низким динамическим диапазоном для высокого динамического диапазона. SCCG, 2008.
- Калле, Ф. Дюфо, Р.К. Мантиюк, М. Мрак (Ред.). Видео с высоким динамическим диапазоном. Academic Press, 2016.
- Дж. Ллач, С. Бхагавати, Дж. Ф. Чжай. Многомасштабное вероятностное дизеринг для подавления артефактов полос в цифровых изображениях. IEEE International Conference, 2007.
- Й. Денг, Ч. Донг, Ч. Ченг Л., Х. Танг. Уменьшение артефактов сжатия с помощью глубокой сверточной сети. The IEEE International Conference on Computer Vision (ICCV ’15), 2004.
- Х. Фенг, С. Дж. Дейли. Пространственно-временной микродизеринг на основе моделей эквивалентного входного шума зрительной системы. 2003.
- П. Е. Дебевец, Дж. Малик. Восстановление карт яркости с высоким динамическим диапазоном из фотографий. 1997.
- М. Д. Гроссберг, С. К. Наяр. Пространство функций отклика камеры. The IEEE Conference on Computer Vision and Pattern Recognition, 2003.
- М. Хейн, Р. Мантиюк, П. Дидык, Х.П. Зейдель. Улучшение ярких видеоэлементов для HDR-дисплеев. Computer Graphics Forum, 2008.
- Й. Канамори, Й. Эндо, Дж. Митани. Глубокое обратное тональное отображение. ACM Trans. Graph, 2017.
- А. Гилкрист, А. Якобсен. Восприятие светлоты и освещения в мире с одним отражением. 1984.
- Х. Глорот, Й. Бенгио. Понимание сложности обучения глубоких нейронных сетей прямого распространения. The Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS ’10), Vol. 9, 1996.
- Ф. Хусар, Дж. Кабальеро, К. Ледиг, Л. Тейс, А. Каннингем, А. Акоста, А. Эйткен. Фотореалистичное сверхразрешение одиночного изображения с использованием генеративной состязательной сети. arXiv preprint arXiv:1609.04802, 2016.
- И. Гудфеллоу, Дж. Пуже-Абади. Генеративные состязательные сети. In Advances in Neural Information Processing Systems 27, 2014.
- Х. Чжан, С. Рен, К. Хе, Дж. Сан. Глубокое остаточное обучение для распознавания изображений. 2016.
- Г. Е. Хинтон, Р. Р. Салахутдинов. Уменьшение размерности данных с помощью нейронных сетей. Science 313, 2006.
- С. Иоффе, К. Сегеди. Пакетная нормализация: ускорение обучения глубокой сети за счет уменьшения внутреннего сдвига ковариат. 2016.
- С. Дж. Дейли, Х. Фенг. Деконтурирование: предотвращение и устранение ложных контурных артефактов. Proceedings of SPIE, Vol. 5292, 2004.