Apache Kafka — это распределенная платформа для потоковой передачи данных, которая сочетает высокую производительность, отказоустойчивость и гибкость. Используется для обмена сообщениями, потоковой обработки данных и построения систем реального времени.
В этой статье мы разберем основные концепции Kafka: брокеры, топики, партиции, репликации, гарантии доставки, а также такие элементы, как лидер-реплики, фолловеры и In-Sync Реплики (ISR).
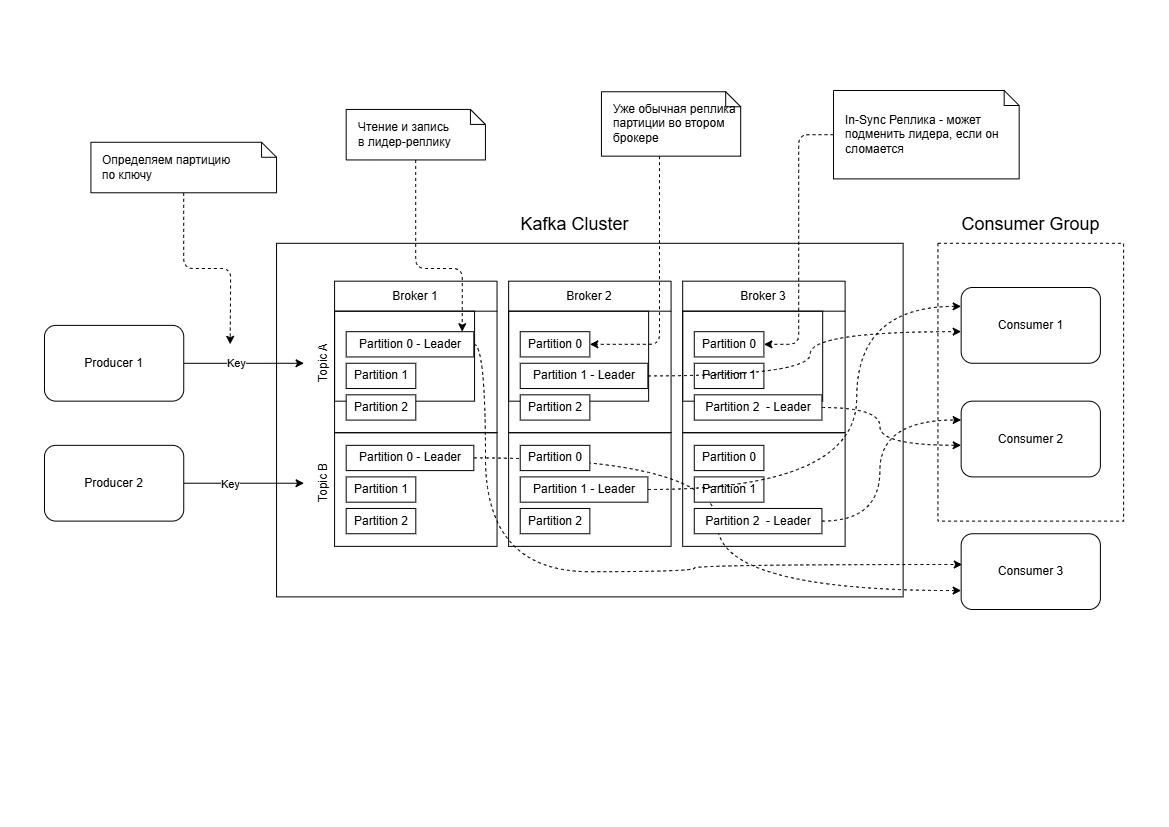
⚙️ Основные компоненты Kafka
1. Брокеры (Brokers)
Брокеры — это серверы, которые хранят и обрабатывают данные Kafka.
- Кластер Kafka состоит из нескольких брокеров, которые работают совместно.
- Каждый брокер управляет определенным набором партиций, что позволяет горизонтально масштабировать систему.
- При сбое одного из брокеров Kafka автоматически переназначает задачи другим брокерам, обеспечивая отказоустойчивость.
2. ZooKeeper и KRaft
Ранее Kafka использовала ZooKeeper для управления метаданными кластера, но в новых версиях внедрен собственный протокол KRaft (Kafka Raft), который исключает зависимость от ZooKeeper.
- ZooKeeper: координирует брокеры и отслеживает состояние кластера.
- KRaft: упрощает управление метаданными и улучшает производительность.
🗂 Топики, партиции и реплики
Топик (Topic)
Топик — это логическое хранилище сообщений.
- Пример: топик orders может использоваться для хранения информации о заказах.
- Сообщения в топике логически упорядочены, но в физическом смысле данные распределены между партициями.
Партиция (Partition)
Каждый топик делится на одну или несколько партиций:
- Партиция обеспечивает горизонтальную масштабируемость.
- Сообщения внутри одной партиции хранятся в строгом порядке, но порядок между партициями не гарантируется.
Репликация (Replication)
Kafka реализует механизм репликации для обеспечения отказоустойчивости:
- Каждая партиция имеет одну лидер-реплику (Leader) и одну или несколько фолловеров (Followers).
- Лидер отвечает за все операции записи и чтения.
- Фолловеры синхронно копируют данные лидера.
In-Sync Реплики (ISR)
ISR — это подмножество реплик, которые находятся в синхронном состоянии с лидером.
- ISR обеспечивает баланс между производительностью и отказоустойчивостью.
- Если реплика не успевает копировать данные, она временно исключается из ISR.
Пример работы репликации:
- Партиция orders-0 имеет 3 реплики:Лидер на Broker 1.
Фолловеры на Broker 2 и Broker 3. - Если Broker 1 выходит из строя, Kafka автоматически выбирает нового лидера из ISR (например, Broker 2).
📦 Гарантии доставки (Delivery Guarantees)
Kafka предлагает три уровня гарантий доставки сообщений:
1. At Most Once (Не более одного раза)
- Сообщение доставляется максимум один раз.
- Возможна потеря сообщений при сбоях.
- Подходит для случаев, где важна скорость, а не надежность.
Пример: Логи событий приложения, где потеря некоторых записей некритична.
2. At Least Once (Как минимум один раз)
- Сообщение доставляется минимум один раз, но возможно дублирование.
- Консьюмеры должны обрабатывать дублирующиеся сообщения.
Пример: Обработка заказов, где потеря данных недопустима, но дублирование можно устранить на уровне приложения.
3. Exactly Once (Ровно один раз)
- Сообщение доставляется строго один раз.
- Требует дополнительных ресурсов, реализуется с помощью транзакций Kafka.
Пример: Финансовые транзакции, где критично избежать потерь или дублирования.
🔢 Офсеты (Offsets)
Офсет — это порядковый номер сообщения внутри партиции.
- Kafka использует офсеты для отслеживания текущей позиции чтения консьюмера.
- Офсеты могут сохраняться:
- Автоматически (по завершению обработки).
- Вручную (консьюмер сам указывает, когда зафиксировать офсет).
⚰️ Мертвые очереди (Dead Letter Queues)
Dead Letter Queue (DLQ) — это топик, в который отправляются сообщения, которые не удалось обработать.
- Используется для отладки и анализа ошибок.
- Консьюмеры могут повторно обработать сообщения из DLQ после исправления ошибок.
Пример: Сообщение с ошибкой десериализации помещается в DLQ для дальнейшего анализа.
🌊 Батчинг vs Стриминг
Батчинг (Batching)
- Сообщения обрабатываются пакетами.
- Уменьшает сетевые издержки.
- Подходит для систем, где небольшая задержка допустима.
Стриминг (Streaming)
- Сообщения обрабатываются по мере поступления.
- Используется для систем реального времени.
🗄 Kafka Schema Registry
Schema Registry управляет схемами данных, которые используются продюсерами и консьюмерами для сериализации/десериализации сообщений.
- Поддерживает форматы Avro, Protobuf, JSON.
- Гарантирует совместимость схем (backward, forward).
Подробнее в статье "Как мы Schema Registry для Kafka настраивали, и что могло пойти не так…" от АльфаСтрахование
💡 Как всё это работает вместе: Пример
- Продюсер отправляет сообщение:Сообщение (orderId=123, amount=100.0) записывается в топик orders.
Kafka выбирает партицию (например, orders-0) и отправляет данные на лидер-реплику (например, Broker 1). - Репликация данных:Лидер реплицирует сообщение фолловерам (Broker 2 и Broker 3).
Сообщение считается зафиксированным, когда все ISR подтверждают запись. - Чтение консьюмером:Консьюмер читает данные из лидера партиции.
После успешной обработки офсет фиксируется, предотвращая повторное чтение. - Сбой брокера:Если Broker 1 выходит из строя, Kafka назначает нового лидера из ISR (например, Broker 2).
- Использование DLQ:Сообщение с ошибкой обработки отправляется в Dead Letter Queue.
📌 Вывод
Apache Kafka — это мощная платформа для работы с потоками данных, которая обеспечивает гибкость и надежность. Механизмы репликации, гарантии доставки и управление офсетами делают Kafka идеальным решением для задач обработки данных в реальном времени.
Если вы разрабатываете систему, где важны высокая доступность, отказоустойчивость и масштабируемость, Kafka станет незаменимым инструментом.