В современном мире технологий большие языковые модели (LLM, Large Language Model) становятся неотъемлемой частью нашей повседневной жизни. Эти сложные системы помогают нам решать задачи, искать информацию и создавать новые идеи. На первый взгляд, их работа может казаться волшебной, но за ней скрывается сложный процесс обработки данных. Сегодня мы подробно разберём, как LLM работают, используя пример простого запроса: «Привет, как дела?».
Первый шаг: преобразование текста в запрос
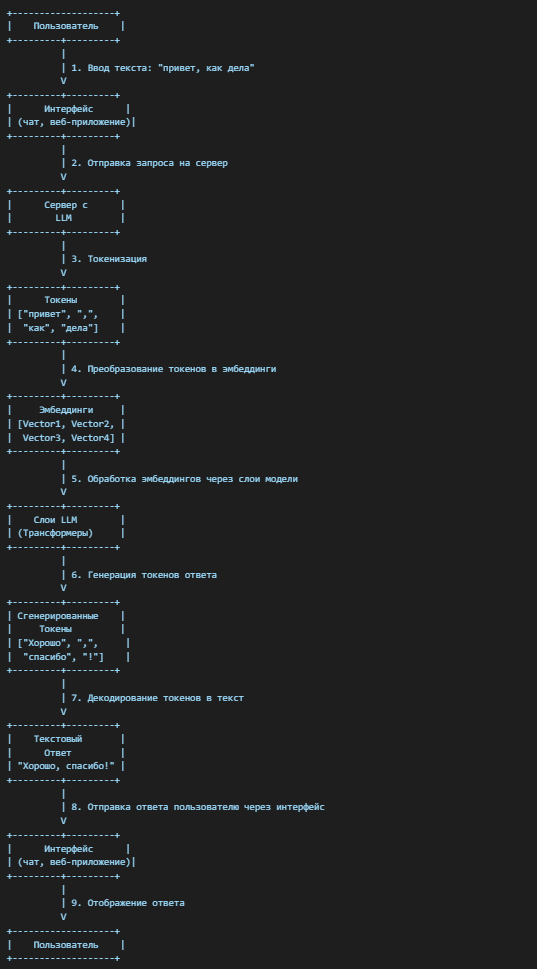
Всё начинается с введённого текста. Пользователь пишет сообщение, например: «Привет, как дела?», в интерфейсе чат-бота или веб-приложения. Когда вы нажимаете кнопку «Отправить», ваш запрос отправляется на сервер, где начинается его обработка. Этот момент можно считать точкой старта, запускающей цепочку из множества этапов, где каждая часть системы выполняет свою задачу.
Токенизация: разбиение текста на части
Первый этап обработки текста — это токенизация. Модель разбивает текст на более мелкие составляющие, которые называются «токены». Например, запрос «Привет, как дела?» превращается в токены: ["привет", ",", "как", "дела"]. Токенизация позволяет системе оперировать текстом как набором базовых элементов.
Этот процесс особенно важен для сложных языков, где значение может зависеть от контекста или структуры фразы. Благодаря токенизации система получает возможность обрабатывать текст гибко, независимо от длины или сложности исходного запроса.
Эмбеддинги: превращение текста в числа
Следующим шагом является преобразование токенов в эмбеддинги. Эмбеддинги — это числовые векторы, которые отражают смысл каждого токена. Например, слово «привет» превращается в многомерный вектор Vector1, а «дела» — в Vector4. Эти векторы учитывают не только значение слов, но и их контекстное окружение.
Эмбеддинги позволяют модели понимать семантические связи между словами. Например, слова «привет» и «здравствуйте» могут быть представлены схожими векторами, что помогает системе интерпретировать запросы с разными формулировками.
Трансформеры: глубокий анализ
На этапе анализа эмбеддинги проходят через слои трансформеров. Трансформеры — это основа работы LLM, которая позволяет им учитывать зависимости между токенами. Каждый слой трансформеров добавляет новую информацию, уточняет смысл и выстраивает связи между словами.
Этот процесс можно сравнить с работой редактора текста, который внимательно изучает каждое слово и его роль в предложении, делая общую картину более чёткой. Чем больше слоёв, тем точнее модель понимает запрос.
Генерация ответа: искусственный интеллект в действии
После завершения анализа модель приступает к генерации ответа. На основе обработанных данных LLM создаёт новые токены, формирующие ответ. Например, запрос «Привет, как дела?» преобразуется в ответ: ["Хорошо", ",", "спасибо", "!"].
Процесс генерации включает в себя подбор наиболее релевантных слов, учёт грамматики и адаптацию под стиль запроса. Это позволяет системе создавать естественные и понятные ответы.
Финальная стадия: декодирование и отправка ответа
Заключительный этап — декодирование токенов в текст. Сгенерированный ответ «Хорошо, спасибо!» возвращается пользователю через интерфейс. Несмотря на сложность всех этапов обработки, весь процесс занимает доли секунды, обеспечивая мгновенную обратную связь.
Почему LLM важны?
Большие языковые модели открывают невероятные возможности. Они не только отвечают на вопросы, но и помогают анализировать данные, создавать контент, обучать пользователей и автоматизировать рутинные задачи. Это делает их универсальными инструментами для бизнеса, науки и повседневной жизни.
Заключение: искусственный интеллект, который понимает вас
Теперь, когда вы знаете, как работает LLM, становится ясно, что за простым ответом скрывается сложная система. Эти модели соединяют сложные технологии с интуитивно понятным взаимодействием, делая искусственный интеллект доступным каждому. Каждое ваше сообщение — это путешествие через мир данных, анализа и генерации, завершающееся понятным и полезным результатом.
